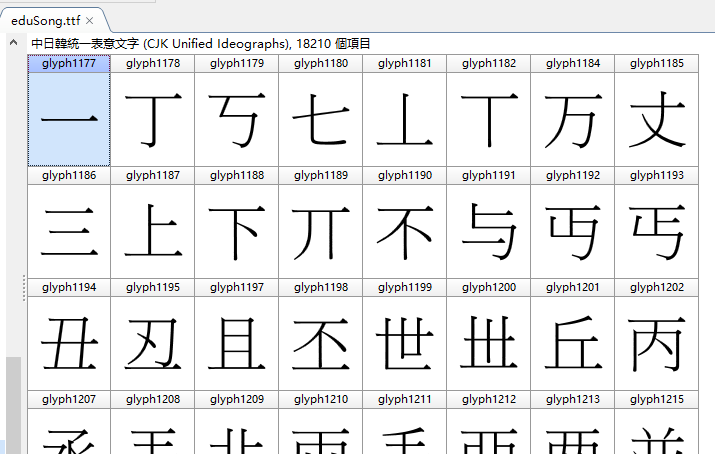
如上图,我在 FontCreator 中直接复制到记事本,出现的是一个个字的名称。
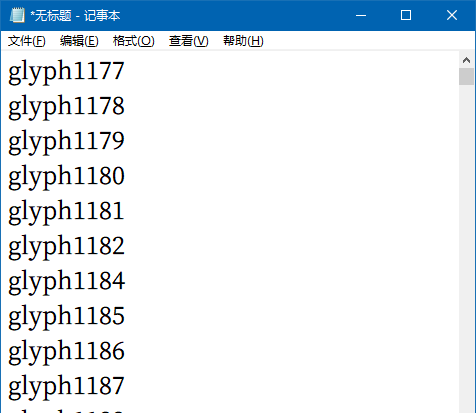
请教诸君:怎样将字体文件中包含的这些文字提取出来呢?
百度“提取字体子集”
有一条信息供参考(我没用过)
FontSmaller 字体文件子集化工具是一个免费的程序,它可以帮助用户从一个字体文件中抽出部分字符,再组成精减的字体文件,主要用于网页设计等
感谢回复。字体子集化工具我用的是 Fontmin 。
我不是要提取字体子集,是想提取字体中所含的文字。
你是想提取 unicode 还是那些字的线条?后者就是一堆数字。
这句话你要表达的意思不清晰哈。
如果你对字体文件里头是什么不太了解,可参考
大部分场景,提取字体中所含的文字是为了这个
如果你要的是位图,截图是最简单的办法
你想复制线条,这是不可行的。你可以认为那些线条是图片,记事本怎么显示图片呢。
是的。字体子集已提取,但现在少两个字……
有其它方法吗,曲线救国?
没有。不过你想解决的是差两个字,或许解决方法是将这两个字的字体子集拿出来?
记事本不行,可考虑最简单的HTML网页,然后在CSS文件里指定原来那个字体文件(或提取后的子集文件)
目前只知道少了两个字,但不知道是哪两个 ![]()
我是想把文字都导出来和原来的文字比较比较。
不错,此方法也许可行。
没事,慢慢摸索,不难。
很多时候是因为对字体的背景知识不足,导致描述自己的需求不够精准。
字体说简单也简单,说复杂可以牵扯到各个操作系统处理字体显示的流程和差异
入门可参考
你把glyph开头的从缺的字体中复制出来,再把全的复制出来,都放到 Excel 里面,查找右边有左边没有的。。
感谢您的解答,我再想想。
再请教一下,怎样提取 unicode 呢?只想要这些字码点。
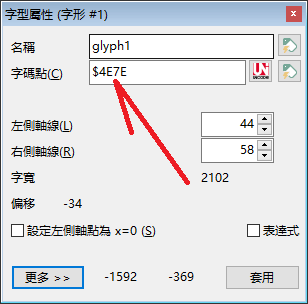
我刚才试了,感觉 fontcreator 无法批量提取字码点。。这个字码点就是 unicode。不过我可以用 python 给你提。
太麻烦您了 ![]()
minifont.rar (1.4 MB)
屏显臻宋_mini.woff.codepoints.txt (19.4 KB)
eduSong_mini.woff.codepoints.txt (19.6 KB)