我来分享下补充这本词典词头的方式
TODO 能用utf8显示的异体字我在上一个版本没有做词头,导致这部分字只能通过找正体,再点击进去,造成不便,不能通过直接输入来查,从而不能从多本词典里面一起查询。
我之前弄数据的时候,多了个心眼。把词头和相关数据写到数据库了,现在看来真是明智之举。刚好可以用这俩数据库来把能打出来的异体字弄出来做个词头,跳回正体。算是一种解决办法。当然如果再肯花更多的时间,还有更好的解决办法,我就不弄了。
先写在这里,我还没开始写程序。一会更新。
Update 2019 11 23 12:26PM
好在有数据库,很快这个小问题就解决了。方法如下:
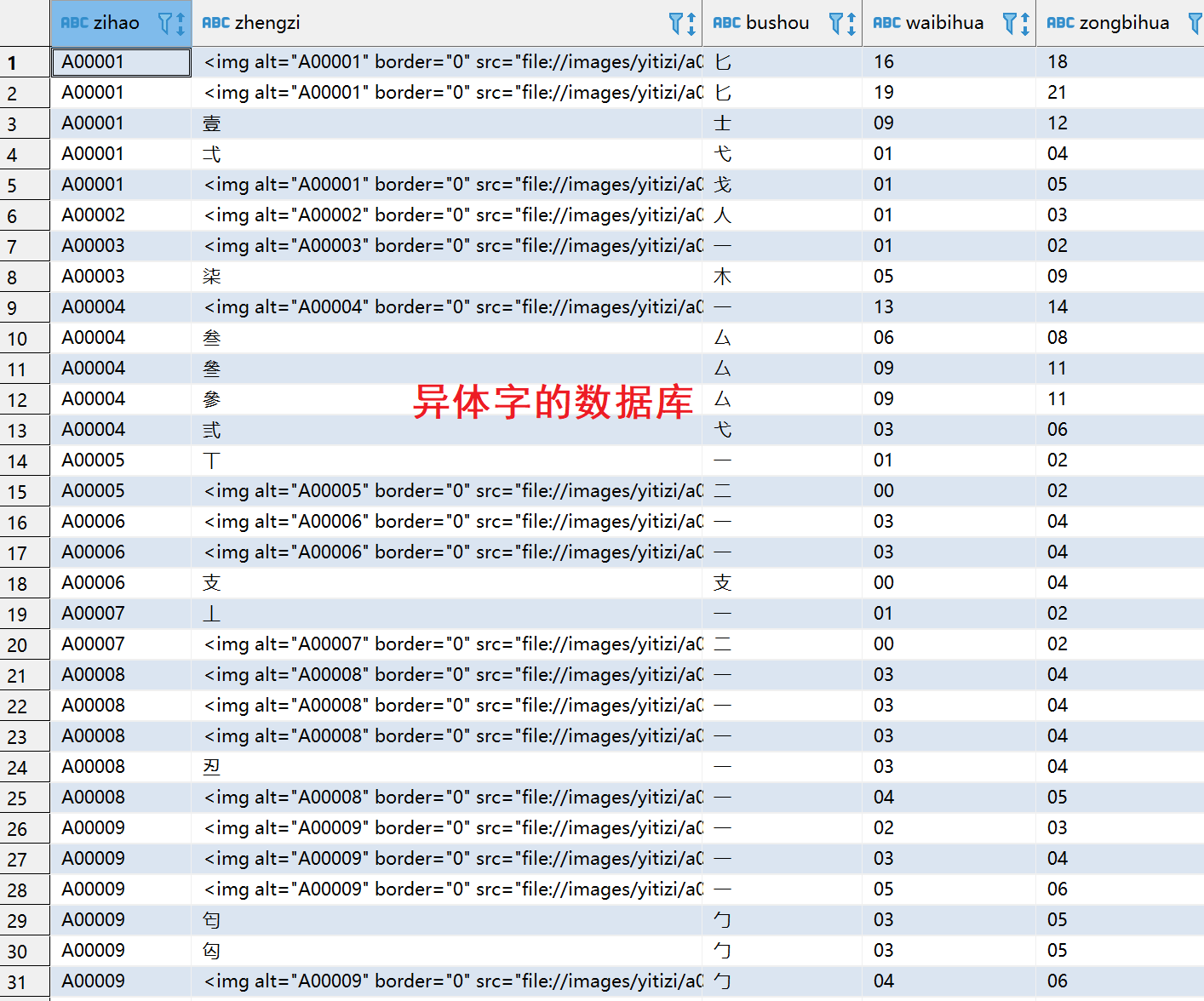
- 两个数据库的结构如下:
异体字数据库里面的zhengzi段存的是异体字,这是我建数据库的时候图方便。可以看到这里基本都是img标签,也就是图片,图片肯定是不能做词头的,另外如果一个异体字兼做正字的话,我们也不做跳转。
所以拿到不包含img的 zhengzi段,然后去正字数据库,看在不在这儿,如果在,就不做词头,因为那样就重复了。不在就做一个跳转。
程序如下


import sqlite3
conn_yitizi = sqlite3.connect('search_yitizi_single.db')
conn_zhengzi = sqlite3.connect('search.db')
c_yitizi = conn_yitizi.cursor()
c_zhengzi = conn_zhengzi.cursor()
write1 = open("yitizi_citou.txt", "w+", encoding="utf8")
c_yitizi.execute("SELECT * FROM main")
for yitizi in c_yitizi:
citou = yitizi[1]
if 'img' not in citou:
c_zhengzi.execute("SELECT COUNT(*) FROM main WHERE zhengzi='{}'".format(citou))
for i in c_zhengzi:
shumu = i
if shumu[0] == 0:
# 这个异体字没有出现在正字过
# 可以单独做词条
write1.write(citou + "\n@@@LINK=" + yitizi[0] + '\n</>\n')
write1.close()
两个数据库我也贴出来吧,内心其实不太想 ![]()
search.db (836 KB)
search_yitizi_single.db (8.7 MB)
主站的文章已经更新了。请去下载。