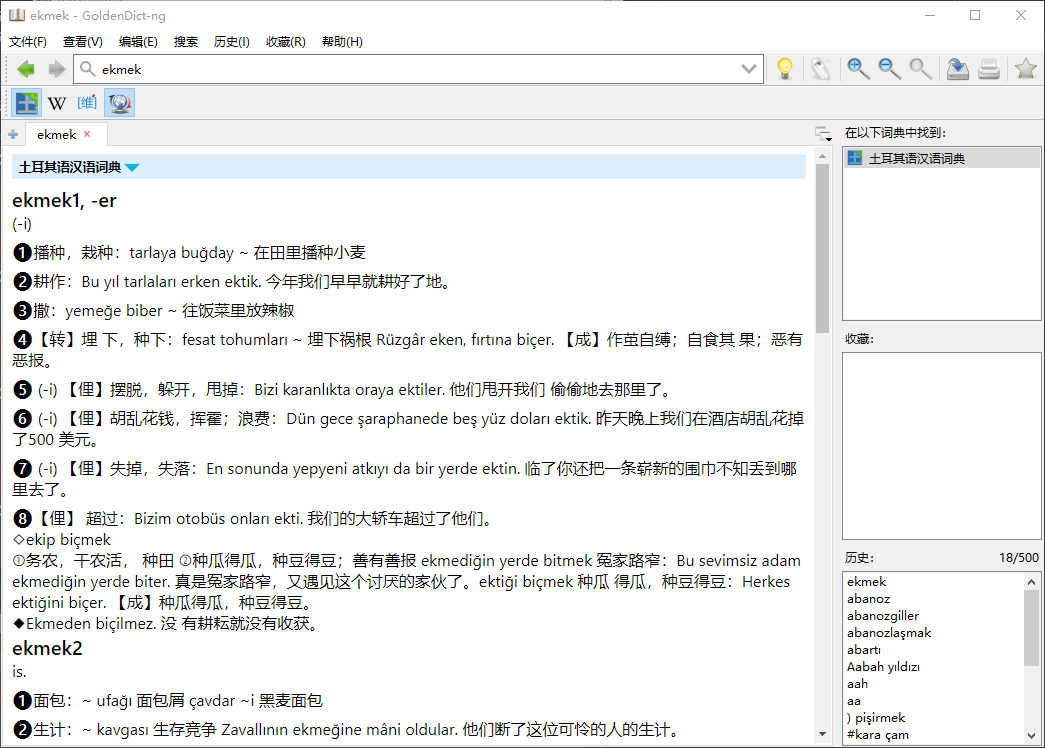
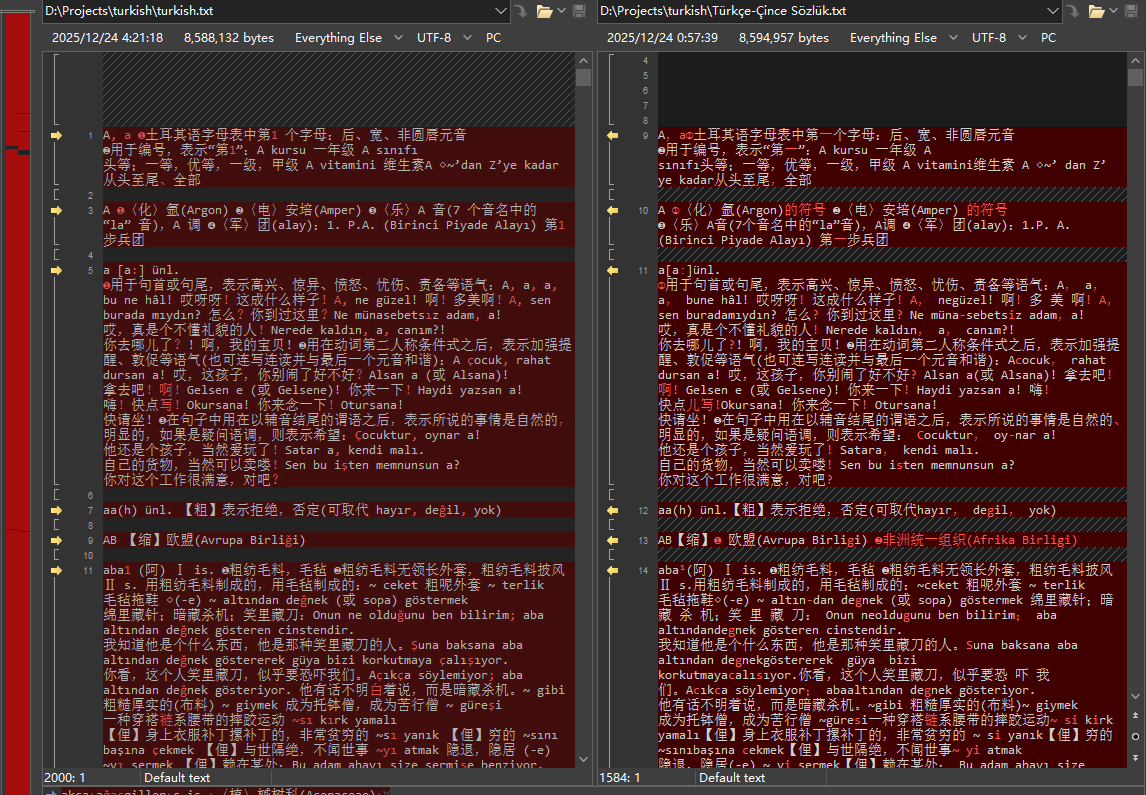
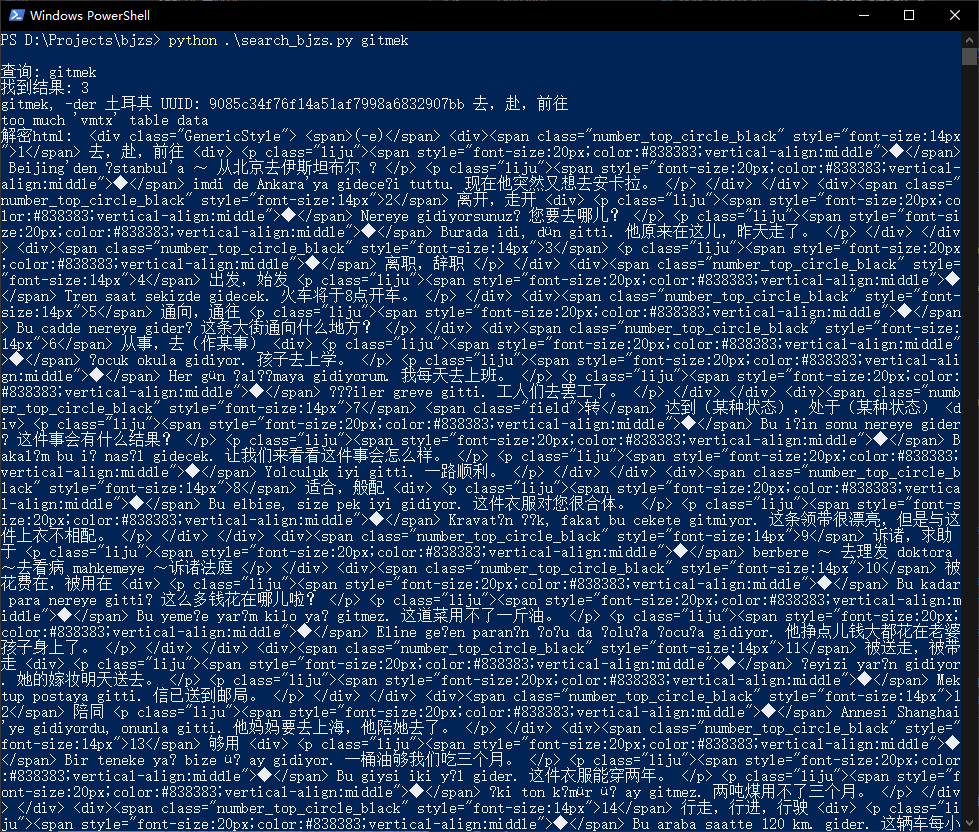
本词典和《意汉词典》情况一样,有文字版pdf,但和pdf扫描版有差异,可能是出版社的草稿。我把这个转换成了mdx,然后用夸克识别了pdf版。 如果要进一步完善需要对比两个版本的文本,另外没有加精细的标签和做复杂样式处理。
版本差异:
mdx文件:
土耳其语汉语词典.mdx (4.4 MB)
TurChiDict.css (180 字节)
pdf版夸克ocr结果:
Türkçe-Çince Sözlük.docx (6.7 MB)
转换后的json数据:
turkish.zip (5.7 MB)
5 个赞
这个不像OCR的,文本内容有差异,但是特殊符号都正确,OCR的文本应该正好反过来。另外我都让AI写了个下载还原编辑助手数据的代码,但发现他的数据把土耳其语特殊的字母都直接用问号代替了,基本无法还原了。
1 个赞
amob
4
除此之外,很多词典标签错误,文字错误也多,商务的程序员水平很差,没有正确处理原始方正书版排版文件,没有考虑特殊情况和自造字,一看就是一个批处理弄的。
俄语词头本身有问题,然后数据里面俄语也不对,估计是搞了随机替换但俄语字符又没包含在字体中。希腊语对特殊符号处理有问题,按词典词头基本查不到结果,还要对注音符号很麻烦。韩语显示的韩中词典但我对比了纸质版发现内容不一样,不知道实际是哪本词典的数据。而且速度很慢查一个词要几秒,感觉除了希腊语这种ocr容易出问题的语言其他的还不如ocr校对方便。