确实依赖jQuery,目前用的是词典自带版本的jQuery
有可能吗
我不会js,没法判断![]() 。我的js都是跟google学的
。我的js都是跟google学的![]()
查询结果,用菜单上的保存功能,保存成html,然后浏览器打开html,双击看下选中了哪些单词。
不好意思,虽然您已经修复了该问题,但我还是想说明一下:goldendict的hunspell功能的推导结果是由后缀名为.dic的文件收录的单词决定,不会被加载的词典影响。
而欧路词典的 Android 端的机制不一样,会被用户加载的词典影响(您的怀疑在这个软件上是成立的)。
另外,我认为日语想要像英语一样,完全用剪贴板查词,有些问题通过 hunspell (可能)无法解决——日语的词形变换比英语复杂得多,而且日语有独特的排版规则,所以我专门制作了《日本語非辞書形辞典》,您可以查阅这些帖子和他们的讨论区,了解一些大概:
这里谈到了日文的词形变换特点
这里谈到了日语独有的排版规则
如果您愿意了解更多,我会抽空整理一篇文章系统、详细地向您解释日语究竟有哪些特殊之处(可能要一个月左右的时间,如果整理好了,我会专程通知您)。
如果有可能的话,我希望GoldenDict能原生处理上述提到的问题,不用这里提到的方法[非mdx也能所划即所得啦_日本語非辞書形辞典_v3_For_Quicker_Demo ]——用脚本和Quicker等工具中转实现。
2 个赞
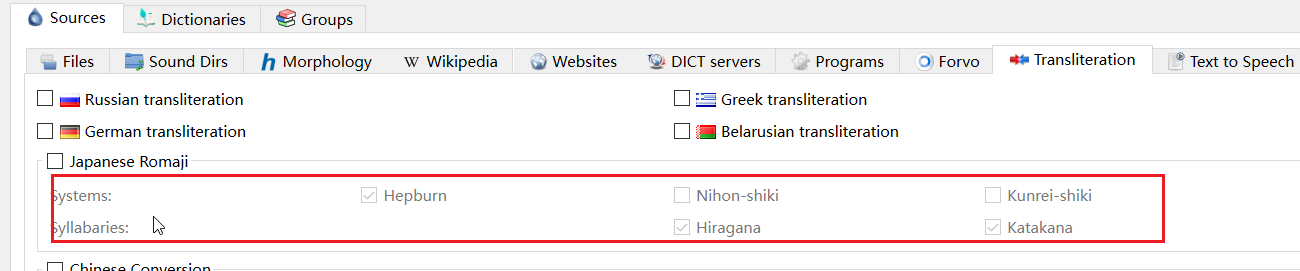
应该和中国的日语学习者没有太大关系。您所指的地方主要影响的是日语的罗马音(您把它当做拼音好了,都是西文字母)。
具体来说,要处理的东西就类似中文中通行的简体拼音方案和威妥玛拼音方案之间的差异,开启之后的效果是像这样的:
Tsinghua University 处理为 Qinghua University、
Tsingtao 处理为Qingdao 、
Peking University 处理为 Beijing University
(这些例子可能不是很严谨,因为部分拼写方法依据的读音不是现在的普通话)
也就是说它主要是解决的罗马音(或者说西文字母)拼写方案之间的差异。而中国的日语学习者很少会通过罗马音(比如taberu)来查单词,一般是用假名(比如たべる)或者汉字(比如食べる)来查,但我在部分外国人设计的词典网站看到他们支持罗马音来查东西,所以才会有个这样的功能(但中国人应该用不到)。
我想要解决东西类似英语的时态导致的问题,比如下面这样:(为了便于比较和说明,例句是我造的)
私はご飯を食べている(我正在吃晚饭)
I am having dinner
私はご飯を食べていた(当时,我正在吃晚饭)
I was having dinner
私はご飯を食べた。(我吃了晚饭)
I had dinner。
私はご飯を食べなかった(我没有吃晚饭)
I didn’t have dinner。
母親は私をご飯を食べさせる。(妈妈让我吃晚饭)
Mom lets me have supper
母親は私をご飯を食べさせない。(妈妈不让我吃晚饭)
Mom won’t let me have dinner。
加粗的部分就是2种语言中的动词(也是使用常规构词法功能要划的部分),可以发现:英语表达不同的意思时,形态变化不会在一个动词上连续发生(所以动词的变形要少得多,这里只有3种);而日语表达不同的意思时,形态变化会多重嵌套在动词上(所以上面每句话都是一个新的变形,,而且远不止这些)。这导致日语的构词法文件非常复杂,所以我才会想尝试其他解决办法。
可能没什么用的参考:平文式罗马字 - 维基百科,自由的百科全书 (wikipedia.org)
(删了也没用,我已经通过邮件存档啦)
