分享一个衍生词库: 由于感觉楼主262万词库和2471万的词库内容包罗万象,过于庞大。于是整理一个更小的词库,大约220万条。
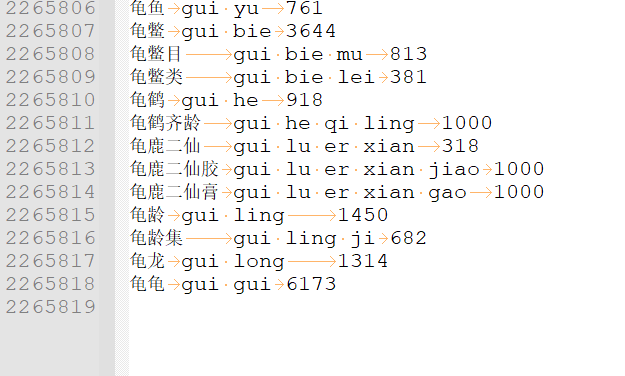
整理方法: 把楼主所发2471万鸿雁拼音原始码表(大约是4.0或5.0版本),和腾讯词库( https://ai.tencent.com/ailab/nlp/zh/embedding.html )最大的那个对撞,取二者交集,整理出一个新的词库。这个词库,其实是2471万鸿雁的子集,词频用的是鸿雁2471万词库的,单字频率则是从262万词库5.0攫取的。
特点: 词库的词条从楼主的2471万词库择取,去除了大量了无理、用处不大的词句,整理后得到大约220万条,感觉词条更为精当;覆盖范围更广、且实用。感觉缺点更少、优点更多,更适合普罗大众。但不知有什么隐藏的缺陷。楼主的发布的词库中也有262万的一个轻量版词库,我这个大约220万,有好事的群友,可以比较下比较评测一下。
下载:
hongyan_pinyin_simp_tengxun.7z (18,0 MB)
文件包里包含:
hongyan_pinyin_simp_tengxun.dict.yaml
hongyan_pinyin_simp_tengxun.schema.yaml
安装:
截图: