TIO 完整数据库下载,其中包含了以下四个表:
c2e_simple_idx ,提取了ESL双解词典的英文解释、中文释义,共计 260,915 条
ec2_idx ,最核心的中英双语权威例句,共计 3,895,294 条
ec_simple_idx,单词词组的简明释义及大量专业词汇, 共计 3,282,538 条
eng_extra_idx,作为补充的纯英文例句,共计 15,126,967 条。根据平时的对比查询,这部分内容要胜过有道、必应之类的在线词典,不少词汇的查询结果甚至优于ludwig或者skell。
使用说明( 以Linux系统为例)
1.下载数据库文件 tpm.tar (MD5: d5b92327c16f8945dcbc2c45ca0745dc) 并解压至自定义目录A,需要约11G磁盘空间。
下载链接: https://pan.baidu.com/s/1lL8GarQPwdbAs336--_3bg 提取码: 4gpc
-
根据自己的操作系统,下载、安装SphinxSearch 3.4.1 到自定义目录B。 http://sphinxsearch.com/downloads/current/
-
在第一步的自定义解压目录A中,创建sphinx.conf文件。注意修改 path 参数。有报错可以对照在线文档: http://sphinxsearch.com/docs/
index c2e_simple_idx
{
source = c2e_simple
min_word_len=1
ngram_len = 1
ngram_chars = U+3003..U+FF0B,U+FF0D..U+2FA1F
path = /usr/local/tpm/c2e_simple_idx
hl_fields = body
docstore_comp = lz4
docstore_type = vblock
stopword_step =0
}
index eng_extra_idx
{
source = eng_extra
path = /usr/local/tpm/eng_extra_idx
ignore_chars=U+3002,U+FF0C
morphology = lemmatize_en_all
hl_fields = body
docstore_comp = lz4
docstore_type = vblock
stopword_step =0
}
index ec_simple_idx
{
source = ec_simple
min_word_len=1
ngram_len = 1
ngram_chars = U+3003..U+FF0B,U+FF0D..U+2FA1F
morphology = lemmatize_en_all
path = /usr/local/tpm/simple_idx
ignore_chars=U+3002,U+FF0C
hl_fields = body
docstore_comp = lz4
docstore_type = vblock
stopword_step =0
}
index ec2_idx
{
source = ec2
min_word_len=1
ngram_len = 1
ngram_chars = U+3003..U+FF0B,U+FF0D..U+2FA1F
path = /usr/local/tpm/ec2_idx
ignore_chars=U+3002,U+FF0C
morphology = lemmatize_en_all
hl_fields = body
docstore_comp = lz4
docstore_type = vblock
