挖个坑,管挖不管填,大家早上好![]()
olect,牛津同义词词典(彩虹版)
这个词典由于取自app,咱们论坛的大佬又做了下提取,节省了一次跳转。但是暴露了这个词典数据本身的一个缺点。
只有词典对照组的第一个单词,才有单词的词性,后面对照的都没有标词性,
这一点在提取节省了一次点击跳转后,查看的时候会很累。
先挖个坑,防止忘记
挖个坑,管挖不管填,大家早上好![]()
olect,牛津同义词词典(彩虹版)
这个词典由于取自app,咱们论坛的大佬又做了下提取,节省了一次跳转。但是暴露了这个词典数据本身的一个缺点。
只有词典对照组的第一个单词,才有单词的词性,后面对照的都没有标词性,
这一点在提取节省了一次点击跳转后,查看的时候会很累。
先挖个坑,防止忘记
下面这个才是真正的病因:
要改正最好手头有纸质书。
我个人目测可以:
"/>)/>与)之间,补上文字(例中为especially religion)、以及封闭标签</s>(如果前面是<s s="esp....的话)。貌似<s s="esp...."/>会在渲染过程中被视为缺失封闭标签</s>?especially religion漏掉了,可能是原数据提取过程中的问题。
楼主这个版本应该是用beautifulsoup批量把缺失标签的问题补全了,但又滋生新的问题。
如上面的<s s="esprelig"/>被批量改为<s s="esprelig">) </s></s-blk><s s="esprelig">
后,缺失especially religion内容的问题被掩盖了。此外,第二个<s s="esprelig">也难以理解,从"esprelig"这个标签名上看,<s s="esprelig">和 </s>之间只能是especially religion而不应该是一大段内容
bs4不同解析器出来的结果不太一样
>>> from bs4 import BeautifulSoup
>>> t = '<s s="esprelig"/>)'
#html.parser
>>> BeautifulSoup(t,"html.parser")
<s s="esprelig"></s>)
#lxml
>>> BeautifulSoup(t,'lxml')
<html><body><s s="esprelig"></s>)</body></html>
#lxml-xml
>>> BeautifulSoup(t,["lxml-xml"])
<?xml version="1.0" encoding="utf-8"?>
<s s="esprelig"/>
#html5lib
>>> BeautifulSoup(t,"html5lib")
<html><head></head><body><s s="esprelig">)</s></body></html>
从测试结果来看,使用html5lib解析确实会出现你说的问题。我比较常用lxml,暂时还没遇到奇怪的问题
请问这些喇叭,可以发音的吗?哪里下载mdd?有可以发音的版本吗?谢谢
查thought(名词),①点击idea1却跳转至idea2;②显示doubt2(动词),应该显示doubt1名词方可以对上thought名词词性。
请大神核对!
谢谢!
我觉得是对的![]()
免费mdict6大神对比其他版本的牛津同义词词典,看一看是否有差别?
我就是测完这个版本的olect,才恢复你的
跳转正常(iOS欧路)
second thought 提取到 doubt2 算是加强功能,我看了看物书堂是没有的,然后选2也是没错的(我觉得) second thought 不是三思么…
哦,我的意思可能没有说清楚“②显示doubt2(动词),应该显示doubt1名词方可以对上thought名词词性。”,应该是点击doubt2跳转至名词,结果现在跳转至动词,查不到doubt的名词释义和例句。抱歉!
