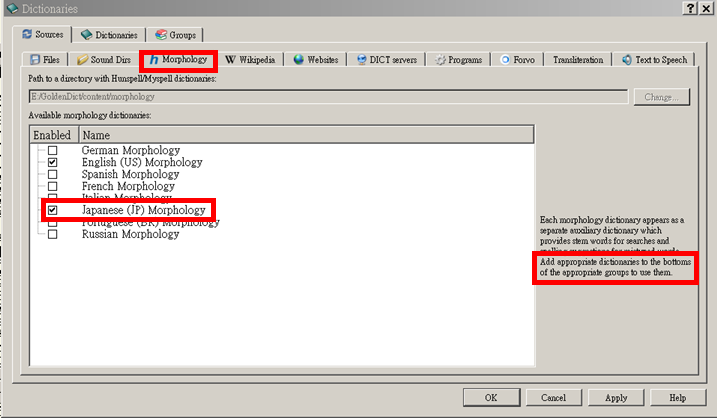
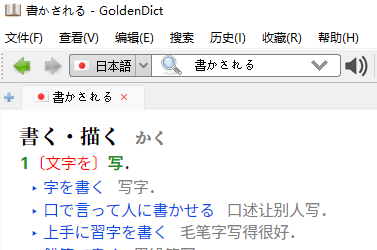
这本辞典试图解决是由于日语动词活用导致无法直接复制粘贴的问题,如果你尝试过通过GoldenDict的Ctrl+C+C查日语单词的话,就比如这样: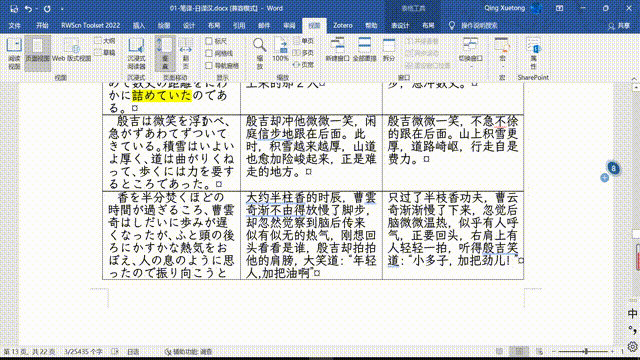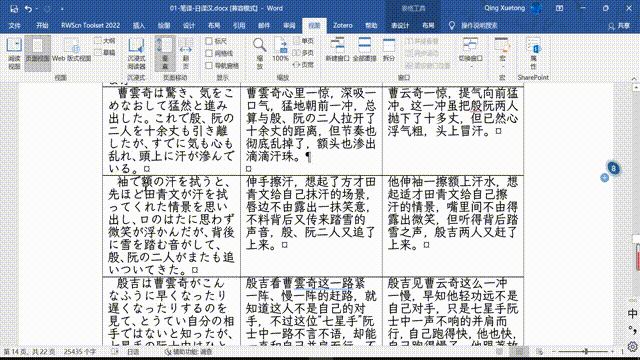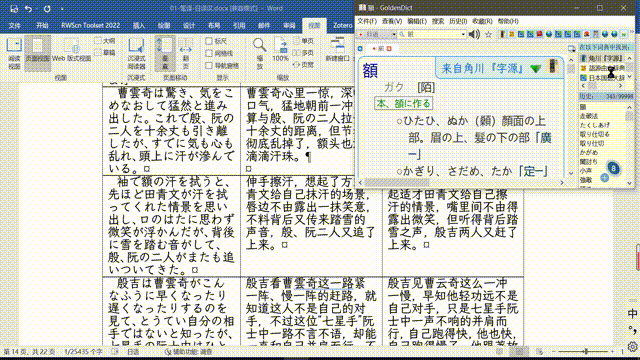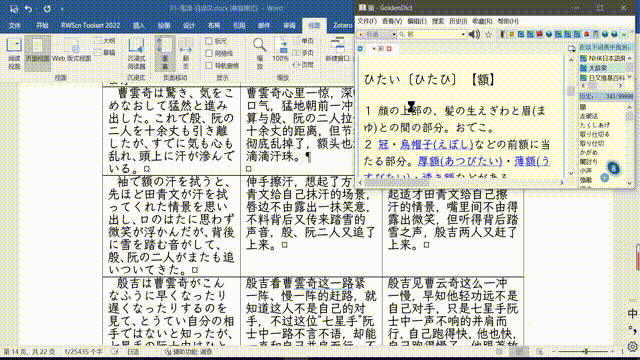
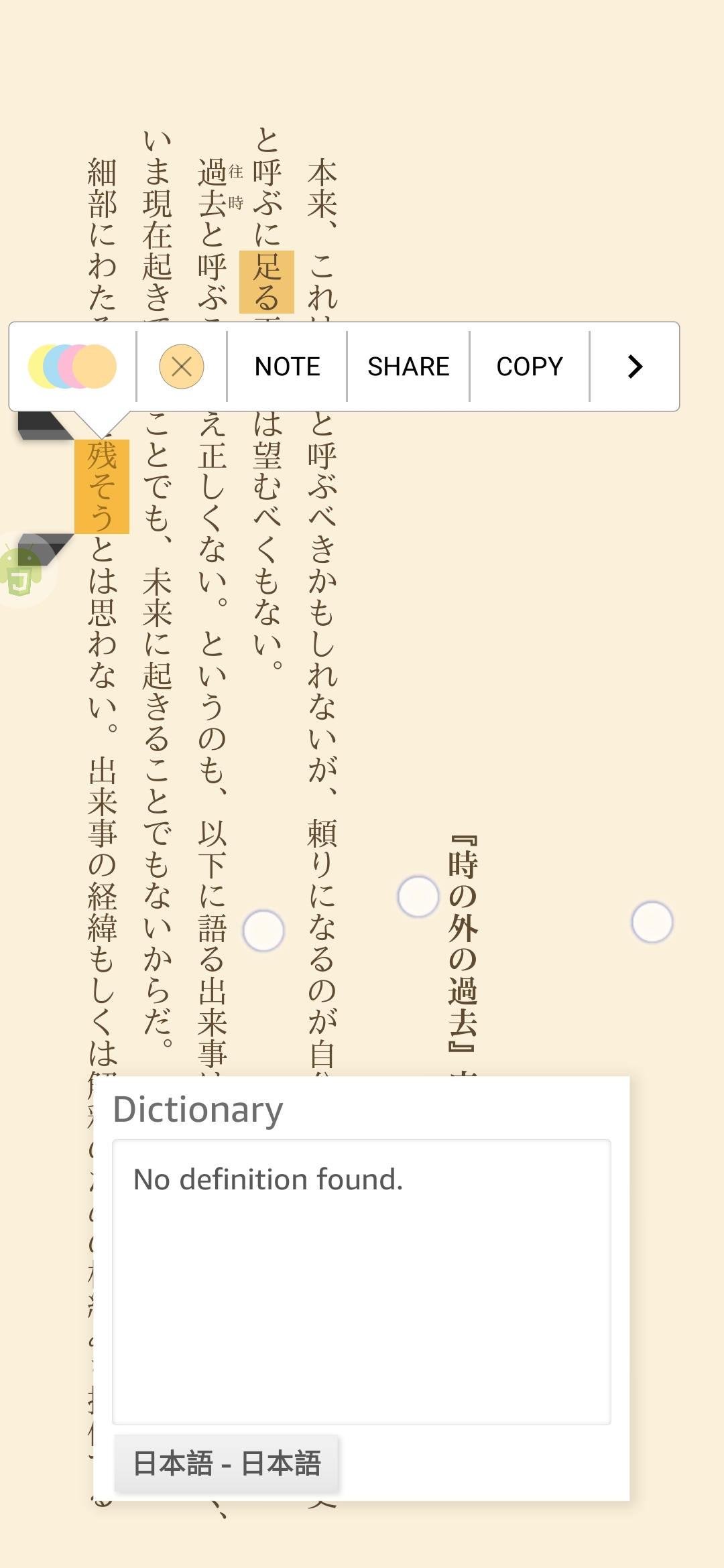
但我目前为止收集到的所有辞典,都不能这样查动词——比如下图

很多用过GoldenDict应该会猜到到这本辞典作用:解决类似英语单复数变形导致的词形变化问题——但日语要复杂得多,所以TA目前还有很多有待完善的地方,希望大家能友善地提出改进意见。
下载地址
需要再次强调的是:这本辞典只是尝试给出一个「非辞書形」对应的辞书形,方便复制粘贴,除此以外,没有任何值得称道的地方,请确认自己是否真的有这个需要再下载。
词典文件
论坛网盘https://cloud.freemdict.com/index.php/s/Q62m2gk2dT5Lm99
蓝奏云 https://wwa.lanzouf.com/b011ddt4h 密码:9x1k