stopword_step =0
}
indexer
{
mem_limit = 512M
}
searchd
{
listen = 127.0.0.1:9312
listen = 127.0.0.1:9306:mysql41
thread_stack = 512K
log = /dev/null
pid_file =/tmp/search.pid
}
-
使用自定义目录B下的searchd命令启动服务。例如:
searchd -c sphinx.conf。启动后可以直接使用mysql -h0 -P9306连接到SphinxSearch。 -
数据的查询和展示,以python+flask为例。保存以下代码为sample.py。sphinxsearch兼容MySQL协议,因此有编程经验的朋友应该很容易用其他语言写出更高效的代码。
from flask import Flask
import pymysql
app = Flask(__name__)
def Sorting(lst):
lst.sort(key=len)
return lst
@app.route("/<word>")
def sample(word):
body = "<style>.pg_exam { padding-top: 0.3em; color: #4c4e56; display: inline-block; } .hl { color: red; } </style>"
db = pymysql.connect(host="0", user="",password="",port=9306)
cur = db.cursor()
sql = "SELECT snippet(body, %s, 'limit=5000','around=2000','before_match=<span class=\"hl\">','after_match=</span>','force_all_words=true') FROM ec2_idx where match(%s) limit 100"
cur.execute(sql,('"' + word + '"',' @body "' + word + '"'))
exact_rows=cur.fetchall()
tio_list=[]
if exact_rows:
for exrow in exact_rows:
current_body= '<class="pg_exam">' + " ‣ " + exrow[0] + "</span>" + "<br />"
tio_list.append(current_body)
msg = "".join(Sorting(tio_list)[:50])
return body + msg
else:
return "Keyword not found"
-
启动服务。 export FLASK_APP=sample ; flask run --host=0.0.0.0
-
通过 http://127.0.0.1:5000/<中英文单词> 来直接访问,如果你使用GD,本地可以直接配置网络词典为: http://127.0.0.1:5000/%GDWORD% 。至于样式、字体等等大家都可以根据自己的喜好在代码中自行调整。
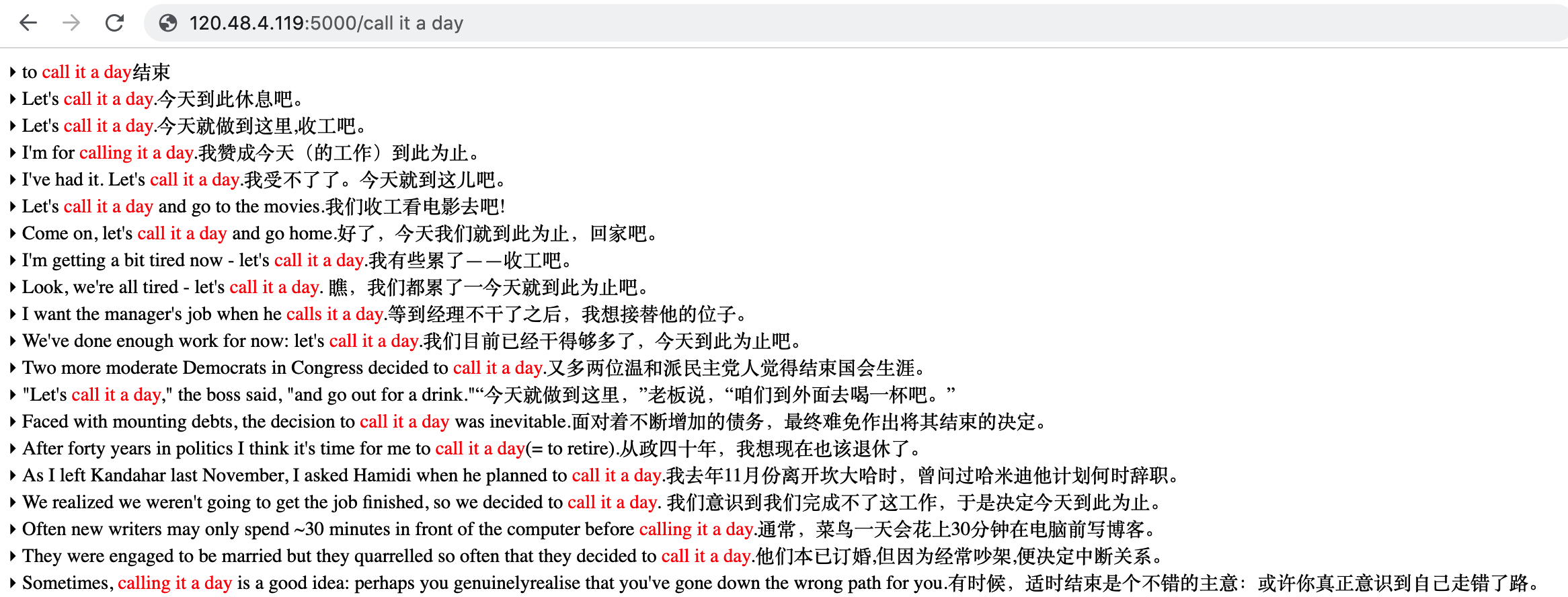
基于以上的数据,你可以:
-
打造离线版本的TIO词典
-
打造一本基于目标词汇,适合自己、适合特定对象、用于特定目的的个性化词典
TIO数据库中的内容虽然都来自互联网,但收集、抓取、清洗、整理却颇为不易,严禁任何人用来作任何形式的盈利。