词源词典分享:

宋维钢曾向学员推荐的几本最好的词源词典之一, Encyclopedia级的体量最大(另外几本分别是牛津、韦氏和钱伯斯)。可惜目前只找到PDF文字版的(下载链接见下),不知能否制作成mdx词典 ![]() @oxford
@oxford
Word and Phrase Origins, 4th Ed.pdf (10.1 MB)
词源词典分享:
宋维钢曾向学员推荐的几本最好的词源词典之一, Encyclopedia级的体量最大(另外几本分别是牛津、韦氏和钱伯斯)。可惜目前只找到PDF文字版的(下载链接见下),不知能否制作成mdx词典 ![]() @oxford
@oxford
Word and Phrase Origins, 4th Ed.pdf (10.1 MB)
![]() 如果能提取内容的话应该可以
如果能提取内容的话应该可以
我不太懂制作mdx词典,这里先谢过了。
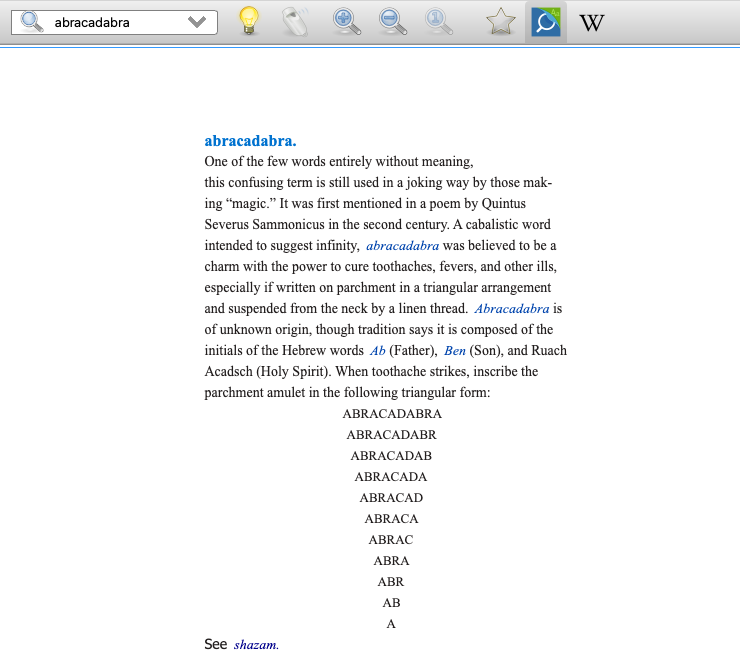
The Facts on File Encyclopedia of Word and Phrase Origins
顾名思义,讲词源 (etymology) 的,可以当作百科全书 (Encyclopedia) 来看。
试举一例:
Achilles’ heel. When he was a baby, Achilles’ mother, the
goddess Th etis, dipped him into the magic waters of the river
Styx to coat his body with a magic shield that no weapon could
penetrate. However, she held him by the heel, so that this part
of his body remained vulnerable. Paris learned of his secret
during the Trojan War, shooting an arrow into his heel and killing
him. Achilles’ heel has since come to mean the weak part of
anything.
非也,他是推荐他38000词汇速记班的学员看的。
这本在etymological dictionary中算是比较大的,但看封面介绍也不过15000多条而已。我翻了翻觉得在同类词典中还不错,就在坛里分享了。
顺着当年你老师的思路说,3000还是有点多了;而按照宋的方法记住500个词根、50个前缀、50个后缀就够了。
我这是资源分享贴,觉得好就推荐了。你觉得不好可以不看,也不用再回帖了。
开卷有益,感谢分享
可以用来当镇班之宝(遇到刨根问底(杠精)的时候可以应付一下(bushi)) ![]()
好像是那么回事儿
用工具提取出来的文本会有单词割裂的现象,暂时无解了,试了好多工具都这样,例如提取的时候会把The 提取成Th e,其他的并不符合Th开头这种规律
没关系,多谢了!
用 pdfminer 生成 xml,可以看到,多出来的空格元素(行2)与它之前的元素(行1),bbox(矩形坐标) 有较大重合。正常空格(行5)不是这样。
<text font="MinionPro-Regular" bbox="324.002,289.816,334.712,303.306" size="13.490">Th</text>
<text font="MinionPro-Regular" bbox="329.332,289.816,331.602,303.306" size="13.490"> </text>
<text> </text>
<text font="MinionPro-Regular" bbox="334.662,289.816,338.912,303.306" size="13.490">e</text>
<text font="MinionPro-Regular" bbox="338.906,289.816,341.176,303.306" size="13.490"> </text>
<text font="MinionPro-Regular" bbox="341.046,289.816,346.326,303.306" size="13.490">d</text>
解析 xml,以 bbox 为特征,干掉多余空格,再转为 html 就好了。利用 textbox 元素分段,利用 font 值分粗体斜体。注意行尾 -。
在下提取文字版pdf的活干的不少,一直是先转rtf或html,再用正则一通操作,基本上没什么问题。你说的pdfminer倒是第一次听说,不过文字版pdf的结构五花八门,很多都混乱不堪,似乎难以有一个通用的工具进行提取并解析。
你用工具把 pdf 转为 html,该工具其实做了类似的计算,也是这么大的计算量,它几分钟、十几分钟就算完了。的确需要优化算法。
能否请大神透露下,你完成这个工作耗时多少?我这样的半桶水来干没一整天拿不下来 ![]()
![]() 用了一周时间,50%时间在找转换工具,发现只有xpdf工具套装好使,40%时间在手工纠错,正则无法考虑到所有的情况,10%时间写python,这个最轻松了。
用了一周时间,50%时间在找转换工具,发现只有xpdf工具套装好使,40%时间在手工纠错,正则无法考虑到所有的情况,10%时间写python,这个最轻松了。
为什么不用 Adobe Acrobat 导出 html 格式?对文本格式的pdf文件,这样得到的 html 格式能相当程度保留原始PDF中的格式信息。你说的 xpdf 套装有什么神奇之处?
我以前对文本编辑器比较无知,处理这样得到的大html文件都是在 Word 里面用VBA处理,现在知道象Vim和VSCode这样强大的文本编辑器都可以安装所见即所得插件,不知道你“手工纠错”“写python”这样的操作在什么环境下进行?比如你调试python时,如何即时查看文本的处理结果?
谢谢指教!