注:本文是日本語非辞書形辞典项目的Python版本的说明文档。
在以下网站都有备份:
非mdx也能所划即所得啦_日本語非辞書形辞書_v3_For_Quicker_Demo - 日语 - FreeMdict Forum
v3_For_Quicker_Demo · 语雀 (yuque.com)
前排提示:这个项目是日本語非辞書形辞書_v3 版本的 Demo 产品,可能会遇到不少问题,欢迎留言反馈:)
另外,文档在v3_For_Quicker_Demo · 语雀 (yuque.com)有备份,有问题欢迎通过GitHub或者通过邮箱 NoHeartPen@outlook.com 与我沟通。
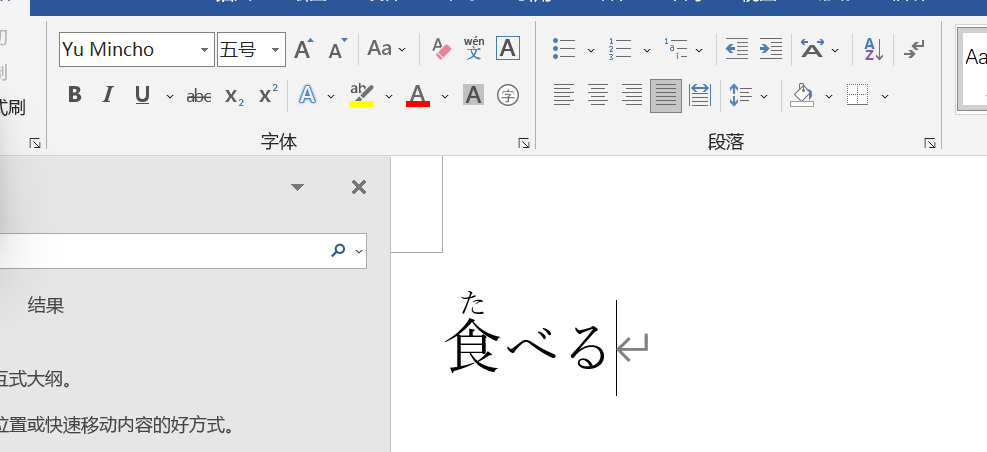
最终效果
直接上图![]()
(实际使用应该没有看起来的这么卡,演示时有停顿)
下载
如果你在GitHub/Gitee的README页面:打开dist文件夹,下载里面的v3_index.txt和main.exe2个文件
如果你不在项目的README页面,请通过下面的方式下载:
