手上的是5本日语词典的数据库文件,我试着用python转换,但效果不理想,望论坛高手指点,或帮忙转换一下,再分享给大家,愿为论坛出一份力,感谢大家的付出和分享。
感谢hua、 last_idol、 mdict6、 增上慢、 winn几位大神的付出,现已有一本词典成形,见25楼winn大神的分享。请尊重大神们的劳动成果,仅供坛友们交流学习,不要买卖和商用,版权归词典出版商,否则后果自负。
论坛真是高手入云。

辛苦大神了,我转出来的好多对不上,词条和语音,跟着chatgpt操作的,还是希望大神们帮忙搞个美观完整正确的版本,再分享到论坛,在论坛下载了很多有用的词典,辛苦了!
HTML 模板 + CSS 样式表 + PNG 图标:
html+css+icon.zip (273.8 KB)
索引的结构设计也很好。(对日文搜索不了解的很值得参考
谢谢大神的分享!
这五部词典真是让人垂涎欲滴。日语叫做“喉から手が出る。”期待大佬出手做成mdx词典,为坛友带来福利。期待!!!!
没有直接打包,词头需要清洗和二次提取,链接需要批量替换,都需要熟悉日语词典制作的作者来处理,链接现在只能保持 7 天。
密码: free
大神辛苦了!谢谢!
这个盘下载速度可以
把last-idol哥哥提供的解压后,得到五本词典。
试着打开一本词典可看得到两个文件,如下图。
- 用em-editor打开txt文件,替换关键词
</html>为\r\n<\>后保存。 - 用everything.exe批量修改文件格式。

- 用上面的txt和文件夹生成mdx和mdd
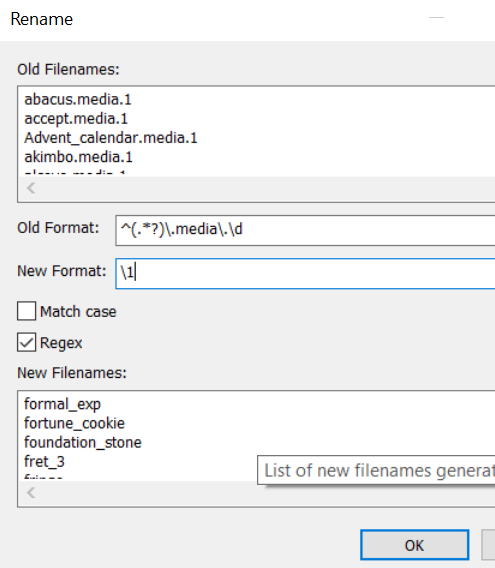
剩下的问题
是需要词典重度用户解决如下问题。
- 日语词典肯定需要词头扩充,不扩充就不好用。
- 目前的txt里词头位置包含有加粗、倾斜、图片、不可见的私有字符等,需要处理
- 制作mdd对应的文件夹内,附件有3种格式,批量修改很快。
.media.1 是jpg
.media.2 是png
.media.4 是svg
制作完成后还需要坛友们测试捉虫。

gofile.io 打不开,可以帮转度盘吗?有空试试。
你要接手制作吗?是的话我可以转存一下。
我先看看是否有能力制作,如果只涉及正则表达式和简单的程序,是可以制作的(太复杂的、需要耗费大量时间除外)。
你看上面的回帖呢,需要热情去处理词头、词头扩容、以及锚点跳转
好的,我是好奇……没学日语。
通过百度网盘分享的文件:obunsha5…
链接:https://pan.baidu.com/s/1PezSzKK2CG5orUj7PHNq_w?pwd=free
复制这段内容打开「百度网盘APP 即可获取」
日语词头里有不同符号,需要先了解下才知道怎么拆分词头。