还是上半部分存在遮挡,已重新下载过顶楼文件
不过问题不大,因为图片版很少看
不好解决的话就算了
1.14版,我在 MDict PC 和 Dict Tango 試驗了,都正常。(Dict Tango 能夠在主界面展開同源字典圖像;MDict Android app 不行。)
我最近盡量把我作的不同CSS統一起來,有時CSS改了但HTML沒跟上來,現在毛病應當解決了。
2 个赞
越来越完善了。谢谢精心制作
希望总结一下相关技术,发帖授之以渔。
例如,保持了私有區![]() 字形,而掛在“猣”字上(拷貝出來就是“猣”)。“猣”是在UTF-哪个范围里头的?如何实现私有區字形、拷貝出來是UTF中的某字?
字形,而掛在“猣”字上(拷貝出來就是“猣”)。“猣”是在UTF-哪个范围里头的?如何实现私有區字形、拷貝出來是UTF中的某字?
如何判断一个大段文本里头,属于某个字符集外的字符,如何把这个小子集的字形从“全宋体”或中华书局字体里头提取出来?这样,该大段文本配合这个小子集的字形即可使用。
1 个赞
估計沒多少人對字型技術感興趣。感興趣是說願意花功夫去做。
如果不打算继续研究了,有时间的话不妨整理一下技术路线
也是个阶段性总结备忘哈
后面应该会有人有兴趣继续摸索的
谢谢分享,收藏备用
3 个赞
楼主发布mini字体时,我惊叹于楼主的技术,于是Bing了一下。
【工具】在TTF字体中提取想要的文字,让字体文件变迷你_晴天的专栏-CSDN博客_ttf导出文字
如何从字体包中提取出指定的文字 - 简书 (jianshu.com)
不知楼主是不是用的相同的技术。
愿意动手的怕是很少了,有能力又愿意做的可就凤毛麟角了。像我,不过一好龙之叶公。
私有區字形拷貝出來是UTF中的字形
这可能是楼主的独门技术 ![]()
3 个赞
沒用過那個工具,好用嗎?
我摸出來的方式是把字型輸成UFO (Unified Font Object)各式,等於把字型拆分,每個 glyph (字形) 分成一個文件。這樣方便操作,不用學任何字型軟件的 API scripting語言,直接寫個 Windows batch file 就能把你要的字(準確來說是 Unicode codepoint)拷貝到新的UFO文檔。然後再轉成ttf/woff.
