这个是大陆国图的网上古籍资源库,可以免登录在线阅览。
中华古籍资源库http://read.nlc.cn/thematDataSearch/toGujiIndex
全国汉文古籍普查工作基本完成,总量达270余万部,资源分布和保存状况基本摸清
7 个赞
“高级检索”选项里的“中华古籍联合书目”打成了“中华古籍联合数目”。希望有人看到我这个吐槽,让网页管理员改一改。
检索书目没问题,用简体字可以检索到繁体字。
检索之后,看个石刻拓片或年画图片,也不成问题。
但是假如想打开数字古籍,网络阅读器开启后,就只出现一些波浪形的图案。是在叫我耐心等待吧?
但是像“等待果陀”那样,没有结果。
曾经在等待完后打开过“数字方志”。但是这个速度够糟啊!难道是我这里网络连接速度的问题?
abs
2021 年12 月 14 日 07:49
4
和速度有关系,也因为电子书文件太大了,他加载的时候是PDF文件,是分章节加载的,《泉州府志》是20m,《 东瀛佛教》这本是70m,后面这本我也等了很久。
abs:
他加载的时候是PDF文件
你怎么知道原来的格式是pdf?
难道你的电脑能同时显示文字和图像?我这里无法显示图像。
看着像资料库里的资料重新格式化。
我也看不到文件大小。难道你是登录后使用?
abs
2021 年12 月 14 日 08:22
6
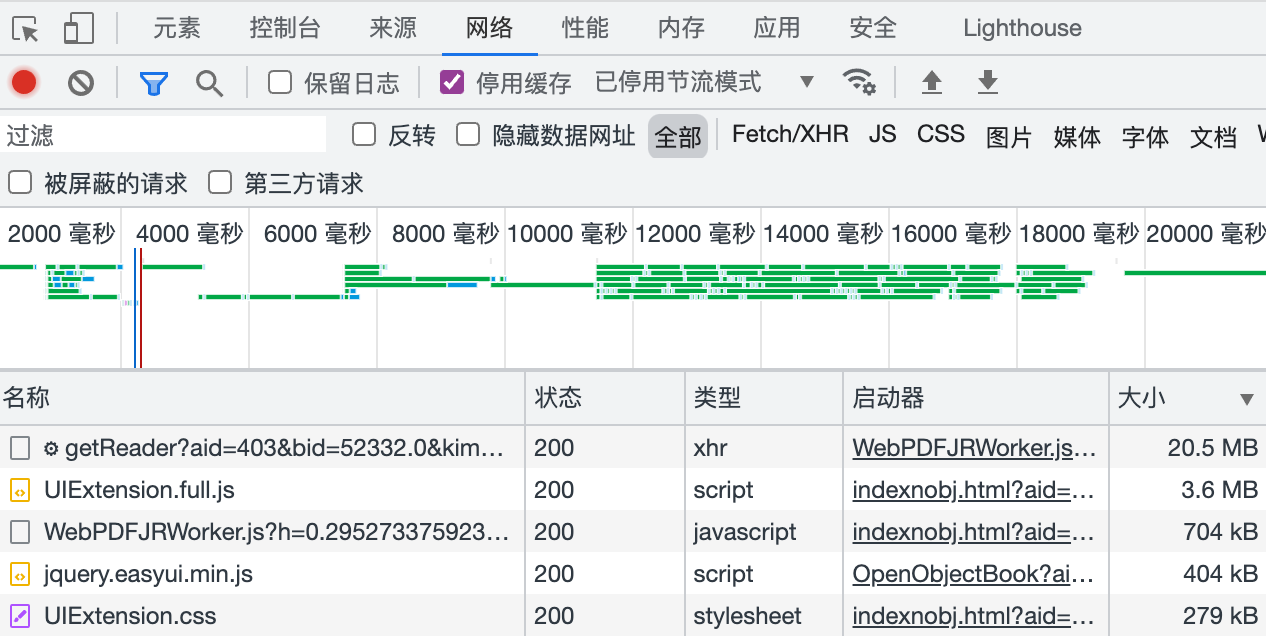
我是登录的,只能看到图像。我是想保存图像,发现不能点击右键,用Chrome的开发者工具看,在网络这一项,重新刷新页面,可以按大小排序,最大的那个就是下载PDF的链接,这个链接的名称是WebPDF,但是右键链接仍然没有保存项。
2 个赞
看到的东西完全不一样。也许登录后的速度比较快。或者大陆内用户优先,速度较快。
按照我这边使用的速度,这个资源库就对我没什么用,还不如哈佛的ctext好用。
其他网上古籍资源库可以参看:
国图等6家联合发布古籍数字资源
古籍全文檢索
网上古籍随见录
2-12-2022
本坛现在有一个书友自建的全文检索系统:
古籍全文檢索
也有繁体的《四库全书》文本 。
大陆网盘我无法使用,纯粹利人,看到可能有用的链接就顺手发,不过无法验证,不知道是否真能用。
辟雍堂:
宋会要辑稿,文献通考,册府元龟,通典,点校本,全部ocr,pdf (百度盘)
宋会要点校版 (阿里盘)
17-10-2022补充
“点校本”+ocr,看着像国学数典度盘售卖…
4 个赞
我现在练习查询书目,记下步骤。这样才能帮助有同样需要的人。
一、搜索国图书目
1.去国图的“中华古籍资源库”:
2.点按“高级检索”。
