找到了,再次感谢。
将 uni9F9C 改成 龜 形式,在Em里就可以转成文字了。
找到了,再次感谢。
将 uni9F9C 改成 龜 形式,在Em里就可以转成文字了。
按这思路,再将少数特殊字转化成css中的字体文件样式,这样可减少另外安装或放置字体的麻烦,又能清楚显示。这方法若能批量操作,应会广泛采用。如要显示含异体写法之类的句子单词,为少数字专门放上一个大字体文件总觉得太浪费了。
我是這樣做的:
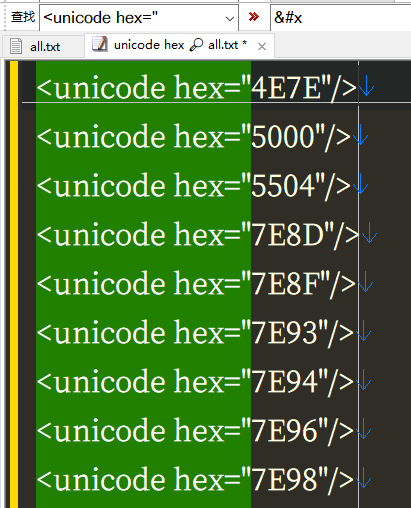
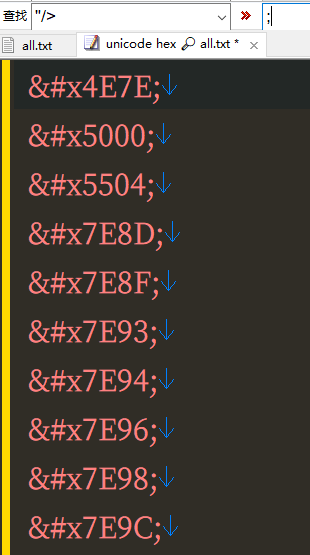
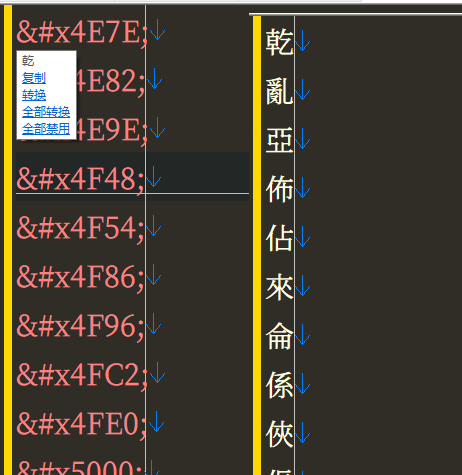
在fontcreator 選擇 打印 字形,生成PDF,把PDF 轉成TXT,即可得到 所有字形的U碼。再把U碼轉成漢字即可。
親測可用。
好方法!马上来试试。感谢!
你也想提取字体子集吗?可以试试 Fontmin。
提取出来的子集同时有 ttf,woff,css。想用哪个用哪个。
Fontmini针对让一些部分显示为某一字体应是不错的工具,谢谢推荐。
从PDF转成U码的TXT,没试过。有点疑问是,PDF生成时会嵌入按照字体所内嵌的U码或特殊编码?转成TXT的工具也能无差错地将此码转出?如果是统一的U码,那处理起来会简单。如果是特殊编码对应特殊的字,不知这方法是否通用。
请再给一点点指点!
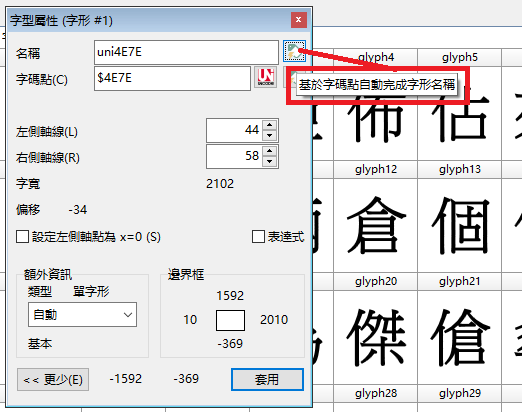
请教一下,下图红框所指的能批量生成吗?