提前要準備字典的 codepoint 字單,這步跟寫.bat 的步驟是用EmEditor macro來處理的。這過程本身有價值,比方說我昨天發現辭源文字版有二十多(不該有的)當代簡體字。目的不僅是作個 minified font,分析數據更重要。要找出所有私有區字、不規範的字、廢掉的字碼(例如淘汰的香港兼容字),也得過這一關。總之,處理字型跟修理文本是分不開的工作。
1 个赞
惭愧惭愧,我没有实际操作过,找时间试试您的方法 ![]()
之前修订《英文字用法指南》的时候,在知道HKSCS的Unicode范围后,我用EditPlus手工逐个找出其文本中HKSCS字符的清单
批量处理看来还是要用EmEditor类似的专门文本编辑器的macro更好,或者上Java代码。
有机会开个专门的总结帖子就更好了,列举一下这些字符的Unicode范围、具体的macro代码,如何把字型拆分、使得每個 glyph (字形) 分成一個文件?等等
1 个赞
您好!我也同时使用了王力古汉语字典2000和王力古汉语字典文字版,但这两个字典的css似乎会产生冲突,同时使用时后者的粗体会一概消失。我在GD中尝试把两个字典分到不同的组别后问题就解决了。想问问您是否也遇到了同样的问题?
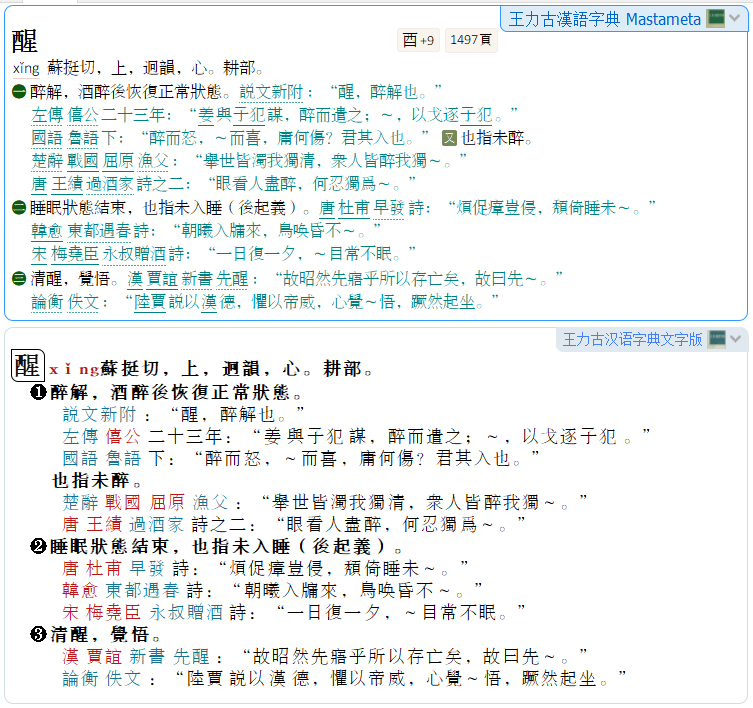
啊感谢回复!我目前用的也是499,下载了ru-board的499/qt5.12.3的64bit版本,其余文件用了372版本,不过可能是我自己没有设置好的缘故(这几天刚刚开始学用,所以操作还有点生疏。同时查询的话界面就会像这样子w 不过是可以接受的小问题,就不管它啦
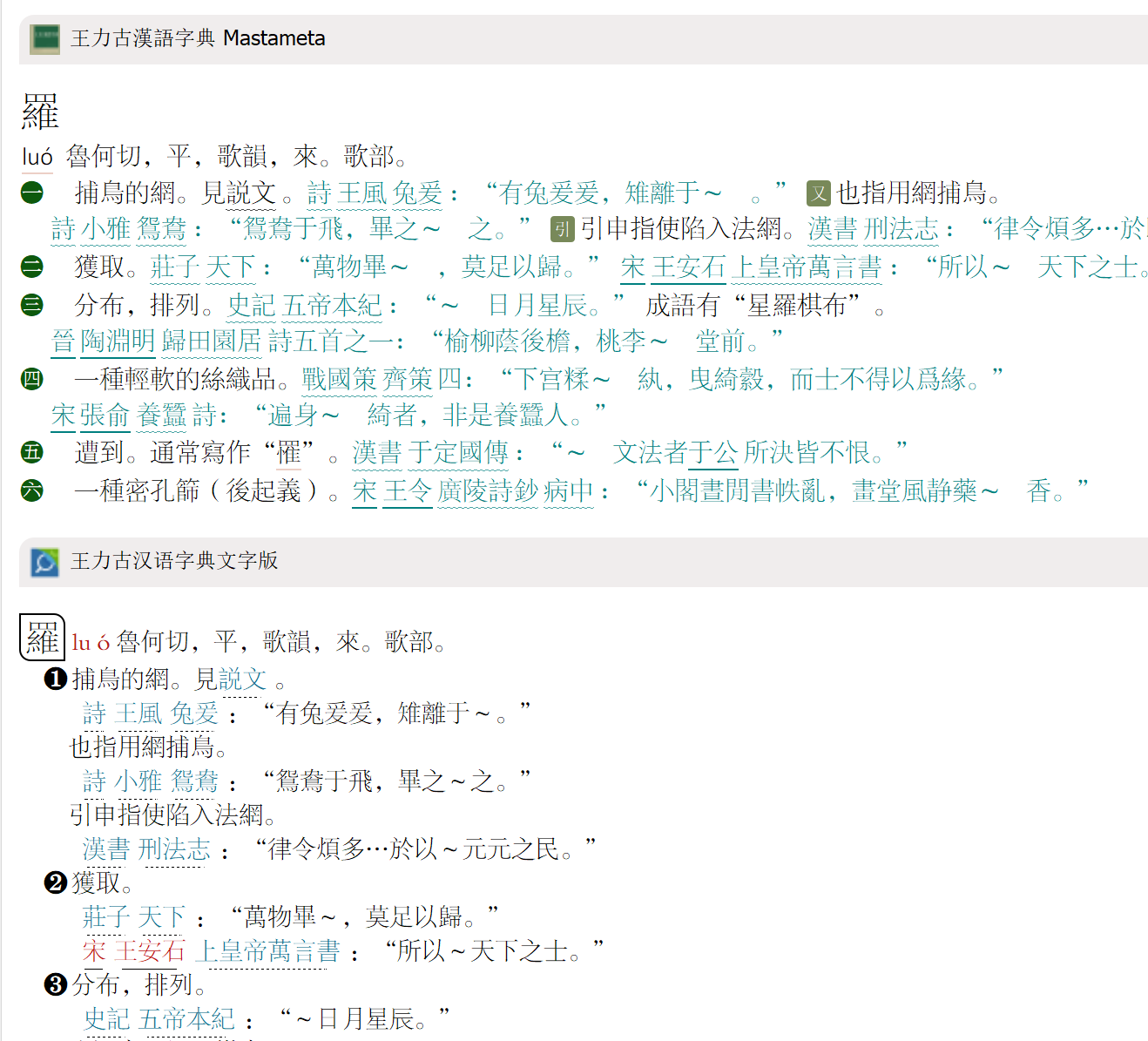
1 个赞
试着用楼主方法去制作,结果第二步就卡住了 ![]() 这玩意太难,大约不是我这个老菜鸟能玩得转的,我还是安静地做个伸手党吧。
这玩意太难,大约不是我这个老菜鸟能玩得转的,我还是安静地做个伸手党吧。
不,不止安静,还可以吹毛求疵,刷刷存在感 ![]()
今天有点时间,吹了若干下。
刀部:總論
……只有少形容詞是關於刀的質量的。(只有少数,漏了“数”)
力部:總論
凡與力所氣、力量有關的事物多从力。……(凡與力氣,多了“所”)
又部:總論
……“又”既是手,所以又部的字多與手有關。(图像同。“既”是“即”吧。)
囗部:總論
有两个简体字“币、墙”(显示黑体),图像同。
大部:總論
![]()
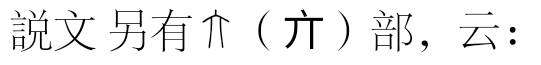
字型看着不一样
女部:總論
姞。(列举了这个字,却没有字头?)