蓝奏云:https://wwp.lanzouf.com/b011uva4d 密码:e3h4
注意:
- 最好找个地方专门放,完成设置后,不要随便删也不要随便移动
main.exe和v3_index.txt - 解压路径中最好不要有空格
- 目前需要与Quicker配合使用,直接双击 exe 没有反应是正常的:)
更新说明
2022-11-06
-
跟进v2版本的更新
- 支持
沸きたつ、わき立つ等复合动词的异形词 - 支持一段动词使役态口语约音
食べせる(划食べせ)
- 支持
-
只需通过用言的“非辞書形”即可推导出原型的猜想通过了日语NLP的权威工具的检验:
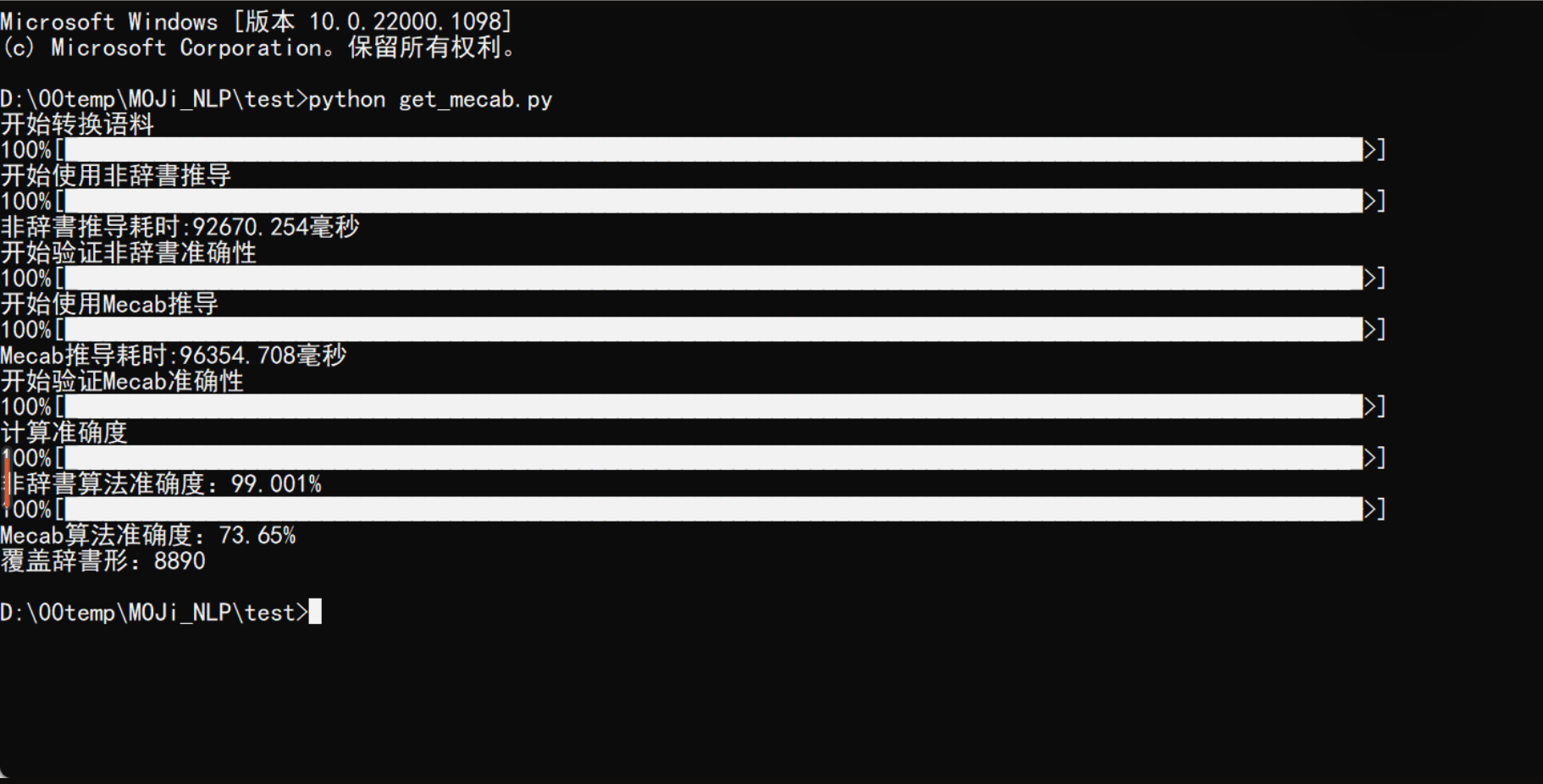
1. 通过 Mecab 对维基百科和青空文库进行分词,获取分词结果中的动词和形容词,然后调用非辞書算法进行验证,v3的 Python 版本的正确率达到了 99%!!!
2. 另外,顺便测试了下在剪贴板查词这样丢失了上下文的情况下,Mecab 推导辞書形的准确率:70%——这个结果并不能否定 Mecab 在日语 NLP界的权威 ,只是再次证明了一点:日语的剪贴板查词不能只返回一个结果(一段动词的连用形一对 Mecab 的干扰真的太大了)。