以下是原文,如果你对具体的技术细节感兴趣,建议到这里「日本語非辞書形辞典」阅读原文(文章结构更清晰)。
我之所以会折腾这个,一开始还是因为自己平时都是像这样直接复制粘贴查单词:
电脑端
手机端

但上述方式十分依赖词库文件,如果词库文件没有收录复制粘贴的内容的话,就只能自己手打。
这时我们就只能老老实实自己判断出「辞書形」,然后输入查询——但反过来说,只要我们告诉APP,一个「非」辞書形对应的是哪个「辞書形」,就可以省去这一步的时间。
说起来容易,做起来相当麻烦,一路磕磕碰碰地折腾下来也发现了很多有意思的地方——应该可以说是日语独有的一些问题了吧,所以专门整理成了这篇文章,也欢迎大家跟我交流,邮箱地址:NoHeartPen@outlook.com。
不过不要担心,具体的技术细节我会放在最后,下面先谈的是一些学日语的同学都知道但很少会写下来的东西。
简日 汉字优化
首先,从汉字开始谈起——我估计很多同学在才开始学日语的时候都遇到过这个问题:就是不知道一个字该怎么读,要查它还得把它给打出来……
这时有经验的同学会掏出汉典搜繁体,再复制到查词软件挨个挨个的试出日语汉字;而没经验的同学就会试着向恶势力低头——moji的VVIP支持手写输入。
我自己的话,会用Gboard——它也支持手写输入,而且没有国内的输入法会有更偏向识别成简体、或者对日语汉字识别比较糟糕的问题。
跑题了,说回来,在手机上,moji/沪江小D还好,都支持输入简体查对应的日文,多查几次,也就能猜得出来了。但像欧路/EBwin/GoldenDic,都不支持这个功能——它们都不是为中国人学习日语开发的软件,所以只能专门制作一个词典实现这个功能。