您推荐的那个工具应该是用于分析文章,划词应该不是他们设计这个工具的初衷,二者还是有一定的区别(比如划词的时候,上下文语境基本丢失;又比如,划词的文本没有经过清洗,需要专门预处理)。
不过我们可以参考他们的处理细节,进行一定的修改(分词什么的就不用管了,我们只需要关注分词之后的推导过程即可)
下面是我搞了一半的笔记,给大家一点思路(非计算机科班,只懂Python皮毛,大家不要被我误导了哈):
他们提供其他语言的源码,这里(只能慢慢往下滑,搜不了是怎么回事……)
但下载之后发现文件未免太小了
3个Python文件就可以实现日语的NLP了吗233,应该还是要调用打包好的 exe(但我是要研究处理细节啊,不可能去读二进制代码吧)……另外使用的是python2的语法……
所以就没往下研究了。
又不死心找了一个:
( SamuraiT/mecab-python3: mecab-python. you can find original version here //taku910.github.io/mecab/)
非官方接口,虽然提供了Python接口,但实际处理过程也(应该)不是Python
我的解决办法不太学术(加粗部分是使用我提出的方案要划的部分):
私はご飯を食べている(我正在吃晚饭)
I am having dinner
私はご飯を食べていた(当时,我正在吃晚饭)
I was having dinner
私はご飯を食べた。(我吃了晚饭)
I had dinner。
私はご飯を食べなかった(我没有吃晚饭)
I didn’t have dinner。
母親は私をご飯を食べさせる。(妈妈让我吃晚饭)
Mom lets me have supper
母親は私をご飯を食べさせない。(妈妈不让我吃晚饭)
Mom won’t let me have dinner。
可以看到,食べる的る这个最末尾的假名有一定重复的,所以我通过穷举词尾最后一个假名的变形制作了一个mdx文件(即「日本語非辞書形辞典v1」和「日本語非辞書形辞典v2」)——食べら、食べり、食べれ、食べさ、食べま、食べろ等词条全都指向食べる,然后在「日本語非辞書形辞典v3」使用Python和JavaScript根据穷举规则制作2个脚本反向推导原形,并与「日本語非辞書形辞典v2」结果进行对照。(虽然是左右互搏之术,但也有一定的验证价值)
综上,我把我的想法付诸实践后经过长达6个月的实际测试(在论坛有收到反馈),并未发现严重问题。所以接下来会先到沙拉查词上提交PR(沟通会稍微轻松些,再加上我不懂goldendict使用的C++和C),扩大使用人群,观察下实际的效果。
1 个赞
我不想写代码,也不想叫别人写代码就删了。现代的搜索引擎基本都是用这一套词库和形态学分析工具,但都不适合在客户端使用。你能总结改良是很好的,但是最好用大样本测试下,这样客户端开发者那边也会有信心使用。
嗯嗯,我赞同您的观点,要用大样本来验证,单凭人工搜集太慢了(实际上,从有这个想法、开始有意识地收集变形已经是2年前的事,但在6个月前,动手后才发现还是遗漏了很多)。
您推荐的mecab,分词结果中有2列数据就可用来验证对比,但我手上还没有分词语料,所以之前只是简单说明了下
2个月过去了,果然一份文件也没有收到(也许我该专门开个帖子233)
不过我已经找到一台旧电脑了,后面会抽空制作分词语料,预计国庆开始大样本验证。
1 个赞

有什么特别的操作吗,下次可以把报告发上来看下。
暂时没办法修改mac上的异常。
似乎没有特别的操作

需要等到qt6.4.1才能好。
https://bugreports.qt.io/browse/QTBUG-106573
目前是简单处理了下。
嗯嗯 谢谢!!
楼主大神能否
有时间
时
给搞一个
32位版本
先万分感谢了
1 个赞