1. 补充:由于 Mecab 分词后的结果与本项目支持的划词方案略有差异,故测试时只覆盖了分词结果中的部分活用。另外,针对2个工具的特点分别对测试文本做了微调,二者并不是在完全一致的条件下进行测试,无法保证绝对中立客观,测试结果仅供参考
2. 有兴趣复现测试可以到GitHub项目主页的endorse文件下阅读详细内容,
3. 青空文库处理结果:
4. 维基百科处理结果:

本次更新需要同时更新main.exe文件和v3_index.txt文件,Quicker动作不需要更新。
下载地址https://wwp.lanzouf.com/b011uva4d 密码: e3h4,下载后解压覆盖即可
反馈
推荐到GitHub的issue处反馈
https://github.com/NoHeartPen/NonJishoKei/issues/1
也可以填写这个问卷: v3问卷反馈
使用方法
可以和这个上手视频一起看:【日本語非辞書形辞典】沙拉查词XQuicker:所见所划,即为所查
使用本项目前,需要到Quicker 官网,下载安装并注册登录。
注:可以填写我的推荐码:353808-6234,这样我们都可以获得 90 天的专业版时长笑
粘贴动作(必看)
基础设置(必看)
打开 Quicker,粘贴动作,然后右键打开编辑,双击运行脚本
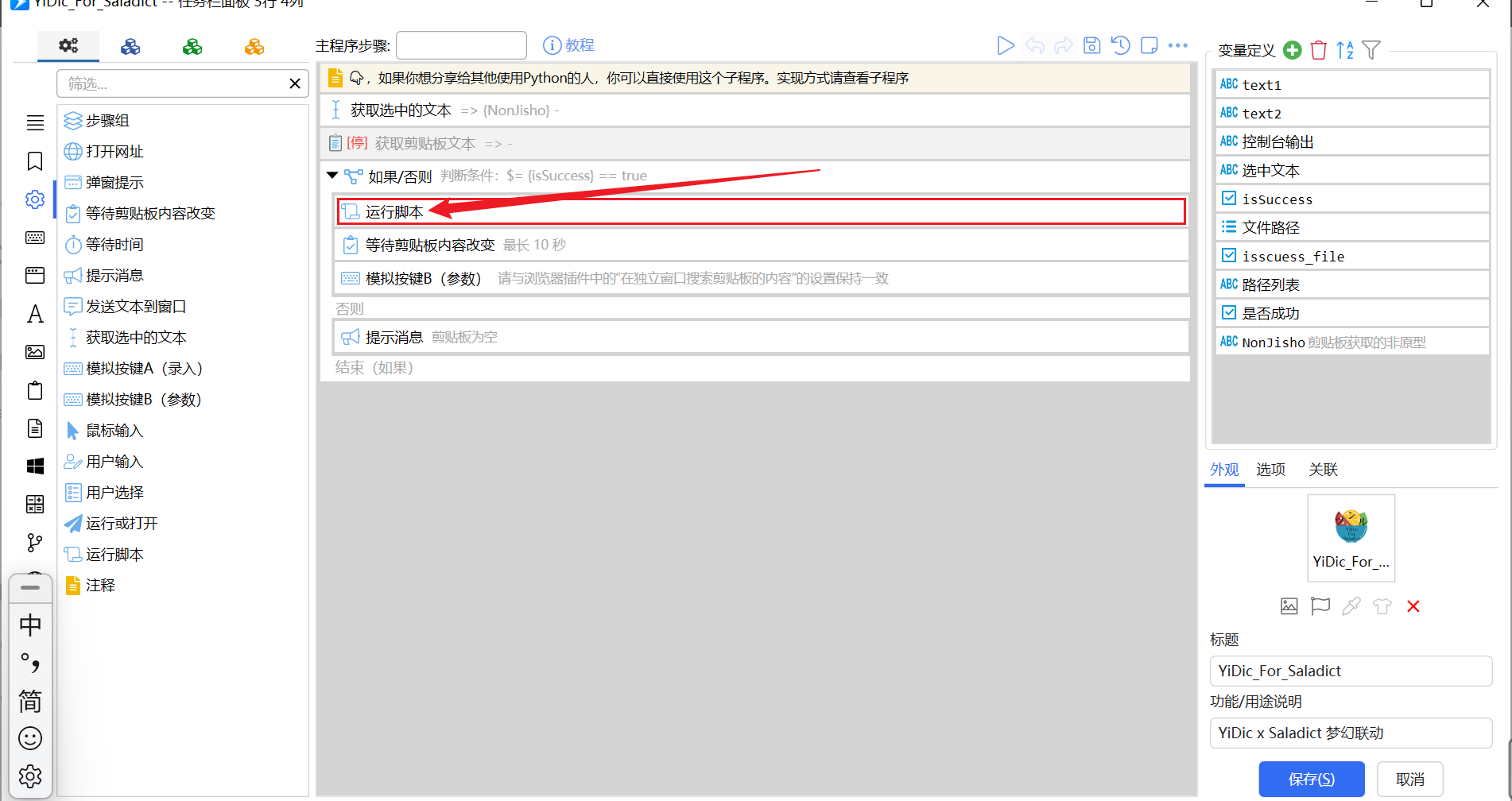
在脚本内容中填入下载的 exe 文件的路径(Win11 的可以通过右键点击然后复制文件路径获取,双引号可以不删)
接着在下面的工作目录填入文件夹的路径,去掉双引号和 main.exe 就可以了。

到这里基本设置就完成了。下面介绍高级选项。
注意,请确认授予沙拉查词读取剪贴板和写入剪贴板的权限(位于扩展选项-权限管理)
沙拉查词 (必看)
如果沙拉词典的在独立窗口搜索剪贴板内容的快捷键不是Alt+C,还需要进行修改。

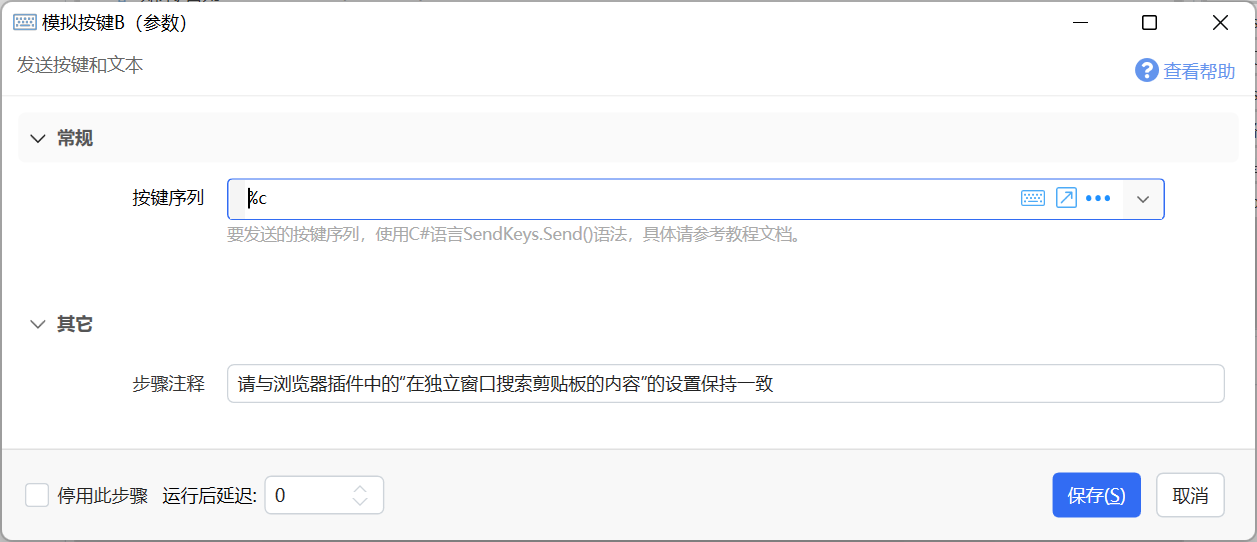
打开编辑页面,模拟按键 B(参数)