我想出的办法也很简单:网上已经有非常成熟的工具用于简转繁,但简体字 、繁体字、日语汉字三者其实是有细微差别:比如儿童(简)、兒童(繁) 児童(日)
…
所以到目前为止,我没有找到直接能简转日的工具,希望知道这方面工具的人能告诉我一下。
动词变形
下面先来谈最棘手的动词变形,moji、沪江、欧路都能应对简单的动词变形,稍微复杂一点的话,也只能自己判断出原型再查。
至于EBWin和GoldenDic,都只能查原型。这是因为他们的词库文件都只收录了辞書形即原型,所以对他们而言,活用后的动词都是一个单独的单词。
一开始觉得不是很难,毕竟动词变形不就在同行的五个假名上变么?那总共也就…那么几种嘛。
那我先随便挑一个单词列一下好了:
怒られる、怒らない
怒り、
怒れ!
怒れば、
怒ろう
差不多了吧?但仔细一看,怒られる 不是也可以活用为怒られれば么?怒らない不是可以活用为怒らなければ么?
而且由于怒る的连2并非是同行上变换,而是怒った——嗯?怒られた是不是也没列?怒られなかった是不是也漏了?
再仔细一看,完了……怒られなかった是不是也可以活用为怒られなければ?
也许你还会提醒一句怒って呢?而且使役态丢到哪里去了?
怒らせる这个同样有怒らせた、怒らせれば
经常看日剧动漫的说不定还会低声嘟囔句怒っちゃ
……
如果以上就是我尝试从语法的角度思考思考,但陷入了一个狼狈的局面:日语动词变形不只一次,可以进行多次——这正是日语能有丰富表达的关键,但我并不是在欣赏日语严谨的语法结构,而是试图一劳永逸地穷举所有变形,所以这个特点令我头疼了很久。
其他语言有类似的问题么?他们是如何解决的呢?