羡慕安卓一秒钟
之前iPhone上也有牛津英语同义词的独立版本,后来被下架,绑定到订阅制版本的辞典上去了。您这个里面好像是没有发音文件,不知道是不是漏了发音文件?我对比了iPhone 版的Oxford Learner’s Thesaurus 是有语音的。
曾经很喜欢这部词典,但是我没有坚持使用,并在一段时间后从搁置到弃用了这本词典。今天看视频又想起了它,感觉到有点可惜。并把个人感受记录下来。
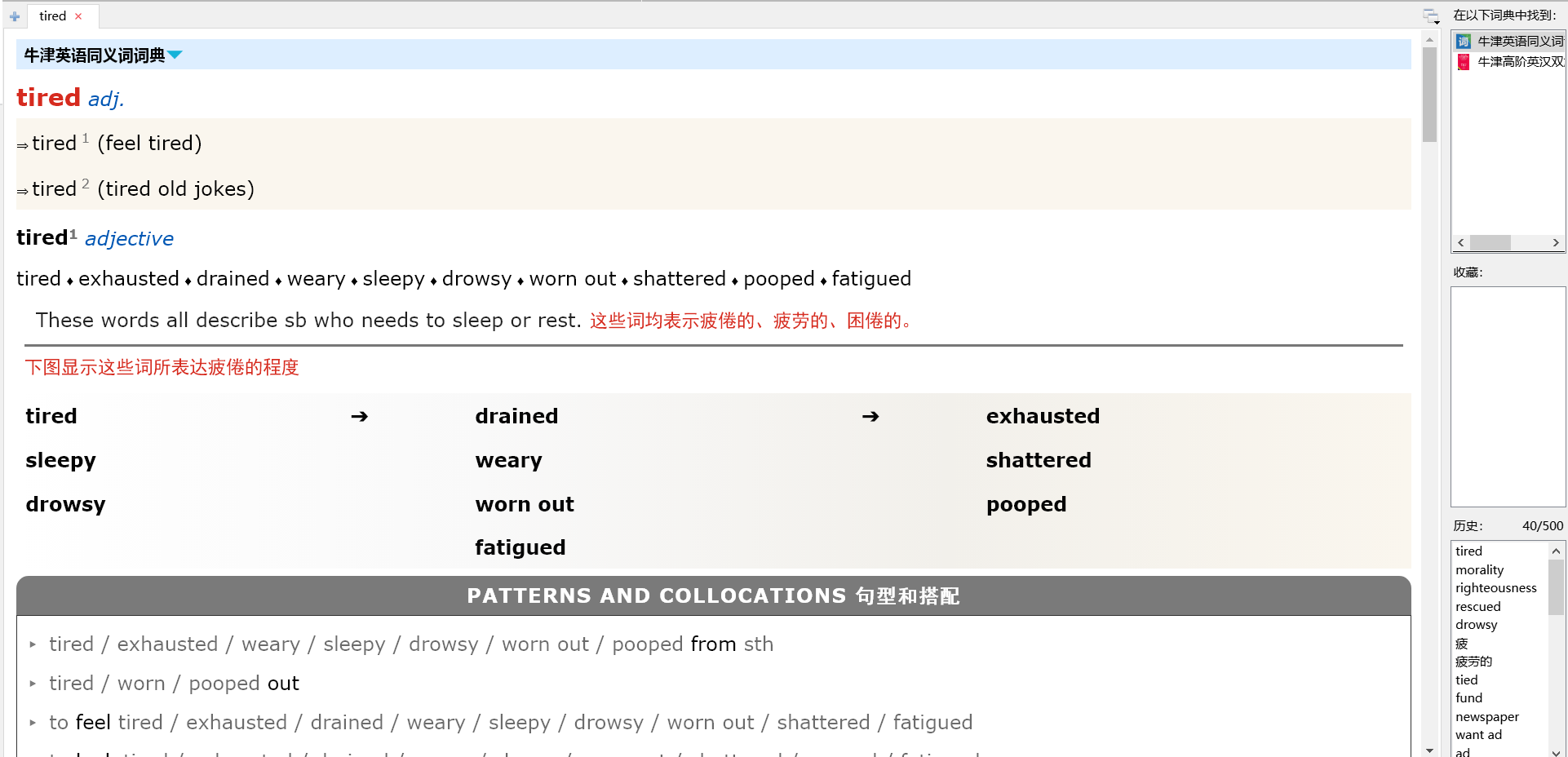
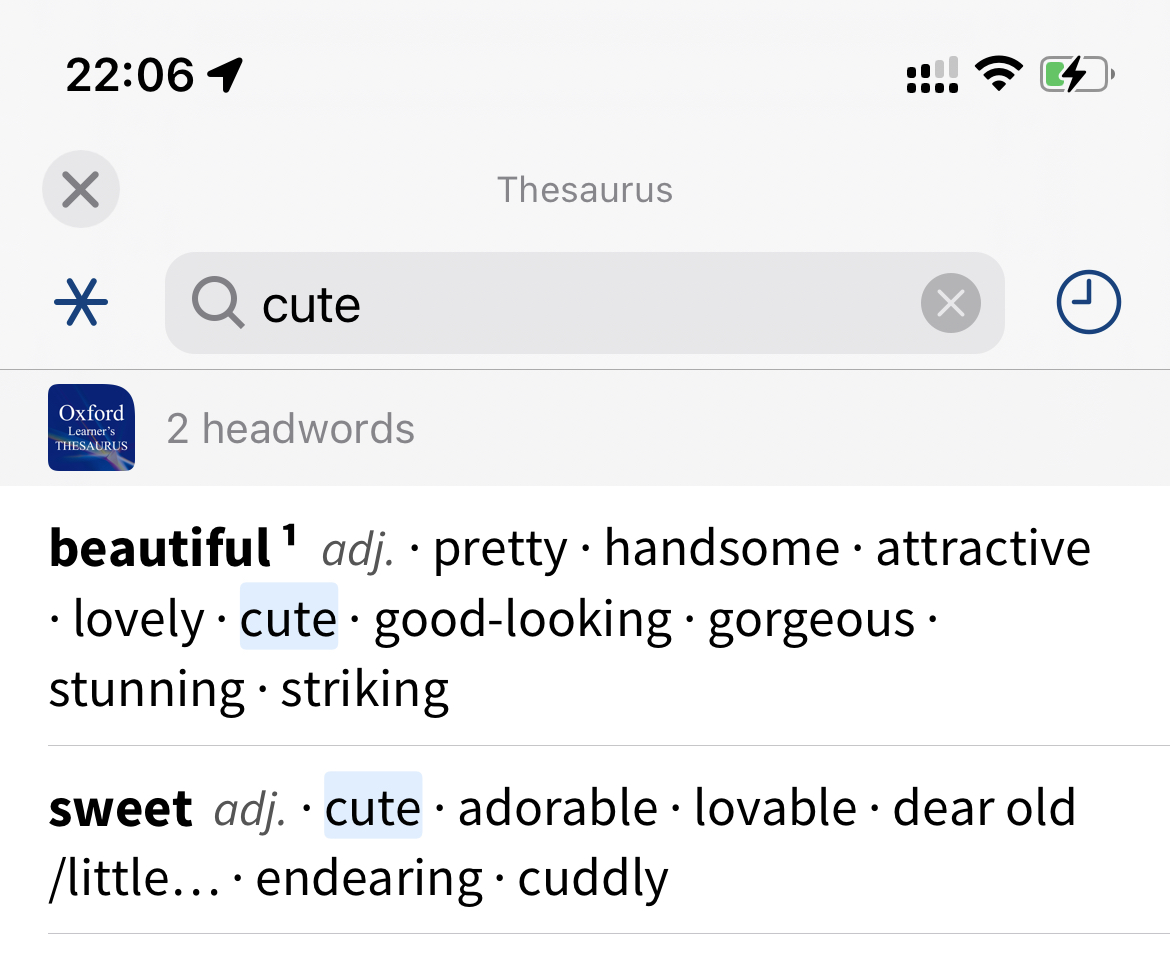
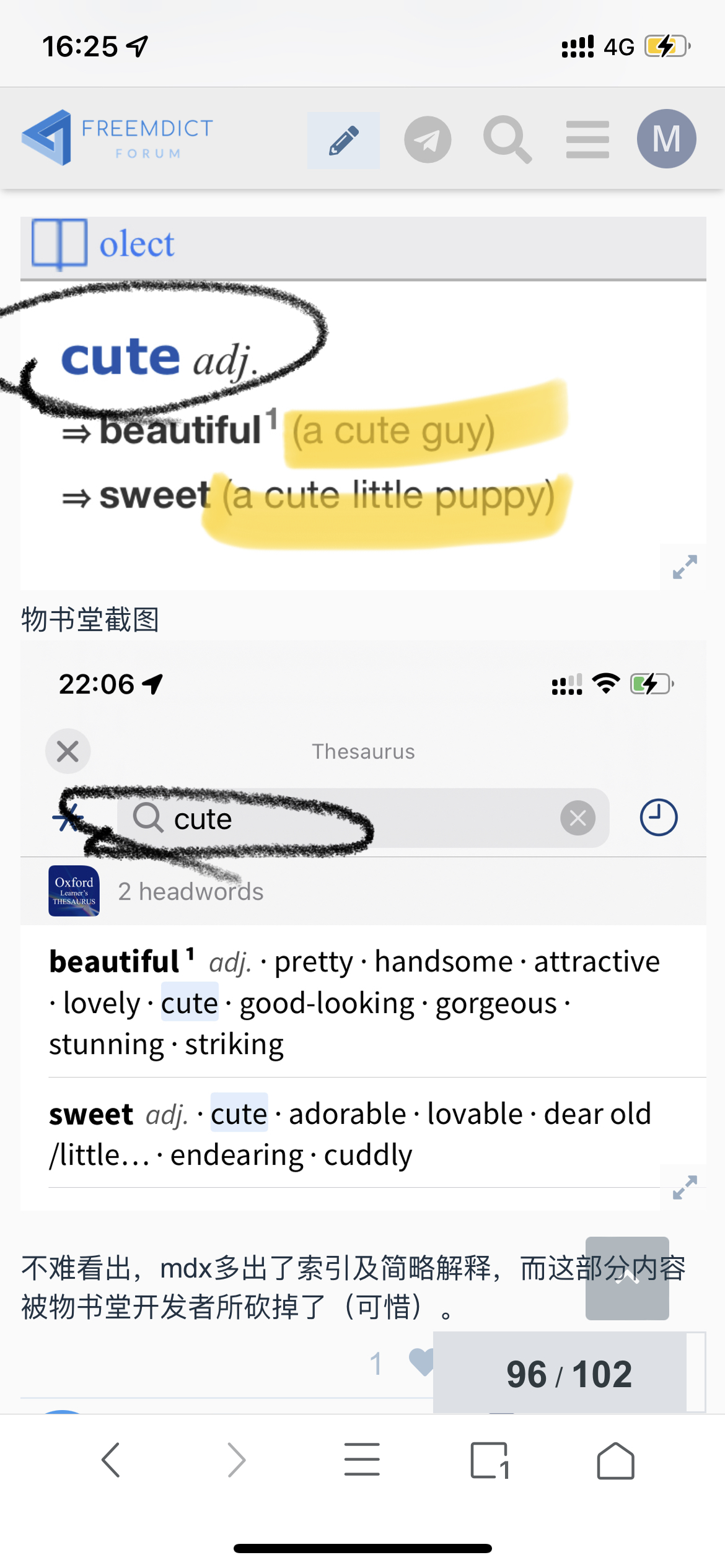
举例:
词头:cute
mdx截图
不难看出,mdx多出了索引及简略解释,而这部分内容被物书堂开发者所砍掉了(可惜)。
不太理解你这里说的缺点,能拿个单词截图举个例子吗
打开css, 直接增加:
s{text-decoration:none;}
我记得这个回复,我是回复错了的。/捂脸笑
感谢更新。
repentance这里不应该是删除线吧?