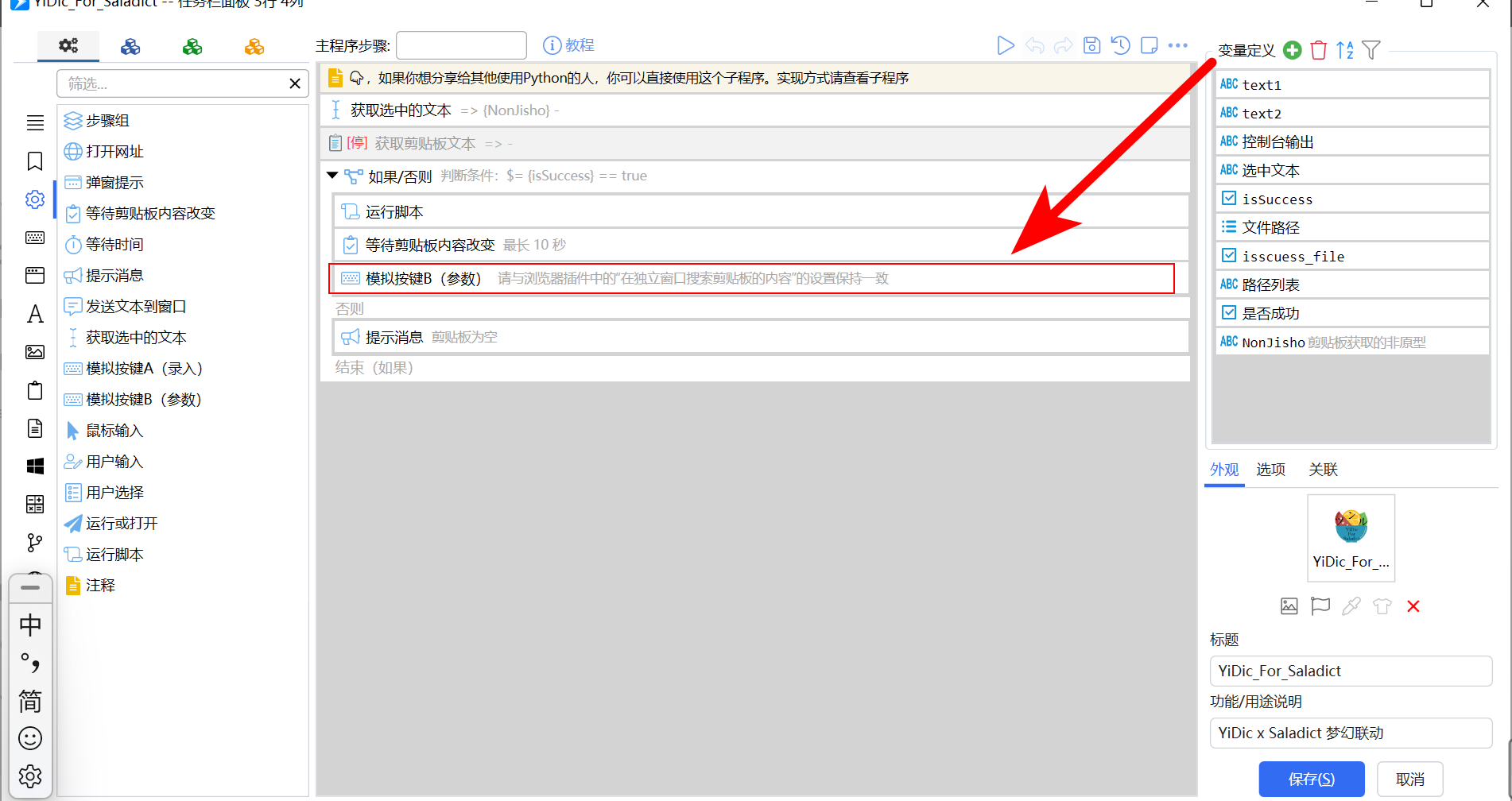
参考快捷键语法,填入你喜欢的快捷键即可
EBWin (非必看)
默认的分享的动作需要自己提前打开 EBWin 才可以用,如果希望每次选中文本后直接启动软件查词,那么还需要另外的设置。
先把电脑上的 EBWin 软件打开,然后打开YiDicForEBWin的编辑界面
双击下面的激活进程主窗口
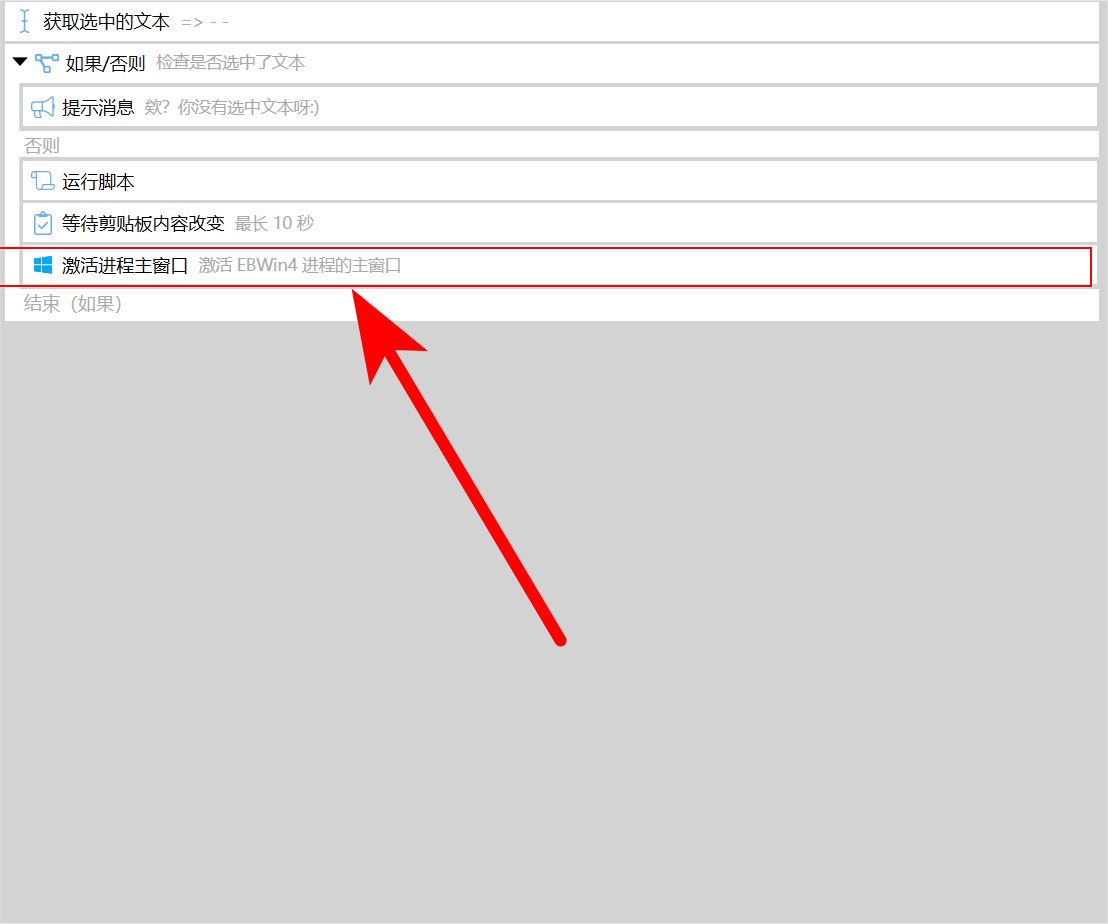
点击下面的红框

会发现切换到了 EBWin 的界面,随便点击 EBWin 顶部状态栏的一个位置
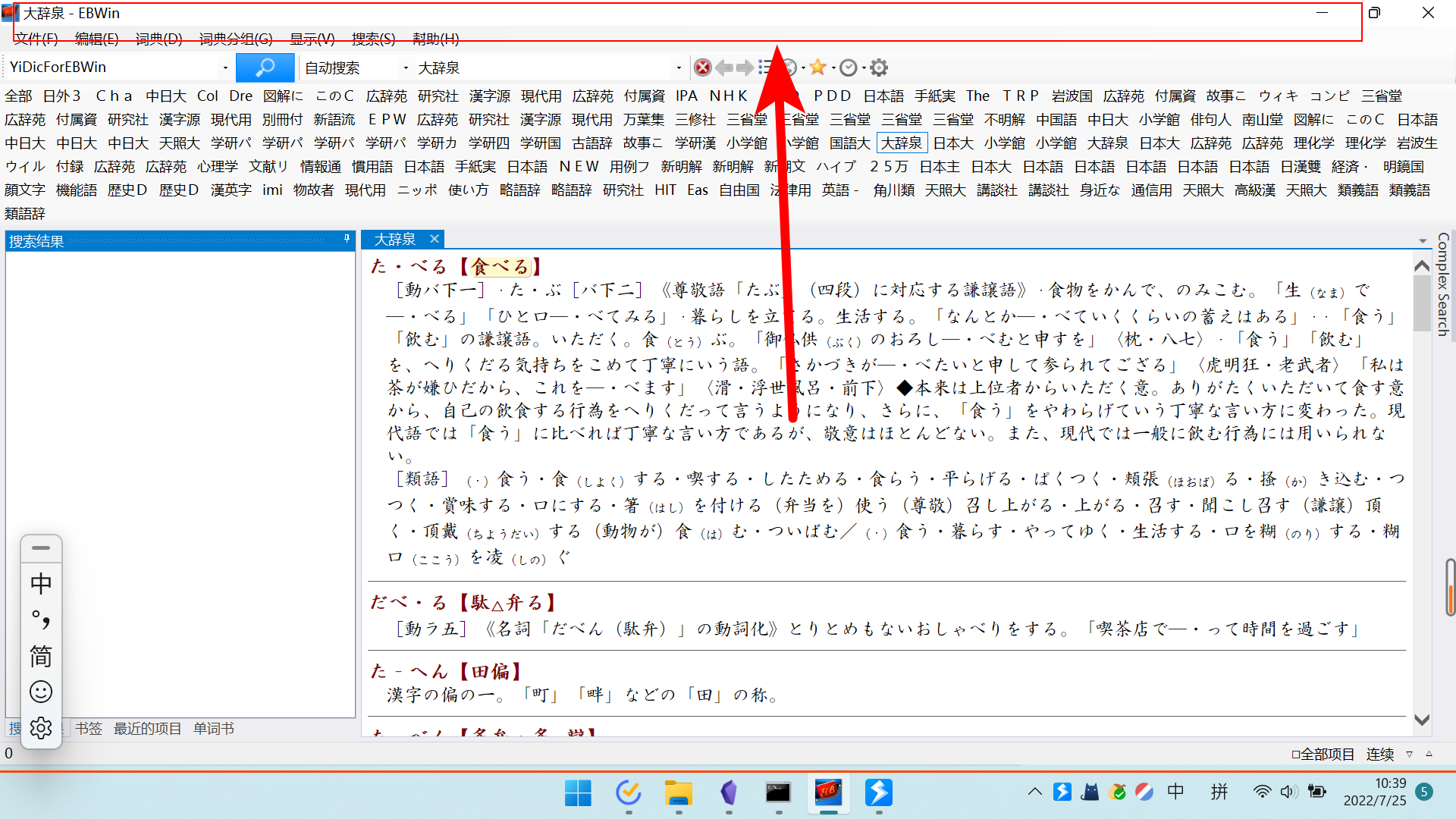
会发现,软件路径就自动填好了
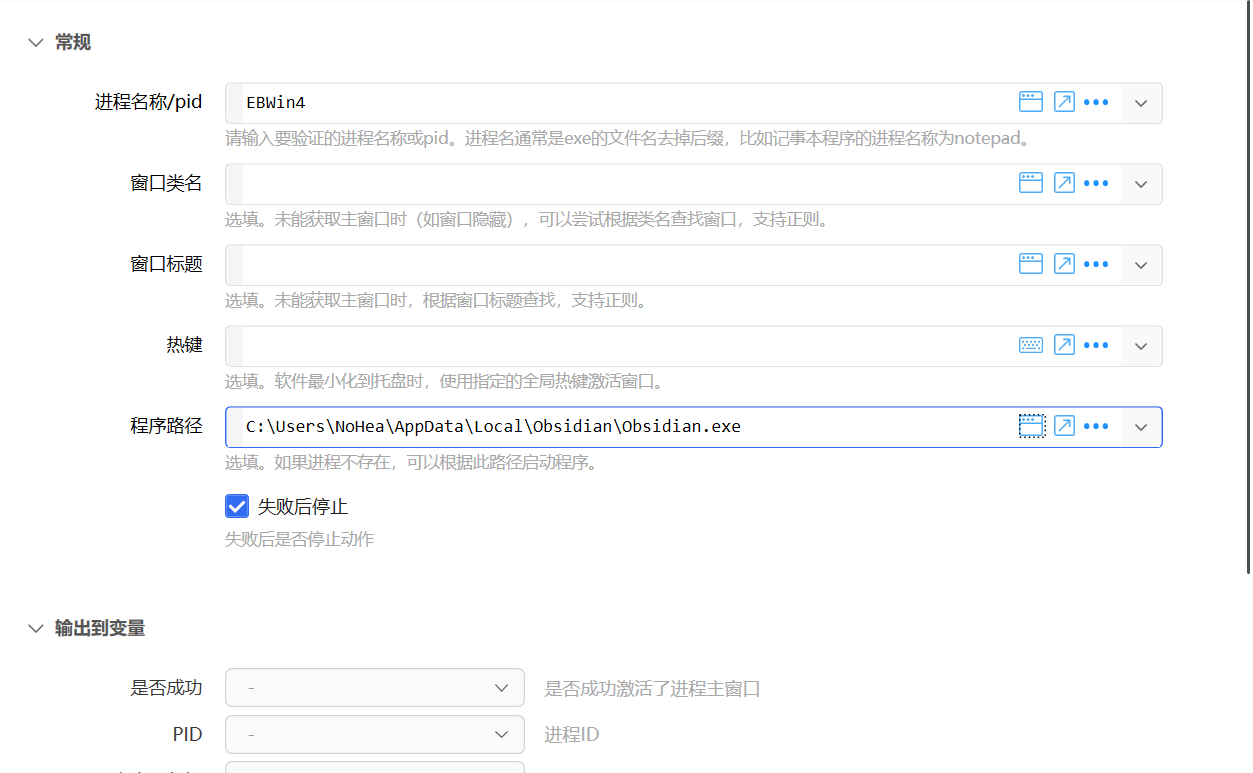
如果上述方法搞不定的话,自己手动填也行。
当然,你也可以根据自己的需要,填入自己喜欢的词典软件,只是这样一来,需要改程序路径和进程名称/pid2 个地方。
Todo
- 正则支持
- 在 MS Word 中或是像