弓部:總論
彍(張满弓弩)——(满→滿)
方部:總論
……説文也收人㫃部,云:“旗皃。”(收人→收入)
欠部:總論
……因倦时舒氣有一種舒服感,(时→時)
水部:總論
……这些字説文都在水部。(这→這。同词条内还有“這”字,却是繁体。)
糸部:總論
……㈥由加染形成的各種颜色。(颜→顏)
老部:總論
老部的字全都是表示年龄大的:……(龄→齡)
耳部:總論
……㈠關於聴覺或聴覺的好壞的。(聴→聽)
艮部:總論
……现歸在艮部的字,意義上無關繫。(现→現)
色部:總論


8画的字型不正确
艸部:總論

未能正确显示字型
虫部:總論
“虫”本讀huì,是一種毒蛇,後来寫作“虺”;(来→來)
馬部:總論
……有些字看来與馬無關,(来→來)
血部:總論
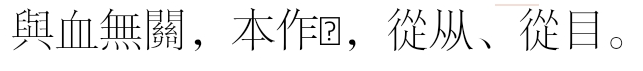
未能正确显示字型
行部:總論
……正如甲骨“行”字的形體补所示,(“补”处漏补?)
……“衝”是緃横相交的大道,(緃→縱)
……“衢”是四通八逹的道路,(逹→達)
衣部:總論

“衣”作爲部首,通常寫作“礻”,……(礻→衤)
“袤”字mini字体漏了?
3 个赞
吹毛吹出那麼多毛病哈哈,厲害。部首總論的確問題多,畢竟數據來歷不同。我製作字型時沒配合這內容,也是讓毛病顯得更突出,容易被發現。
字典沒收 姞、鯫,雖然出現在總論。大概總論是另外寫的。(辭源收了這兩個字。)
幷字總共八畫,所以 [幷色]字卻是 +8畫,原文沒錯。
2022.1.22更新
- 蹲字條:説文士部引作“墫墫”(从土)➔壿壿(从士);坎字條:墫墫➔壿壿。
- alexpeng提出的部首總論錯誤,都修了。又分析了總論數據,字方面的問題應當都解決了;補了字型。
3 个赞
糸部……由加染形成的各種顏色。

原来王力词典用的“顔”字,连累楼主也错了 ![]()
是的,[幷色]字是 +8画。清了下缓存,看到第二个是[幷色],原来是没有清缓存?韵母中还有两个“艵”。

衣部……通常寫作“礻”
衣旁是两点,兄台看花眼了吧 ![]()

