三区不重叠,一起搞就行了。
至于二分法,应该是
三区不重叠,一起搞就行了。
至于二分法,应该是
三区u码不重叠,但有很多异体字。我以前三区一块搞,因为按顺序优先扩展a区,所以解出不少a区字。所以后来优先基本区。你没有遇到这种问题?
我的理解,类似得到app的一些电子书《ebook》加密思路:
得到把《ebook1》里头某一部分字提出来作为一个子集,里头每个字(如“古”)映射一个号码(如“T^¥h&”)进行加密。这个加密《ebook1》但每当碰到这“古”字就要去这个《ebook1》子集查询、用该号码来解密还原成“古”(其他字使用正常的Unicode编码,即没有加密)。如果没有这个解密过程,这个《ebook1》的“古”就显示T^¥h&”乱码,其他没在这个子集里头的字本来没有加密、是能正常显示的。
《ebook2》也是如此,里头的加密子集跟《ebook1》不完全一样,比如“古”可能显示为其他的乱码。
这个词典的加密,是一个词条的内容使用各自的加密子集,可以理解为一个词条相当于一个《ebook》
嗯,思路应该是一致的。我上面提的问题主要是如何优化算法,觉得基本区找不到就得从头再来,太笨。如果a区字不在基本区前就没这个问题。
多谢!但为什么要用base64编码呢?
Unicode不重叠,然后用 MD5 对比,你从原理上想想,为啥会有优先级的问题呢。就一个字形对应的 MD5 嘛就应该是唯一的,然后用这个 MD5 去找本来是哪个 unicode 码。
我是没差别一起弄的,暂时没有收到解密错误的报告。
太牛了,老兄! ![]()
不过这一类字怎么搜?
你没看我在78楼回复你的帖子
其實,用特製TTF能夠更方便找字,優點不僅是準確反應紙書的模樣或是好看。這個道理很簡單:罕見或奇怪的字形掛在標準字上,等於是能用常字找出非常字形。舉個例子:
紙書的“瘨”字頭:
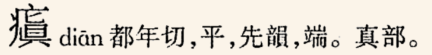
全宋體沒有這個字形,即使有我也不用。這是特製TTF的效果:

若從mdx拷貝這個字頭,他就是普通的“瘨”字(而不是私有區字),所以能正常使用,能在其他電子字典查。區別是,幕後這個字頭加上標籤,讓他用特製TTF顯示;如果同一個字出現在釋文或是其他字條,他就沒特別標,所以用默認的中華字型來顯示。
這也是王力字典的特點:經常是字頭在字目用舊體,在釋文用新體。既然如此,我在數據也用同一個字碼,一個標成特製TTF,一個沒標,兩個拷貝出來就是同一個字,沒有搜尋的困難。這樣兩全:反應紙書的模樣,又跟標準Unicode和普通輸入法通用。
再補上幾千異體、舊體、新體、簡體跳轉,所以不會有搜尋問題。
老哥算是提供了一种以后做这种词典中难搞的字的索引的办法,太感谢了
虽然不太懂,
但希望能总结一整套查找、输入生僻字甲骨文等词典中不常见字形的工具链 toolchains 出来。
有了统一的工具,今后众人的协作也有了个基础平台
在深蓝打开崩溃?词库有问题吗?
該字典引用同一句,採用不同字哈哈。
簳 字條
![]()
澶 字條
![]()
前者寫 “篾”;後者寫“𥫗罒伐”,沒有標準碼,所以用私有區字。兩個字條大概是不同工作組處理的,反正用不同文選版本。
anyway,為了把私有區轉成標準字,我把 “𥫗罒伐” 字形掛在“𮆘”(𥫗罒冖伐)字上,用特製TTF顯示。
關於南都賦,經查,上海古籍出版社《文選》(1986)152頁,是寫 “𥫗罒伐”。
中華書局《六臣注文選》(1987)84頁,寫“𮆘”(𥫗罒冖伐),多了一個 “冖” 部件。這字有標準碼。
![]()
奇怪的是這個“𮆘”(𥫗罒冖伐)字形,本來是2017年,Unicode特別為《辭源》而把此字加入CJK字符集。但《辭源》並沒收這個字!起碼,第三版沒有。也許第二版有?
