最近被封在家里,花了一点时间琢磨了一下用Python下载Forvo网站读音的问题,已经搞定,下面分享一下过程。
import uuid
import requests
import os
from bs4 import BeautifulSoup
# 设置一下headers
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
def download_forvo(word, lang):
# 单词搜索的链接, 语言代码见后
url = "https://forvo.com/word/" + word +"/#" + lang
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'html.parser')
# 找到目标语言的容器
lang_container_name = 'language-container-' + lang
language_containers = soup.find_all('div', {'id': lang_container_name})
for lc in language_containers:
# 找到有onclick属性的span标签
for span in lc.find_all('span', onclick=True):
if 'Play' in span['onclick']:
# onclick属性用逗号分割后,第2个是mp3, 第3个是ogg
splits = span['onclick'].split(',')
if splits[-3]:
try:
# 用base64把地址解码
result = base64.b64decode(splits[1]).decode('utf-8')
except Exception as e:
pass
else:
# 地址前缀
mp3_url = 'https://audio12.forvo.com/mp3/'
if result:
mp3_url += result
audio_bytes = requests.get(mp3_url, headers=headers).content
if b'html' not in audio_bytes:
# 这里是把读音下载到下载文件夹里
file_path = os.path.join(os.path.expanduser('~'), 'Downloads', uuid.uuid4().hex + '.mp3')
with open(file_path, 'wb') as f:
f.write(audio_bytes)
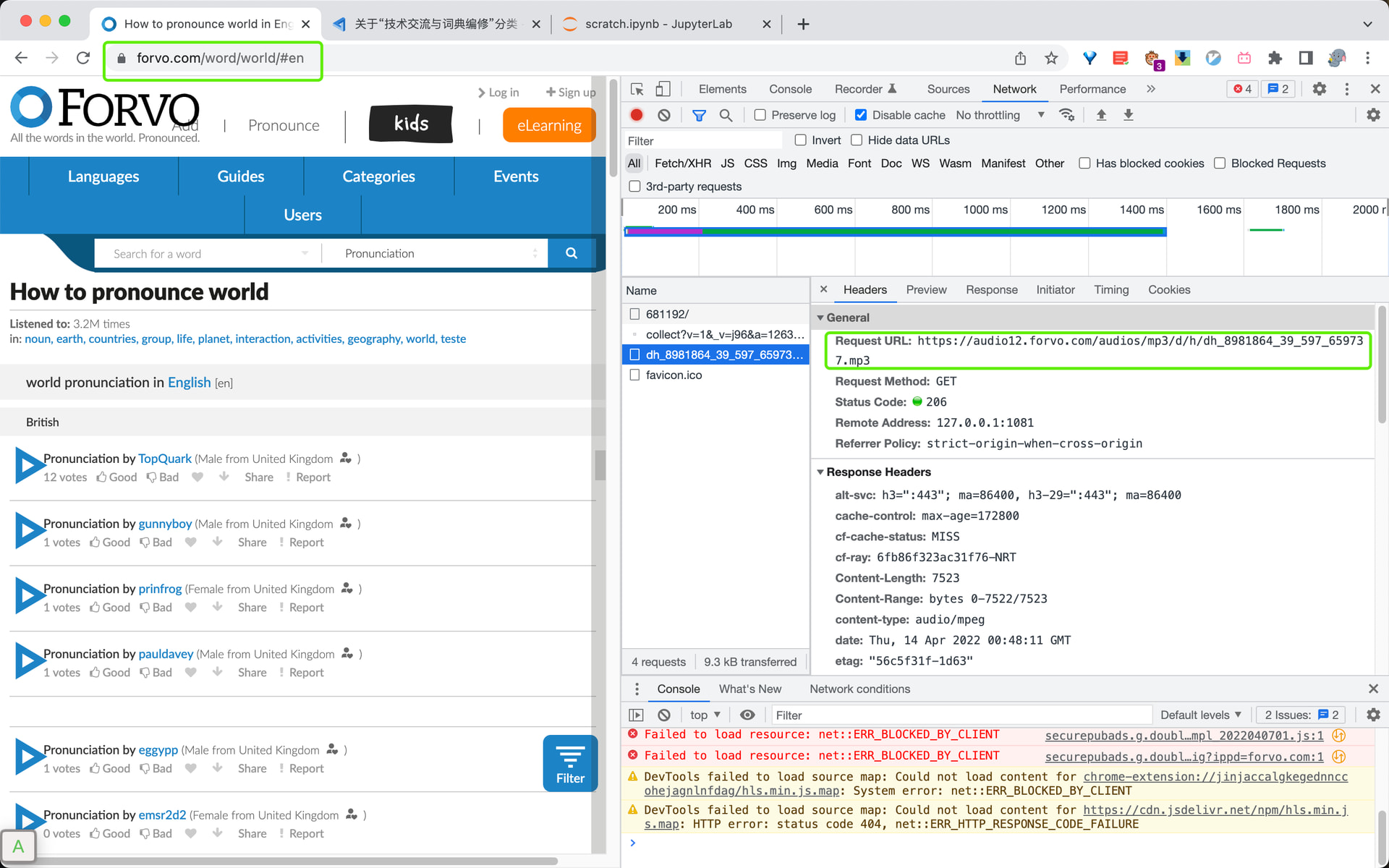
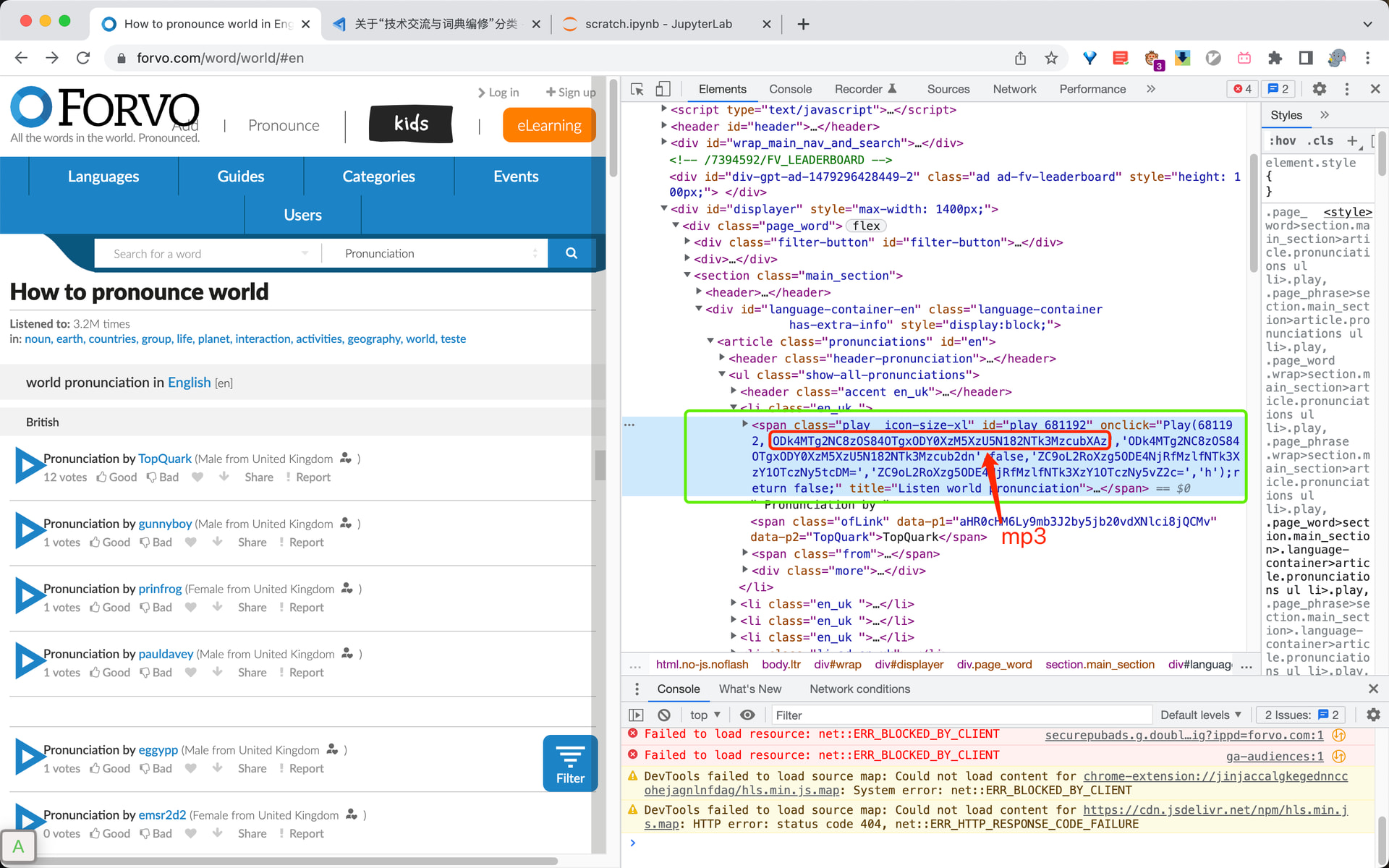
查看网络就可以看到点击读音时,浏览器实际向Forvo网站提交的音频地址,地址中mp3之后的部分就是存储在onclick属性中,用base64解码就可以得到。
希望不要大批量的爬取,会增加网站的负担,根据实际需要适当下载。实际的操作不需要把一个词条的所有读音下载下来,可以找到票数最高的,或者找到自己喜欢的发音者。
https://api.forvo.com/demo/ 网页中,language里面可以查看语言的代码。