軋(きし)み合(あ)わない这样的句子划词翻译,正则可以直接处理为軋み合わ -
々ゝゞ/\/″\ -
<ruby></ruby>(浏览器内划词)
- 在 MS Word 中或是像
- 支持跨行的划词,常用于扫描版的PDF文件
- 验证算法真实准确度
- 跟进日本語非辞書形辞書_v2
- 0722
- 1033
- 有 Mecab 分词语料的同学欢迎发送到 NoHeartPen@outlook.com ,只需要
書字形和書字形基本形2 列的数据即可,感激不尽:)
- 跟进日本語非辞書形辞書_v2
- ……
欢迎提出其他意见
大致思路
举个例子简单说明下脚本的工作原理,方便大家结合自己的需要修改。
对于ご飯を食べたい这个句子,我们用鼠标选中食べた按下快捷键,Quicker 会将选中的文字复制到剪贴板,然后启动电脑上的main.exe文件,这个 exe 文件会读取剪贴板,获取到最近一次复制的内容,即食べた。
然后程序会读取最右侧的假名即た,根据 v2 版本的词条规律我们可以知道,た出现在词尾假名说明要么是一段动词,要么是五段动词(注:技术细节处会给出这么假设的相关数据)。
我们先假设它是五段动词,然后程序会将た替换为つ,然后在这个v3_index.txt文件中查找有没有食べつ这个动词。
……
找了一圈没有,那说明这个我们的假设是错误的。
然后程序会验证另一种假设:将词尾た替换为る,然后再去v3_index.txt文件中查找食べる,很幸运,这次找到了。
程序会将找到的食べる写入剪贴板,Quicker 检测到剪贴板内容发生变化后就会调起词典软件了(所以你也可以在支持 mdx 的 GoldenDic 上用,享受双倍的快乐)。
另外,v3_index.txt里面保存的原型数量也会影响最终的效果,可以自由向里面添加收集到的单词。
技术细节
可能有人会好奇,最近怎么突然高产了起来开始刷版本号,v2 版本都才出一周多,怎么这么快 v3 版本就来了。
这是因为 v3 版本其实是 v2 版本的逆过程,而且 v3 版本之后的改进在很大程度上取决于 v2 版本的成果,所以先制作了这么一个小工具,供有兴趣的同学折腾。
接下来是正文:
如果有人分析过 v2 版本的源文件,就会注意到穷举出的变形的词尾假名似乎重复率有点高呀,有没有什么规律呢?
