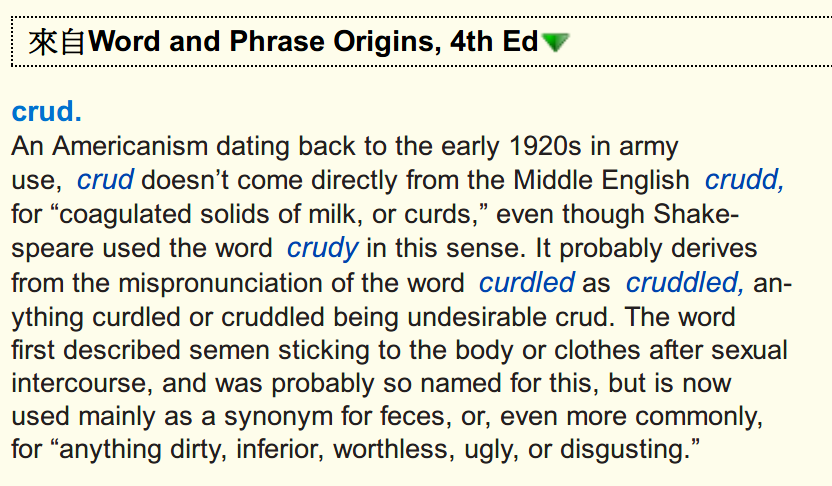
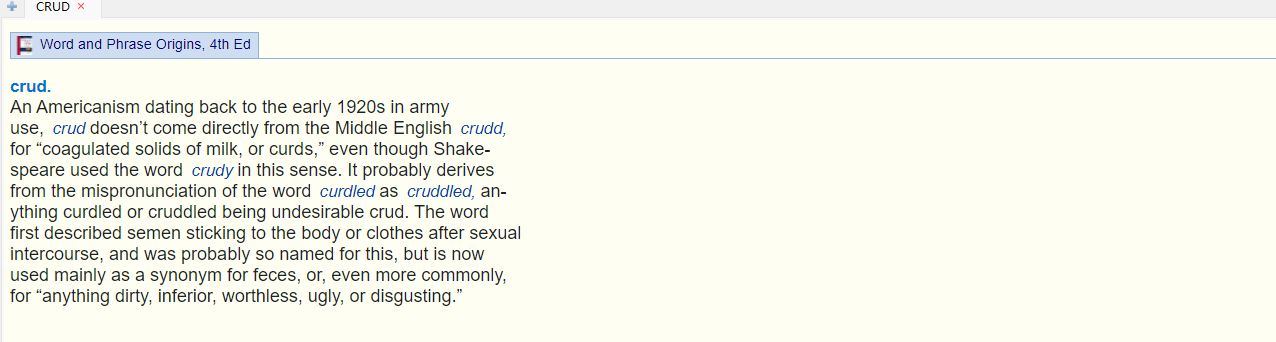
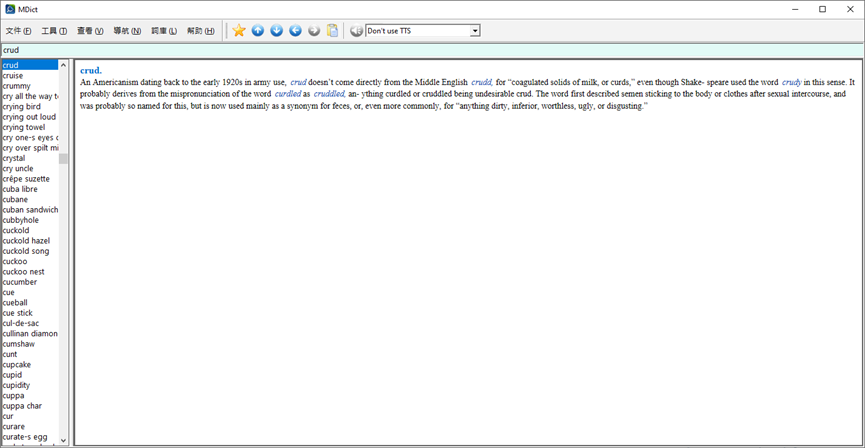
mac上面好像没有adobe,有也要花钱,我找到这个是开源的,你可以去下载 试用下。
主要是我发现这个套件里面的pdftohtml工具处理一些像这个帖子里面的的一页两栏显示的布局时转出来的页面顺序不会乱掉,这样就不需要进行后续处理,其他使用过的的像pdfminer之类的工具转出来的结果,跨页的时候词条内容会错位。
然后就是使用python的beautifulsoup库来加工了。先合并所有的html页面为单个文件然后进行一些数据的清洗和改造,如果到这一步不做词头内跳转的话就可以从改造后的文件提取数据制作符合mdx格式的txt然后打包成mdx了。如果要加跳转会发现各种坑需要反复调试的。
大文件肯定是不能直接用vscode编辑的(黑苹果笔记本太破了
总而言之,这种转出来的数据肯定是要进行一定的深加工才能顺利制作出来相对能用到词典。你有兴趣还是自己去实践一遍看看吧
2 个赞
谢谢老兄的详细回复!
oxford:
一页两栏显示的布局时转出来的页面顺序不会乱掉
如果是在 Adobe Acrobat 中,可以写一个几行的脚本,把双栏的pdf每页各复制一份,然后用crop把左右栏分成两页,再转html就不会乱。用 Acrobat 转出的html格式字体信息都完好,大大减少后续处理的工作量。
没用过这个功能,不知道转出来的效果如何。pdftohtml转出来的页面是按顺序的,合并的时候直接就排好了顺序,去掉页码和标题还有一些无关数据,将样式提取一下,根据类名来决定是词头还是正文之类的,就可以输出成可打包的txt了。
2 个赞
oxford:
去掉页码和标题还有一些无关数据
这个在 Acrobat 中一步修剪就去除了。
下面这个 Acrobat 脚本可以把当前打开的双栏PDF每一页切割成两页,也就变成单栏了(运行之前页面先要居中)
