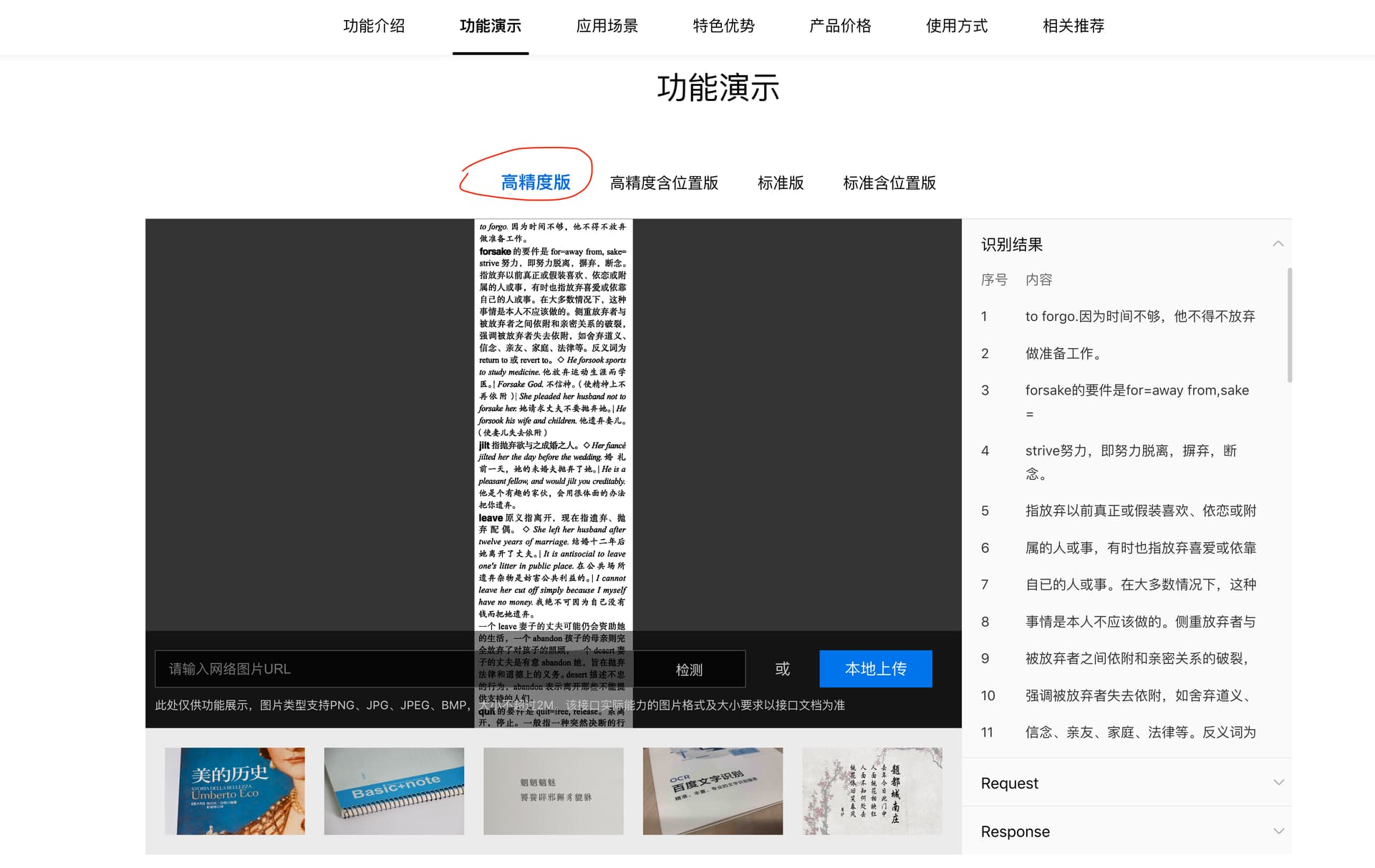
废话少说, 先看效果, 打开百度 ai 的开发首页, 拉到下面有个功能演示模块, 可以上传本地图片让它识别看看
最近在 iPad 上入了一款专门针对国内扫描版 PDF 的阅读笔记软件 Marginnote3
发现他的另外的 pro 付费功能的 ocr 文字在线矫正识别用的是百度通用文字识别 (软件自带基本的文字识别是 abbyy 的引擎)
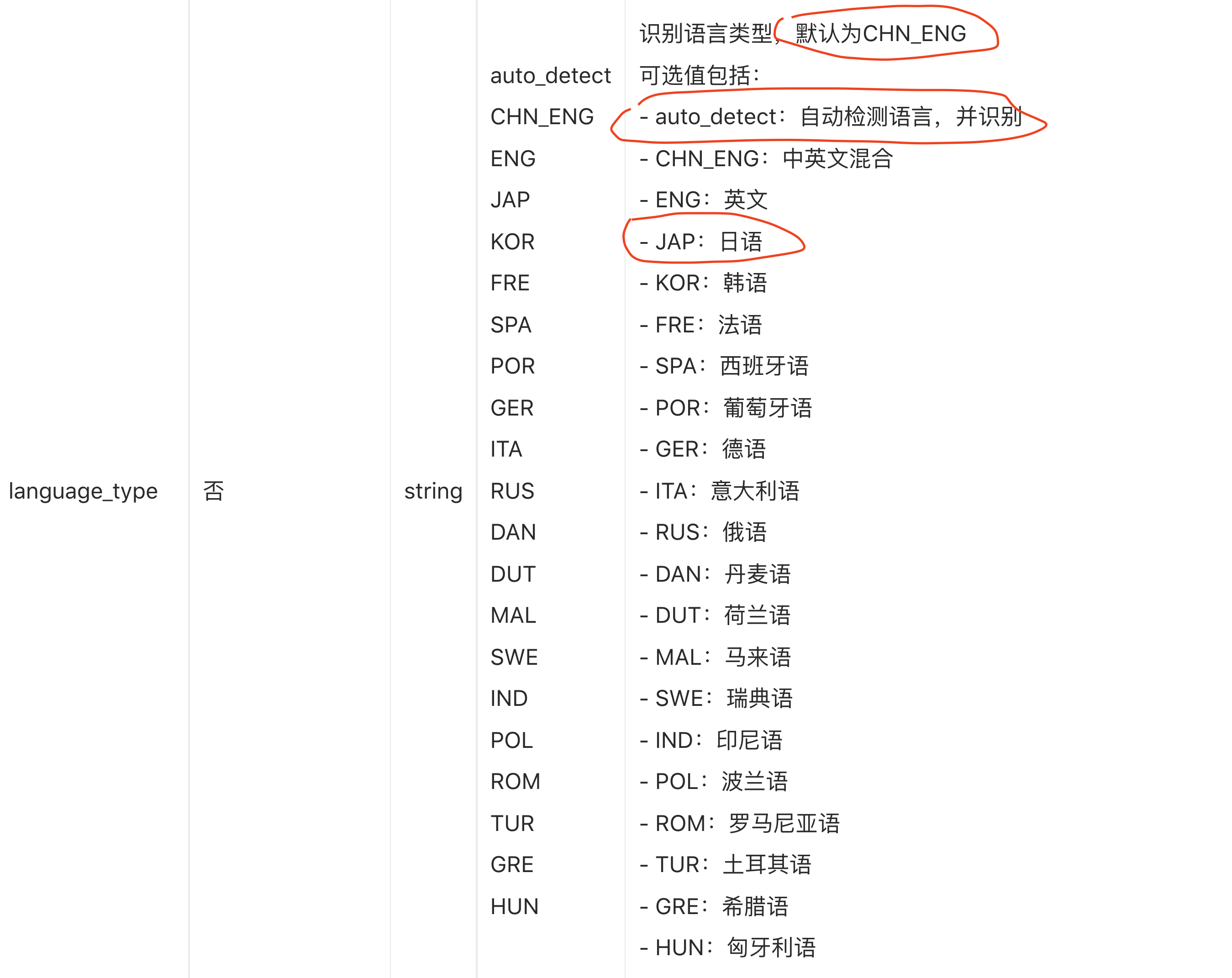
然后发现这个百度的中英文 ocr 识别准确度惊人的高, 基本上只有个别逗号句点和偏僻的符号的识别可能会出些小偏差, 大部分时候, 基本全对
然后就顺藤摸瓜去百度的开发者网站去看, 发现百度提供了各种文字 ocr 识别的 API, 并且看看他的入门教程, 很简单就能上手
可惜, 据说他的 ocr 识别的 API 大半年前还基本上约等于免费 (普通识别每天5万次, 高精度的每天500次免费), 不过现在开始大力收费高精度的每月只有 1000 次免费额度, 然后每万次收费268元 (相对于阿里和腾讯还略便宜些)
当发现有约等于100%的识别精度的 ocr 时, 就突然想把一些经典的权威的扫描版的好书给它文字化了
但是这收费和每月只有1000次的限制还是让我抓心挠肝的, 各种寻找替代品, 最终发现那些开源的可以本地化使用的 ocr 引擎(比如飞桨, pearocr) 其中英文混合识别能力终究还是比百度这个在线高精度略逊一筹, 要知道大篇幅的 ocr, 识别精度稍差那矫正就要花上几何级递增的精力
正在有些感叹没赶上半年前的好时候的时候, 发现百度有个双11优惠, 新人可以1元买个1万次的高精度识别包, 好吧, 1万次相当于1万张图片识别了, 再加上每月1000次的免费额度, 短期内应该可以满足了
有 ocr 高精度识别需要的朋友可以趁这个时候花1元钱撸一把
就在这个网站首页上半部分有一行黄色醒目文字提醒1元1万次
绝非推广, 各位兄弟有备无患吧
拿下这1万次然后有机会大家可以利用这个合砍他几大本好书岂不快哉