回答:中文不存在这样的问题;英语虽然也有类似的问题(人称s、复数es、时态ed),但我找到的解决办法也是穷举:Github上有个项目的forms-EN.txt)文件就是这样做出来的。我还试着读过黏着语有关的论文,但完全不得要领。
接下来,换个思路,不从的语法角度继续穷举变形,回头看看目前列出的所有变形,能总结出日语动词活用的规律吗?
当然能。
尽管他们的形态上发生了巨大变化,但他们词尾位置的假名的只有下面几种情况:
怒ら
怒り
怒る
怒れ
怒ろ
怒っ
不管活用成什么样子,最终的结果都不会跳出上面的六种结果——其他动词也基本类似,就不展开了,具体的注意事项在下面的技术细节处进行说明。
形容词变形
虽然日语的用言有三种,但形容动词活用没有发生明显的形态变化——至少从查单词的角度可以忽略,所以我们接下来谈谈形容词。
沿着上面的思路,想想词尾部分是不是只有下面几种变化?(这回就不兜圈子了,直接给出我思考的最终结果,有遗漏的话,欢迎补充)
さ(名词)
し(古语名词)
く(副词)
か(った,过去)
け(れば)
み(名词,部分形容词有)
平片假名查询优化
接下面来谈平片假名。先以这句话中的拟声拟态词为例:隅の方に小さくなって黙ってチョコチョコ働いていたものだから
如果直接输入チョコチョコ那moji 和沪江给出的解释都是错的。
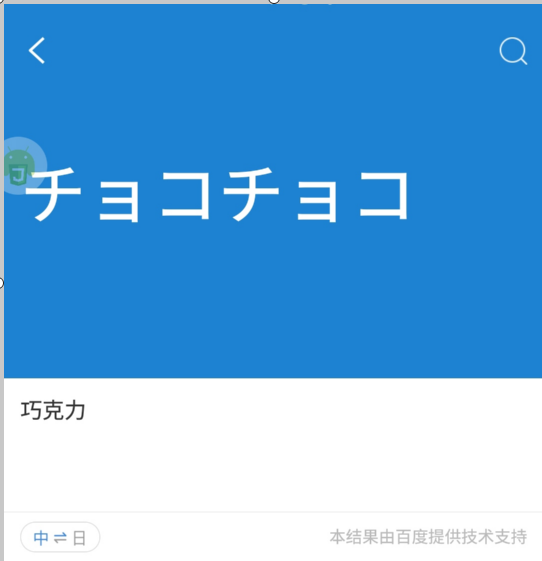

因为这个单词其实就是ちょこちょこ,作者是出于强调动作的缘故,才写成了片假名,明白了这一点,再去查。
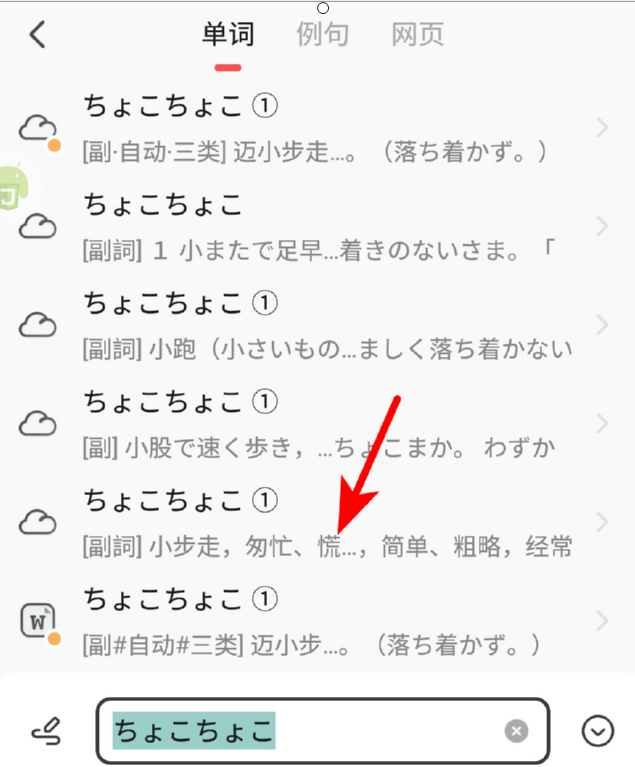
当然,也不只有拟声拟态词会这样写,有些时候,还出现下面这样的情况ハタから見た感じを云えば、執方かと云うと、陰鬱な、無口な児のように思えました,这里的ハタ其实可以写はた,但如果直接去查ハタ,moji和沪江给出的结果就令人哭笑不得了:

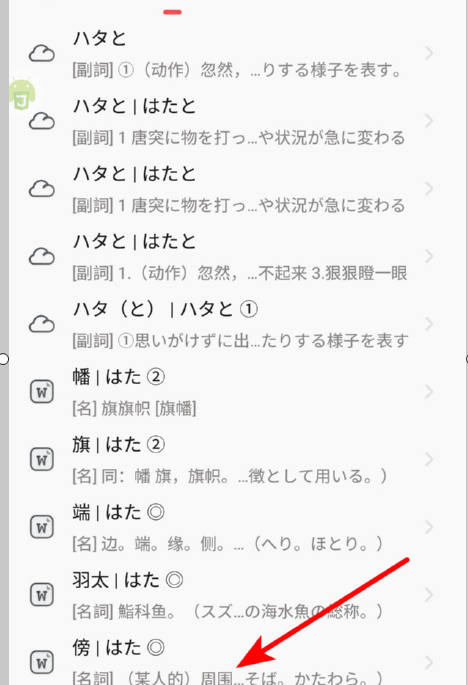
另外,很多时候动物的名字也会写片假名,这里就不举例了。
以上,是已经解决了的问题,下面要谈的是我还没有解决的问题,写出来算是抛砖引玉吧。
复合动词
