一路泥泞,终于开始对汉大音序进行ocr处理,效果差强人意,至少页码的识别率挺高。
然后抽取汉大2的词头与页码信息,与ocr结果进行近似度比对:
先进行页码完全比对,余留的进行高相似度比对,初步建立汉大2与ocr的对应数据;
然后再对每组数据的两边词头进行相似度比对,从高到低进行对应,用汉大2词头代替ocr词头;
最后处理注音。可先拿ocr的每个字音与25个字母及标注声调的字母进行相似度比对,用正常拼音替代那些ocr出来的奇怪字符,然后拿汉大2的字头注音处理ocr替换后的每个字的注音,单音字直接替换,多音字逐个比对,用近似度最高的字头音替换。
注音处理应该是个难点,音序目录没有把字与字的注音与空格分开,分割是个问题。也许把汉大的词头注音也合并起来比对会好一点儿。
如果一切顺利,结果就是一份升级版的音序目录,按页码排序就能和汉大2以及图像版构成对应关系。
1 个赞
okayer
2
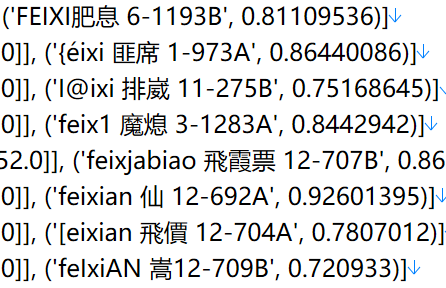
把圖片OCR了一下,結果可以參考。
百度OCR
feix肥息6-1193B
feixi匪席1-973A
feixi戲11-275B
feix廢熄3-1283A
feixiabiao飛霞驃12-707B
feixian飛仙12-692A
feixian飛僊12-704
feixian飛12-709B
誠華OCR
feixi 肥息 6-I193B
feixi 匪席 1-973A
feixi 誹戲 11-275B
feixi 廢熄 3-1283A
feixiabiao 飛霞驟 12-707B
feixian 飛仙 12-692A
feixian 飛倦 12-704 A
feixian 飛驚 12-709B
PDF Reader Pro OCR
feixi 肥息6-1193B
feixi 匪席1-973A
feixi 誹戲11-275B
feixi 廢熄3-1283A
feixiabiao 飛霞驃 12-707B
feixian 飛仙12-692A
feixian 飛倦12-704 A
feixian 飛騫12-709B
至於ABBYY,繁體中文效果太差了。
1 个赞
myfav
3
印象中,以前下载过《漢語大詞典》12卷本及1卷附錄的清晰版PDF,2GB多一點兒,词头也見过人家用心編寫好的网页版查询系统,不需要今天自己再重新OCR吧?不过,我不太清楚它究竟是汉1或汉2,总之,查「匪席」就是P.973,查「飛仙」就是P.692。
……哦,原來是想排音序目录,難怪!感覺上,詞組首字的拼音在單字上已標註,第二字以下的,若有多音,會在釋義中標注,可惜掃描版無法自動提取。
它也太强了,不知道有没有win版可用?
看来paddleocr还得训练,我是直接拿来就用。训练还得学习……
网上找不到可用的win版,不知老兄能帮忙ocr吗?
1 个赞
okayer
6
1 个赞
不行,都是试用版,只能转pdf。老兄的私信功能关闭了吗?
还是低估了ocr数据处理的难度,想分音、形、页就很难。原以为页码会比较准确,再加上okayer侠相助,应该比较顺利。但无奈有些地方图像太不清楚,再好的ocr技术也无可奈何。
2 个赞
hahaya
12
看来这个PDF Reader Pro OCR识别繁中还挺强的,不知识别简中和英文效果如何呢?对比其他像福昕、万兴等软件怎么样呢?
okayer
13
我沒有這些軟件。一般場景下的簡體中文,百度OCR是真的厲害,恐怕更好的不多了。豎排、繁體中文目前我覺得PDF Reader Pro OCR是最好的。
3 个赞
hahaya
14
您用的PDF Reader Pro OCR是Mac版还是Windows版呢?有没有Windows的破解版呢?可以分享您自己用的版本吗?百度OCR是用的什么软件呢?只是识别文字吗?能保留原来的排版吗?
okayer
15
我用的mac版本是這裡下載的 https://www.zhinin.com/pdf_reader_pro-mac.html
百度ocr就直接按照官方說明調用API,排版我看默認縮進、留白、空格之類都去掉了,比如:
識別結果
王勃(649—676),字子安,绛州龙门(今山西河津市)人。年十四即及第,授朝
散郎,为沛王府修撰,因戏作檄英王鸡文被高宗逐出,乃客蜀中。为虢州参军时又
犯死罪,遇赦革职。父福畤因受累而谪迁交趾令,勃前往省亲,渡海溺水,惊悸而死。
他是初唐四杰之一,才气最高。相传作文先具“腹稿”,文不加点,也善为骈文,
名作有《滕王阁序》,承六朝藻饰之风而特为雄放,也象征当时政局正处于上升时期。
其诗以“高华”著称,内容较六朝宫体诗扩大,音调的婉转变化,则又吸取乐府之长
(如《采莲曲》)。也由于四杰的努力,诗风已有所改变,于五律的格律逐渐树立,故使
杜甫有“不废江河万古流”之称。明陆时雍在《诗镜总论》中说:“调入初唐,时带六
朝锦色。”这也是说得很公允的。要
可能要腳本進一步修改才行。
okayer
19
paddleocr默認識別比其他開源的都要好,但字稍微生僻一點就不太行。老兄後面要是有了心得,把怎麼訓練、使用paddleocr和大家分享下啊