“袤”还是显示黑体,楼主看看是否漏了。
衣部中

词条内
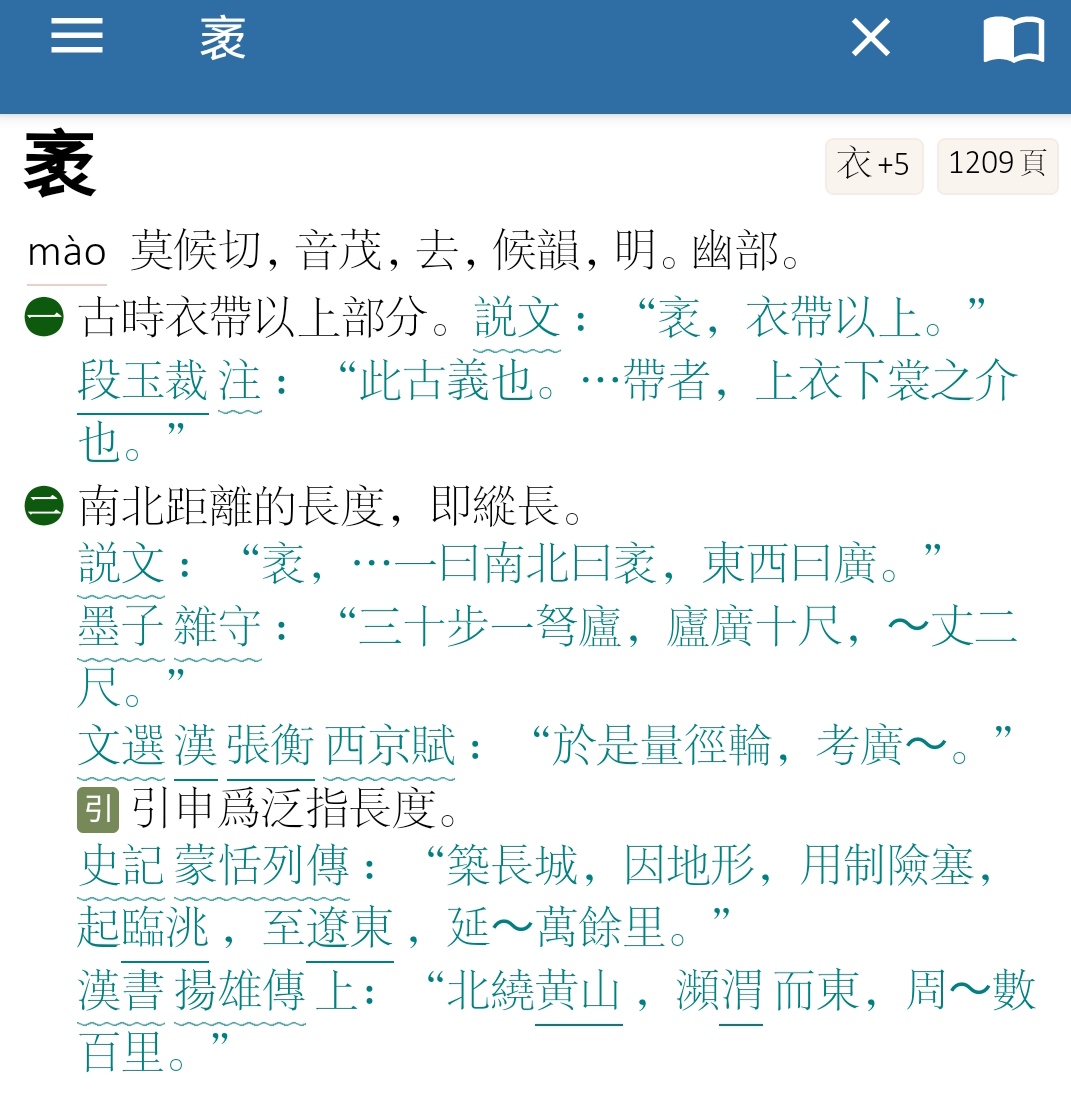
wlkx部首表:黄

貝部……有兹關於商業活動的(多了个“兹”)
阜部:阜字説文作𨸏,古文作𠼛。禁定作阜……(禁定→隸定)
骨部……與骨骼身髓乎無關的詞。(身髓乎→幾乎)
黑部……與黑色無關的名詡。(名詡→名词)
艮部……現歸在艮部的字,意義上無關繫。(關繫→聯繫)
弓部……引(關弓)——(關→開)
女部……這些解番都很勉强……對“委”字的解番牽强附會(解番→解釋)
利用 Dict Tango 全文搜索异体字:說別沒
搜到說1条,別2条,沒5条。




正文词条基本是繁体文言,功力不够,吹不动了![]()
6 个赞
汉语非楼主母语,疏漏这点也属正常。毕竟没有专门语文课强调一点两点这个易错点。
阿peng吹得不错,厉害厉害
过奖过奖。楼主应该是没细看吧。
1 个赞
想一口氣把它搞定,一時瞎了眼呵呵。
關於 顏 顔 兩個字形,其實王力字典經常混用字形:最常見的是字頭用舊體,釋文用新體,也有vice versa。像隩字條,“奧”用舊體(从釆):

但其字頭用新體“奥”(从米):

這現象很普遍,(也使加鏈接的工作更麻煩);不方便規範化,所以我沒動它,大多保持原樣。
關於“袤”字,原來是私有區字( F754E ![]() ;字形與紙書不合),我改成標準字之後,忘記更新相關的標籤,只不過如此。
;字形與紙書不合),我改成標準字之後,忘記更新相關的標籤,只不過如此。
艵字形,原初版mdx是對的,後來改了CSS,HTML沒跟上來哈哈。
《常用字字典》的數據,來自繁體版,所以“說別沒”字形不合。改了。
4 个赞