
我看到最后的“3.0”字样,就完全失去兴致。
看这个说明,完全没有版本学意识。无足观矣,何足道哉。
你看到的不是重点。重点是他们已经根据《订补》和光盘2.0进行了补校,单就你们讨论的“词头”而言总好过从头开始吧。
另外,还有3.44G的图像。
是不是还可以从2.0的在线版抓取数据?
我把 tsiank 制作的《汉语大词典》清晰图像版mdx( https://downloads.freemdict.com/尚未整理/06mdict/汉语大词典清晰版/ )中的索引提取出来了,它是按页码排序的,共363710行,其中最末的10行数据明显是错的,不过不影响大局。谁功力深,可以把这个索引跟印刷纸本或者扫描图像对照复核一下,完善数据。
格式如下:
DCD010001 → 一
DCD010002 → 一一
DCD010002 → 一一行行
DCD010002 → 一二
DCD010002 → 一二三
DCD010002 → 一二九運動
DCD010002 → 一二二一
DCD010003 → 一丁
DCD010003 → 一丁不識
DCD010003 → 一丁點
DCD010003 → 一七
DCD010003 → 一七令
DCD010003 → 一二三四五六七
DCD010003 → 一人
DCD010003 → 一人之下,萬人之上
DCD010003 → 一人之交
DCD010003 → 一人作
DCD010003 → 一人半
DCD010003 → 一人向隅,滿坐不樂
DCD010003 → 一人有慶
DCD010003 → 一人永占
DCD010003 → 一十八般兵器
DCD010003 → 一十八般武藝
DCD010004 → 一九
DCD010004 → 一了
DCD010004 → 一了百了
DCD010004 → 一了百當
DCD010004 → 一人作事一人當
DCD010004 → 一人作罪一人當
DCD010004 → 一人傳虛,萬人傳實
DCD010004 → 一人善射,百夫決拾
DCD010004 → 一人得道,雞犬升天
DCD010004 → 一人得道,雞犬飛升
DCD010004 → 一人敵
DCD010004 → 一人泉
DCD010004 → 一人班
DCD010004 → 一人飛昇,仙及雞犬
DCD010004 → 一刀一割
DCD010004 → 一刀一槍
DCD010004 → 一刀切
DCD010005 → 一下
DCD010005 → 一下下
DCD010005 → 一下子
DCD010005 → 一刀兩斷
DCD010005 → 一刀兩段
DCD010005 → 一力
DCD010005 → 一又
DCD010005 → 一寸
DCD010005 → 一寸丹
DCD010005 → 一寸丹心
DCD010005 → 一寸光陰一寸金
DCD010005 → 一寸心
DCD010005 → 一寸赤心
DCD010005 → 一干
DCD010005 → 一干一方
DCD121512 → 龜孽
DCD121512 → 龜寶
DCD121512 → 龜熸
DCD121512 → 龜燋
DCD121512 → 龜疇
DCD121512 → 龜縮
DCD121512 → 龜縮頭
DCD121512 → 龜繇
DCD121512 → 龜繩
DCD121512 → 龜艨
DCD121512 → 龜藏
DCD121512 → 龜藏六
DCD121512 → 龜蟲
DCD121512 → 龜辯
DCD121512 → 龜鏡
DCD121512 → 龜顧
DCD121512 → 龜鵠
DCD121512 → 龜齡
DCD121512 → 龜齡鶴算
DCD121513 → 龜籙
DCD121513 → 龜鑑
DCD121513 → 龜鱗
DCD121513 → 龜鶴
DCD121513 → 龟
DCD121513 → 𪚮
DCD121513 → 龜
DCD121513 → 龜
DCD199458 → 𨀛
DCD下腳3 → 下脚3
又
又且
又作別論
又及
又弱一个
又生一秦
又紅又專
又道是
《漢語大詞典》清晰图像版mdx - 按页排序索引.txt (7.9 MB)
想抓这个数据的人多了去,谁成功了?我个人对这些创纪录放卫星的词典其实兴趣不大,论坛很多人在谈,凑下热闹而已。即使抓数据,我连账号也没有,也不想去注册。
有足够的数据,足够的算力,机器也许能够编更大更全面的词典。比如说,一台超级计算机拥有了爱如生的全部数据,超星的全部数据,CNKI的全部数据,然后,1)提取数据库的全部单字;2)将数据库的全部文献基于《汉语大词典》既有的词组分词,提取所有独立词组,未包含于《汉语大词典》的词组另立新条目,并对其验证(比如需要两条以上的独立书证,也可以适当专家人工介入辅助);3)从数据库里挑选适当数量的例证(怎么挑选,可以设计一套算法);4)用聚类算法对某一词组的多个词义进行分类;5)汉语词典释义其实属于语言内部翻译——从古文翻译成现代汉语,可以借鉴成熟的双语翻译系统,用AI自动给2)生成的词组释义;6)再次专家介入校订机器生成的释义。
有这么一套系统,个人独立研编一套比《汉语大词典》更全面更准确的词典也并非不可能,像《大汉和辞典》,“5万汉字、53万条辞汇”,其主力也是諸橋轍次一人而已。不过好消息是,汉语大词典出版社也是爱如生什么《中国基本古籍库》的买家,但愿其第二版可以做得更优秀一些。
清晰圖像版mdx有一群字頭用【】標的,敘列部件來代表字形,我記得大多可以用部件檢索補充。
谢谢,不过能把体例说明一下可能更佳。

图像无法加载什么原因?
那些“0”开头的字词具体含义是什么,有的在文字版、图像版的索引里都没有,有的能在文字版中查到。
一般是纸书没有只有文字版有的
很多是这种情况。不过我随机搜了几个字词,像“骮、朚倀”文字版、图像版都没有。
按照哪個筆畫的數據?
用金山表格排的,excel也有笔画排序功能
把你的css用于汉语大词典,很帅,多谢!只不过兼容性有待解决,正在学习中。
有啊,你举这两个光盘版都有啊,你上面发那个没有?

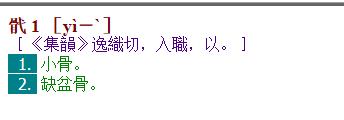
我说的是这里的纯文本版,你那些“光盘版”mdx被人改得不像样了。
下面那个图是我自己转制的,是光盘2补充光盘3,没有乱改。我回去了看一下真正的光盘2,看到底有没有。上面那个我个人觉得也不错,有不少手工添加的,也有不少对图像版条目的更正。