日本人日常使用复合动词时,第二个动词往往只写假名——虽然笔译课上老师的解释让我意识到 这可能与它们表达的意思的细微差别有关,但怎么解决却毫无头绪……
举一个例子吧: 湧きたたせる——打成这个鬼样子多半查不到,标准写法 湧き立たす或者全都是平假名わきたたせる才行。
词组的优化
和上面的一样,会由于具体的语境,发生一定变化,比如を被替换为は:筋は通っている。字典里一般都会有筋を通る,但很少有字典会收录筋は通る
再比如が被替换为も,比如:これで殷、阮の二人を十余丈も引き離したが、すでに気も心も乱れ、頭上に汗が滲んでいる像心も乱れる这样的形式,就更不可能收录了……
下载地址
词典文件 https://wwa.lanzouf.com/b011ddt4h 密码:9x1k
致谢
首先,非常感谢Y老师——在我对这些细枝末节还只有不成熟和幼稚的想法时,耐心的回答了我提出的问题,并提供了力所能及的帮助。没有Ta的鼓励,我断然不会花那么多功夫思考这些杂七杂八的东西;
也非常感谢C老师——没有Ta在课堂上用更细微的角度讲解日语的动词活用,我可能真得会从语法的角度,徒手穷举完所有动词变形。
同样也非常感谢Z老师,从Ta那里学到的日语基础语法是我会注意到这些问题的前提。
最后也非常感谢网友满星MAX,Ta的这篇Python辅助MDX转MOBI(以AHD5th为例给了我很多技术上的启发。
题外话
有人可能会问:折腾这些有意义么?手打耽误不了多少时间的吧?
是的,而且还可以当作打字练习,以及培养联系语境-思考上下文-查单词-真正「习得」一个单词的习惯——走马观花地看看词典的解释并不会提高外语水平。
但我有在Kindle上看书的习惯——Kindle的词典功能是真的香,但可惜我买的版本不能打日语,这就非常难受了
虽然现在已经不用上面这台老古董了,但现在用的电子书阅读器博阅P10,内置的词典功能也不支持变形(虽然可以装欧路词典),而用过墨水屏的都知道打字是什么体验……
另外,我用来背单词的AnkiHelper,也不能直接查阅变形 ,甚至连输入框都没有,只能依靠软件加载的词典自己区分所有变形

最后,Kindle APP 和PC端的虽然也有查词功能,但也查不了日语动词的变形,英语却没有问题,这就激起了我的好奇心——是做不到?还是不愿做?