之前是處理字頭方面,現在處理釋文裡的私有區字。有160個獨特的,出現200多次。
生僻字的尴尬就在这里。
没有部件檢索工具,即便录入人员知道正确字形,但没办法知道字体文件中是否已经有这个字,以及如何找到这个字。
于是,最省事最保险的做法往往是自己在私有区造一个
這個話題有趣,我也好奇當時王力跟他學生們編輯這本字典是怎麼輸入字的。也許是用中華書局內部的輸入法,他們網頁提供某個輸入工具,我試圖安裝,裝不成功;聽說很不好用。
也許是方正字庫提供的輸入工具。利用方正字庫的數據,有的字明明有標準碼(又沒有字形的分歧),但偏要用私有區字。例如“㩳”、“䱷”,在Unicode 3.0 (1999年)就已經有了標準碼,但數據偏要用私有區字來表現。(話說回來,王力字典是2000出版的,也剛好是那個階段。)
目前最新的中華書局字型,我能準確得說是沒更新到2020年Unicode 13.0版本,因為王力字典的“”、“”二字是 Unicode 13.0 的G區字,數據還是用方正私有區字來表現。
那个时候是铅字排印的,不是电子化的,而是按部首偏旁排序的实体字模,反而可以按结构找铅字,没有输入法或电脑字体缺字、或者字体已有该字但没找到等所导致的问题。
到了辞源第三版印刷,电子化排版,反而头疼。
2013年,《辞源》进入复审、复查、合龙阶段。和平里的一栋小楼,是《辞源》编辑组的一小块根据地,三位主编和复审编委在每周在那里开一次例会,讨论近期出现的问题。
当年10月,电脑输入工作即将开始,王宁带领小组和方正字库对接,要建立一个以《辞源》为封闭系统的电子字库,这又是一场电脑与手写的角力。“要考虑到以后做《辞源》的电子版必须有通用的八位国际编码,某些生僻字要和国际编码对上。有的输入员水平不高,字库里有编码的字他不认识,就重新造一个,赋予一个新的编码,最后有的字有好几个编码。我们的团队为此花了很多功夫。2014年初这些问题才得以解决。”
汇思想 _ 第三版《辞源》修订组采用最原始方式,每个词条均手工修订 (whb.cn)
而文明的加速显然甩给了王宁更多的时代命题。1981年,王选院士主持研制成功中国第一台计算机汉字激光照排系统原理性样机华光I型,此后数年又推出从华光到方正共5代产品,从此,汉字印刷告别了铅与火的时代,并且接受了信息时代的挑战而直接进入了互联网。1990年,中日韩将各自所用的汉字合在一起,正式发布了CJK字符集,含20902个包括简体和繁体的汉字,成为汉字第一个国际编码的基本集。这么多的汉字要在只有26个字母加上10个数字的美式键盘上经过输录进入电脑,必须有一套系统的交换码,由于各国编码不统一,汉字在传输过程中时常出现乱码,影响了信息的顺畅交流。为了研制汉字形码,很多计算机大家纷纷将汉字拆成部件,方法各异,形成一种“万码奔腾”的局面。
1994年,中国将CJK作为国家标准,国家语委成立了专家课题组,为20902个汉字进行规范的部件拆分。这时候,王宁从《说文解字》中采用系统论方法创建的汉字构形学已经基本定稿,依理拆分的规则制定后,为课题组打开了一度受阻的思路。举个例子,“颖”这个字怎么拆?不懂训诂学的人可能会将它从中间劈开,右边为“页”,左边就不是字了。完全按汉字构形的规律拆分则先拆出“禾”字,剩下的是“顷”,“顷”再拆成“匕”和“页”,“禾”是“颖”的义符,“顷”是“颖”的声符。有了字理为依据的规则,部件拆分顺利完成。从上世纪90年代开始,王宁在传统语言文字学的研究道路上迈开了新的一步。
躬别恩师后30年过去了,她谨遵师嘱,坚持培养传统语言学的优秀人才,而且适应信息时代的要求,在招收传统语言学博士之外,还连续招收了5届信息技术与文字训诂学交叉的硕博士。现在,她有了一支继承传统并走向现代的学术队伍。这支队伍有雄厚的文字训诂学功底,具有继承传统的意识和能力,以及发展创新的意志和担当,他们忘却名利、忠于教育,是传承章黄之学站立起来的一支生力军。他们不但在教学岗位上开创新课题,致力于传统语言文字学的人才培养,而且站在前沿,先后创建甲骨文、小篆字库,研制《通用规范汉字表》,开发《数字化〈说文〉学研究平台》,完成了《汉字全息数据库》等重大项目……
王宁:打开汉字之美 | 我和我的祖国70年70人 (whb.cn)
有点好奇这个《汉字全息数据库》
字典既然有詞目,適合加詞目接到字條的跳轉。有將近4,800多詞目。
其中500詞目,他的字條並不是第一個字,所以特別需要跳轉。例如:
四字詞也另外拆成兩半,各加跳轉。
700詞目,多次出現在不同字條,但我限制跳轉只跳一個地方。
王力古漢語字典 (2000)@link3 - phrases.rar (26.5 KB)
子、字、孳、牸 字條:

這是紙書的錯誤,電子數據自然也不對,href 連接也要改:“滋”不是字頭,紙書的拼音索引也沒有。我改成“滋”,跟“滋 ”(氵玄玄)有所分辨。