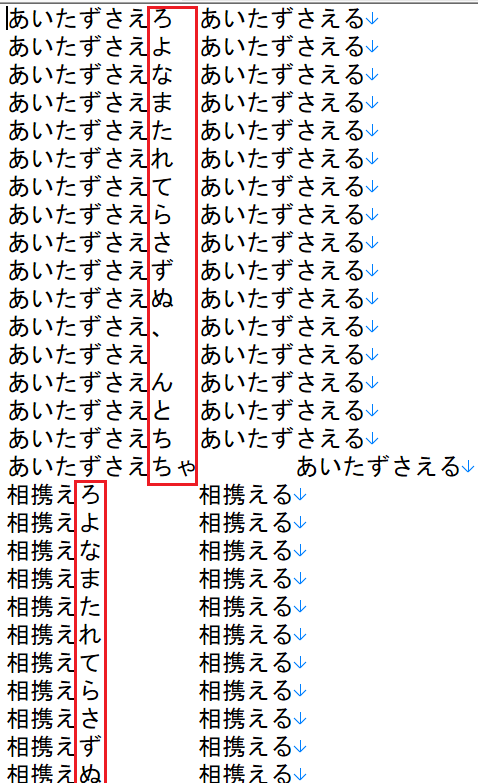
我们把词尾部分都提取出来,整理下得到下面这个表格:

查阅这个表格我们就知道た只能由一段和五段动词产生,但具体是谁我们只能采用笨办法:查原型来判断。

虽然有一半左右的的词尾假名都只有一种来源,但在丢失了上下文的情况下,我们可能都需要进行 3 次替换和 3 次遍历查找,不过好在即使是最差的情况,大多数人的电脑应该也能满足日常的需要。
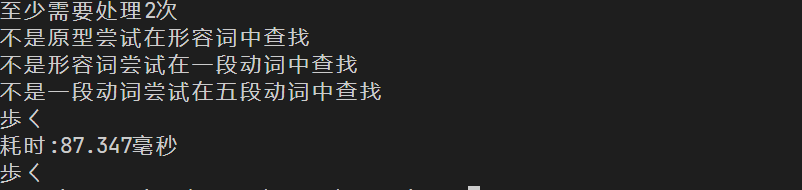
不过,即使把 v2 的 172580 个词条都给查一遍,也只要区区6 分钟

所以这算法也没有那么烂吧……QAQ
最后,手动@MOJi、@沙拉查词、@EBWin、@欧路词典、@Yomichan、@AnkiHelper 等开发者,最强开源日语取词算法的 Python 版本已经托管在 Github 上啦,欢迎 PR 和提交 issue 呀:)
https://github.com/NoHeartPen/JapaneseConjugation
更新历史
2022-09-03
- 鸽了一个月的上手视频【日本語非辞書形辞典】沙拉查词XQuicker:所见所划,即为所查
- 支持 MS Word 的注音或是像
軋(きし)み合(あ)わない这样的句子划词(后台处理为軋み合わ) - 支持所有踊り字标记:
々ゝゞ/\/″\,还原为大多数词典都会收录的形式 - 优化扫描版的PDF文件的查词体验,
- 支持跨行的划词
- 自动删除OCR中经常出现的半角空格
本次更新只需下载main.exe即可,其余文件没有改动。
2022-08-03
- 支持返回多个结果
- 索引文件新增单词
- 提高准确率,v3 版本现在返回的结果与 v2 基本一致啦

本次更新需要同时更新 Quicker 动作和 main.exe、index_v3 文件才可使用
Quicker 动作更新:右键-来源动作-更新即可
main.exe 和 index_v3 文件下载地址https://wwp.lanzouf.com/b011uva4d 密码:e3h4,下载后解压覆盖即可