以上总总,促使我花了接近2年的课余时间,摸索着解决了这篇文章提到的大部分问题。
至于为什么要单独做一个词典,而不是直接修改词典文件,原因如下:
- 便于维护——修改一个顶了天也就10M的文件和修改一个至少500M起步的文件,该怎么选就不用多说了吧;
- 只需将它放在词典的顶端,能查询到变形的词头时就会正常显示,反之,手动输入辞书形查询时,不会有任何结果——那和乐而不为呢?;
- 避免版权纠纷;
- 技术细节来说,mdx、idx、AnkiHelper的txt格式这3种文件的架构都是
词条——解释,单独制作一个词典后,要转成其他格式也不难; - 至于EBwin格式的词典,我没有专门研究过制作方法,因为GoldenDic也可以加载这种格式
技术细节
考虑到接下来的部分理解起来可能比较困难——一半是因为我写得烂,另一半可能是大多数人对阅读这部分所需的知识比较陌生,所以我强烈建议先读一读下面的这些链接:
- Unicode - 维基百科,自由的百科全书 (wikipedia.org),了解在计算机的世界里,每个字符都有一串对应的数字即可,比如12354对应平假名あ,12345对应的是〹
- 正则表达式——把这个当成Word的通配符就可以了,明白
(.*?)\t和\n这2个东西的作用再好不过了,当然,如果你真要自己动手,还是得了解断言、分组等高阶语法; - HTML和CSS基础即可,由于MDX格式的词典源文件是用这种语言写的,所以了解基本语法即可;
- 我下面给出的代码都是基于Python3的,所以如果你想用现成的代码的话,可以先学学Python的基本语法,当然如果你有其它语言的基础的话,了解下Python的正则特性即可(可以参考这本正则指引(第2版) (豆瓣) (douban.com)的相关章节)
注意,下面代码操作的都是只有词条的txt,所以才会这么简短,如果你是用的我的另一篇《mdx大辞泉转idx》的工具的话,要提取词条就是个技术活了……我自己尝试过,但最后还是选择GoldenDic右键点击查看词条然后导出的方法,但这样似乎丢失了部分词条…
汉字
遗憾的是由于Unicode编码时,对于日中汉字没有清晰、严谨的区分,导致了没有办法简单的将简体字与日语汉字对应起来,进而快速制作一个日中汉字对应词典;再加上简繁对应的词典网上有很多,就不献丑说我是怎么做的了,
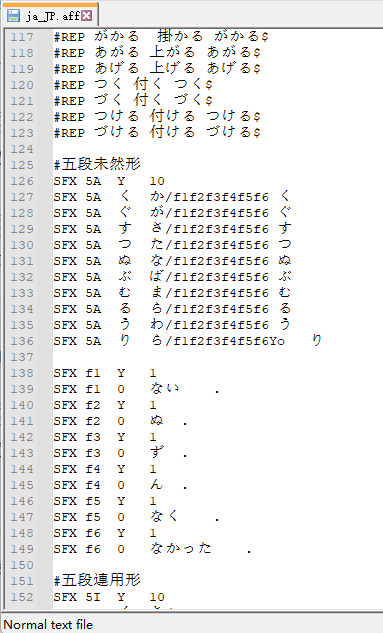
动词变形
以う段变换到お段举例:
for line in f:
kana = line[-2]
if kana == 'う':
line = line[0:-2] + line[-2].replace("う","お"+'\n')
print(line)
f2.write(line)
elif kana == 'く':
line = line[0:-2] + line[-2].replace("く", 'こ'+'\n')
f2.write(line)
elif kana == 'ぐ':
line = line[0:-2] + line[-2].replace("ぐ", 'ご'+'\n')
f2.write(line)
elif kana == 'す':
line = line[0:-2] + line[-2].replace("す", 'そ'+'\n')
f2.write(line)
elif kana == 'ず':
line = line[0:-2] + line[-2].replace("ず", 'ぞ'+'\n')
f2.write(line)
elif kana == 'つ':
line = line[0:-2] + line[-2].replace("つ", 'と'+'\n')
f2.write(line)
elif kana == 'づ':
line = line[0:-2] + line[-2].replace("づ", 'ど'+'\n')
f2.write(line)
elif kana == 'ぬ':
line = line[0:-2] + line[-2].replace("ぬ", 'の'+'\n')
f2.write(line)
elif kana == 'ふ':
line = line[0:-2] + line[-2].replace("ふ", 'ほ'+'\n')
f2.write(line)
elif kana == 'ぶ':
line = line[0:-2] + line[-2].replace("ぶ", 'ぼ'+'\n')
f2.write(line)
elif kana == 'ぷ':
line = line[0:-2] + line[-2].replace("ぷ", 'ぽ'+'\n')
f2.write(line)
elif kana == 'む':
line = line[0:-2] + line[-2].replace("む", 'も'+'\n')
f2.write(line)
elif kana == 'る':
line = line[0:-2] + line[-2].replace("る", 'ろ'+'\n')
f2.write(line)
else:
f2.write(line)
囧……好像暴露了我的Python水平,但比起按照日语五十音图的风格排列,挨个抓出所有在う段上的词头,然后用Unicode码+2得到え段、-2得到い段这样纯属脱裤子放屁的行为,还是这样更快(虽然不太体面233)
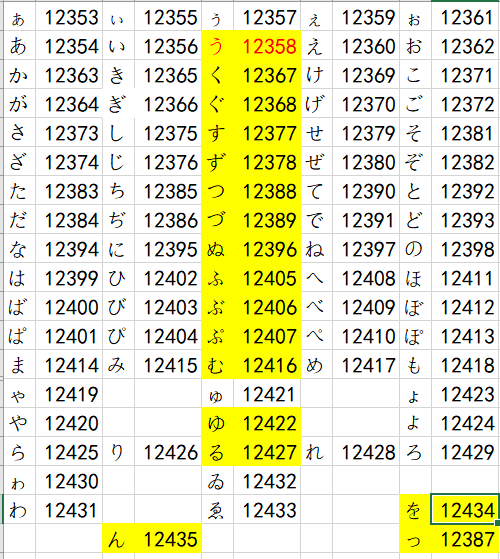
(其中高亮的部分就是与动词变形直接相关的う段假名以及有特殊音变的假名)
平片假名
简单来说,都是基于Unicode对平片假名的编码规律进行转化,尝试把它们排成2列

不难发现:平假名+96=对应的片假名,所以关键代码如下:
hiragara_word = "ちょこちょこ"
katakana_word = []
word_list = list(hiragara_word)
for hiragara in word_list:
katakana_code = int(ord(hiragara))+96
katakana = chr(katakana_code)# 当然你可以写成一句:katakana = chr(int(ord(hiragara))+96)
katakana_word.append(katakana)
def format_list2str(list_element):# 直接返回的数据就是一个列表,直接保存还得自己删
list_element = str(list_element)
list_element = list_element.replace(",","")
list_element = list_element.replace("[","")
list_element = list_element.replace("]","")
str_element = list_element.replace("'","")
return str_element
形容词变形
这个很简单,随便用一个文本编辑器——Word也行,直接把い替换为く,然后保存即可,之后重复上述步骤,就可以到得到所有变形。
词组优化——は、も
这个稍微麻烦一点,我还没动手,但大概思路处理形容词一样,手动替换即可。
其他思考优化
提取声调
网上流传的《日本国语大词典》里面事无巨细地列举包含声调、語源、方言、表記在内的各种信息,但对我这种半路出家学日语又急于求成的人来说,每次都要在一堆“古色古香”的例句里找半天才能找到我需要的声调部分——《大辞泉》没有这个;moji的可靠性存疑;《NHK日本語発音アクセント辞書》收录的单词太少,而且有些词条非常奇怪;OJAD - オンライン日本語アクセント辞書 (u-tokyo.ac.jp)只囊括了动词和一些声调特殊的名词;最后,也是最重要的一点:有些外来语的地名基本只有《日本国语大辞典》才有声调。
虽然我知道已经有了大概思路——正则做到这一点不难,但要制作一个完美的声调词典,需要不断的打磨,而我由于学业和实习原因,只能开诚布公地告诉大家我这个不成熟想法~~(其实是试图勾引大佬出手)~~。
Base编码嵌入字体
虽然GoldenDic上可以修改字体(参考这篇教程GoldenDict 界面显示风格、字体、背景等等的修改和),但是欧路词典似乎不会被系统字体影响(至少我的小米手机是这样),虽然我已经忍了很久,但一直没有找到比较好的教程,所以希望有知道的人可以指个路。