3.点一下“反选”,清除其他选项。
4.选择你要查的书目,打勾,例如:
4.在“标题”中键入书名,把选项的“模糊”改成“精确”,然后点按下方的“检索”。
假如国图没有某书的电子书,可以尝试在以下网站找电子书:
1.Ctext
按:在左边下方找“Title search”。可以用简体字。
Ctext应用举例:《御定全唐詩》(《摛藻堂四庫全書薈要》本)
2.HathiTrust Digital Libraryhttps://catalog.hathitrust.org
“HathiTrust”
3.哈佛电子书检索https://hollis.harvard.edu/primo-explore/search?vid=HVD2&sortby=rank&lang=en_US
4.日本国立公文书馆检索
日本国立公文书馆有《内阁文库》,可以下载。
参看:
内阁文库的电子书怎么下?
日本所藏中国古籍——网站集锦
陆续增加其他网上资源:
古音小镜的资料检索
梳理了顶楼“古音小镜”训诂书检索可以通检的书目:
說文解字詁林|丁福保[民國]
說文通訓定聲|朱駿聲[17世紀]
爾雅詁林|朱祖延[1998年]
鄭玄辭典|唐文[2004年]
虛詞詁林|謝紀鋒[2015年]
廣雅疏證|王念孫[淸嘉慶元年刻本——这个我没见过m-dict
揚雄方言校釋匯證|華學誠、王智群、謝榮娥、王彩琴[2006年]
經籍述聞|王引之
故訓匯纂|宗福邦、陳世鐃、蕭海…
台湾中央研究院的“汉籍电子文献资料库”http://hanchi.ihp.sinica.edu.tw/ihp/hanji.htm
浙江大学大型文献信息库(丛书总目)http://csid.zju.edu.cn/doclib/books
1 个赞
國圖的中華古籍資源庫的文件可以用工具下載,工具發佈在“書格”網站交流區,新版沒下載,舊版分享:链接: https://pan.baidu.com/s/14pz0Y7_GqYebZL4hyKd7kQ?pwd=3a3a 提取码: 3a3a 复制这段内容后打开百度网盘手机App,操作更方便哦
2 个赞
amob
2024 年1 月 19 日 04:28
11
这种内置pdf阅读器的网站很多,你要分析下网站源代码找到原始pdf地址,一般很简单比如读秀和悦读,当然会有混淆比较多的。下载到的pdf是单页的,之后拼接在一起即可。
1 个赞
中华古籍智慧化服务平台
网站简介
中华古籍智慧化服务平台”是由国家图书馆牵头,联动全国古籍收藏单位共同建设,为社会公众提供开放共享、全面多元的古籍资源和科技赋能、便捷高效的知识服务的古籍领域智慧服务平台。
“学习工具”里有“在线词典