var i, N, rCrop, myWidth;
for (i=this.numPages-1; i>-1 ; i--)
{
createTemplate("t1", i).spawn({nPage: i + 1, bOverlay: false})
rCrop = getPageBox("Crop", i);
myWidth = rCrop[2]-rCrop[0];
rCrop[2] -= myWidth/2; // Right Side
setPageBoxes("Crop",i,i, rCrop);
rCrop[2] += myWidth/2; // Right Side
rCrop[0] += myWidth/2; // Left Side
setPageBoxes("Crop", i+1, i+1, rCrop);
}
weshor
2022 年8 月 10 日 04:07
37
您好,这是我用了您的css的显示效果,词典名称也不一样。
2 个赞
hahaya
2022 年8 月 10 日 04:18
38
谢谢分享!!现在能正常显示了,不过css好像限制宽度了吗?
没有,原文本即如此。
我是用#25那个,配合官方GD,辞典名称直接自己修改就可以了。@ weshor 你确定CSS是用我的吗?要不要再确认一下?
您好,刚刚测试了,效果和之前一样,断行完全比照纸本。请问您有修改什么地方吗?
如果用 Acrobat 导出 html 格式,同一页内一般不会有断行的问题,页与页之间断行还是无法避免需要修复一下。
PDF“双栏”排版,占据页面宽度一半,两边对齐。你可以把显示效果想象成“模拟单栏”或“切图”。如果行宽自适应,那么就要删除每行末尾的“回车符”,虽然可以借助程序完成替换,但难免会产生其他排版错误,在没有更好的解决方案之前,保留原文排版格式也属权宜之计。
1 个赞
Elliot
2023 年12 月 12 日 16:21
46
wpo.mdx (2.8 MB)
調整了標簽,現在不會被限制寬度,只是不要查 Abracadabra 這樣有特殊的排版就好。
3 个赞