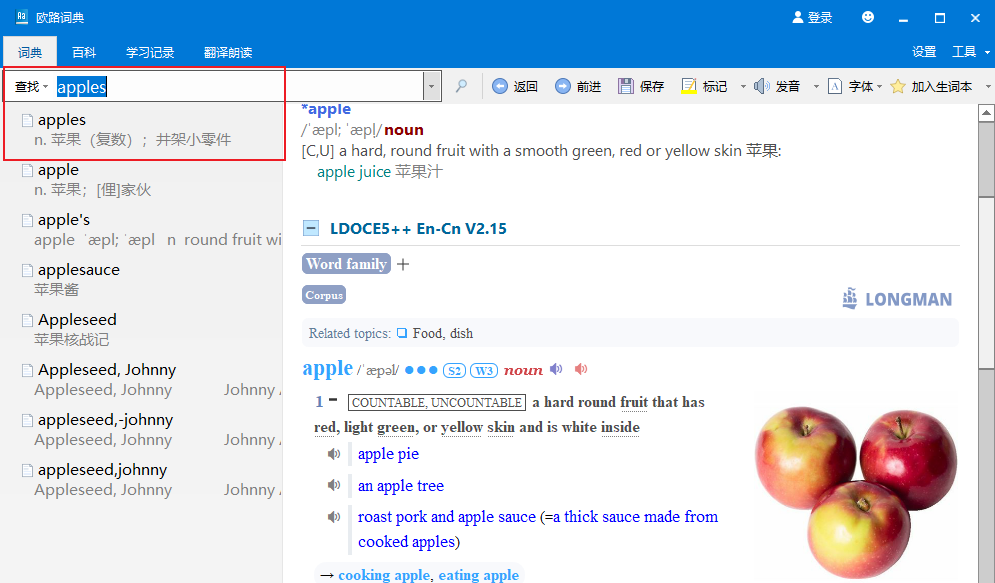
就比方说,假设词典是给“傻瓜式”的五岁小孩子或者八十五岁老爷子用的,他啥也不懂,遇到一个单词:
apples
他只知道将整个单词所有字母都往词典里边复制粘贴。可问题是,高级词典也并不一定完全收录一切规则名词复数、规则动词时态等等词形变化,查“apples”,臣妾做不到啊!
——怎么破?
就比方说,假设词典是给“傻瓜式”的五岁小孩子或者八十五岁老爷子用的,他啥也不懂,遇到一个单词:
apples
他只知道将整个单词所有字母都往词典里边复制粘贴。可问题是,高级词典也并不一定完全收录一切规则名词复数、规则动词时态等等词形变化,查“apples”,臣妾做不到啊!
——怎么破?
请教smiling1384:具体是什么词典会带有类似“apples”这样的“傻瓜式”完整词头?我想要一份用来作目录。非常感谢!
没必要啊,你看我查 apples 查不到,但可以返回 apple 这个查询结果。一般用规则就可以还原,不规则的本来就应该做为词头收录。
不仅仅是-s,复杂一点的,比方说,-ly变成-lies之类。还有,不一定用欧路,需要“傻瓜式”适用到一切应用场合。故而想啊:面对“傻瓜”,便去寻求同样“傻瓜”的完整列表,一了百了,而不必求助于相当复杂的词形还原算法。
我猜没有适用一切的方法。即使是简单的用列表还原,也不可能100%正确的还原出原始词形,因为可能有两个不同词的变化形式相同,你没办法自动还原的。再例如, V+ing (, V+ed) 既可以看成动词的分词形式,又有可能做为名词词性,同时还可能发展为形容词,第1种可以还原为动词,后两种都不能错误地还原为动词原形。
非常感谢First_Last的指点!
另,我好奇地搜了一下:
English Morphology
结果找到了异常复杂的C代码,看得云里雾里的:
虽然看不懂,不过虚荣心这下子得到了满足。
那也是极好的,哈哈哈哈。
首先得有vocabulary_full_families,或者e_lemma.txt,或大神的84397_skywind__BNC_lemma.en
把所有的派生词集合针对原词头检测重复一遍
没有的添加新词头如,
</>
apples
@link=apple
</>
词头数基本快翻倍了
这个问题的正确解决不是取单词的 stem,而是 lemmatization,而且一般是基于规则进行,而不是词表。同时,正确的 lemmatization 又依赖于该词在句的词性 (part of speech)。用户在查单词时,输入的是孤立的单词,所以无法得到完全准确的 lemmatization。
最后结论就是,查单词的人,不能完全不懂英语,而是懂的越多越会查。这和我们的常识相一致。
GoldenDict使用的构词法词典(Morphology Dictionary)不是用来查找原形的,它提供的是拼写建议。查找原形必须使用单词表跳转。
寧濫毋缺的話,用84497源詞的skywind3000/lemma.en匹配(部分單複數或者變形是錯的,又或者硬造了一個不存在的英文詞。
)。
寧缺毋濫的話,用26061源詞的michmech/lemmatization-lists/master/lemmatization-en.txt
要像smiling1384說的基於規則的話,可以看下LemmInflect。基於規則,你要先從釋義提取出單詞的詞性,然後轉換,但不可避免,部分單詞的變形也會有問題。
制作原形单词表,还可以参考spaCy的,数据来源是WordNet: