没忍住,又试了VFP5.0也跑不起,放弃。
原作者是复制出来的,忘记哪个人了。二进制那个文件没有问题的,我用Hex程序看了,和数据库里的一模一样。文本文件不知道怎么回事,导出来就这样。
我把这个文字版与高清图片版合并在一起(图像经过切边,纠斜,增加伽马值、压缩等),便于比对,有需要的可以下载。
我用阿里云盘分享了「漢語大詞典2.0.mdx.jpg」,你可以不限速下载![]()
复制这段内容打开「阿里云盘」App 即可获取
链接:阿里云盘分享
我用阿里云盘分享了「漢語大詞典2.0.mdd.jpg」,你可以不限速下载![]()
复制这段内容打开「阿里云盘」App 即可获取
链接:https://www.aliyundrive.com/s/bHnWd5cWZut
顺便问个问题,用ComicEnhancerPro处理文件后变得很大,有没有好的压缩方法,用了几种方法都无法压缩,只得缩小图片,效果不好。
我用阿里云盘分享了「0001.png」,你可以不限速下载![]()
复制这段内容打开「阿里云盘」App 即可获取
链接:阿里云盘分享
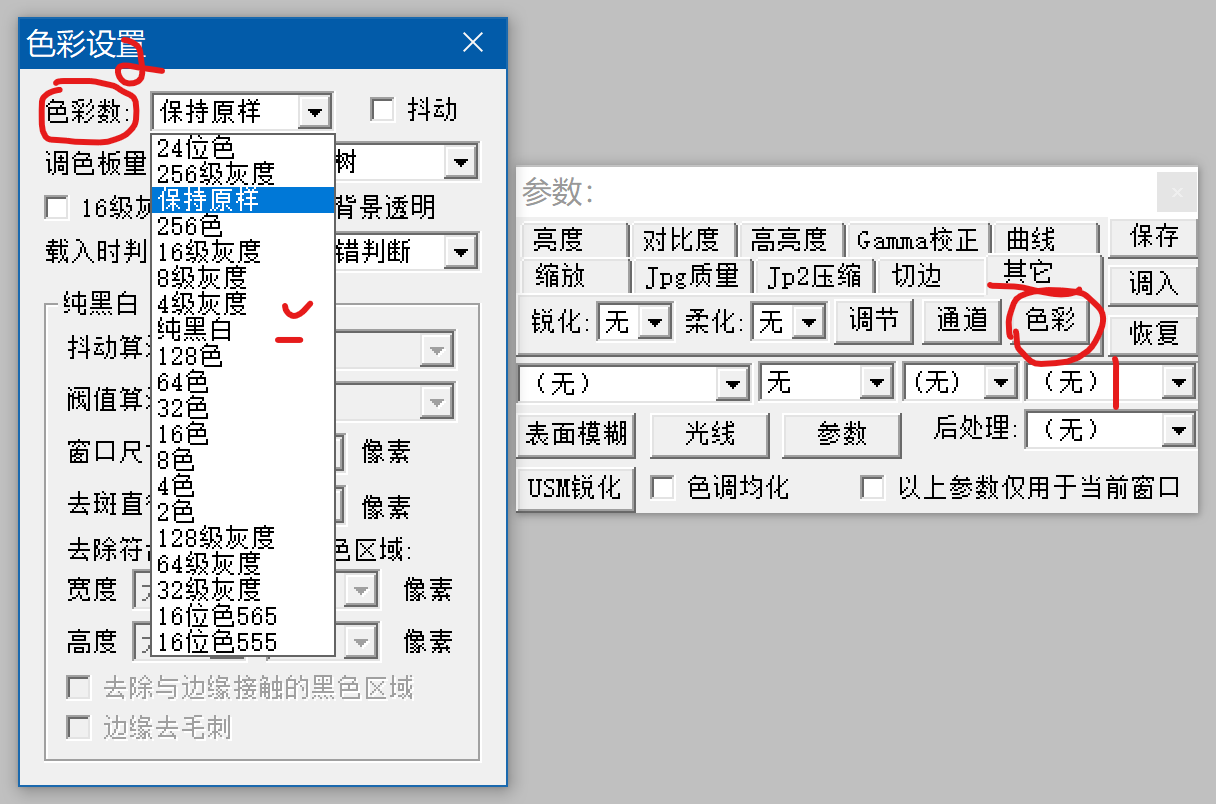
多谢指点!试了一下,用4级灰度肉眼几乎感觉不到多大损失。老马的软件功能真强大。



PUA对照.txt (2.1 KB)
兼容字对照.txt (124 字节)
康熙部首对照.txt (114 字节)
这几个字需要修改
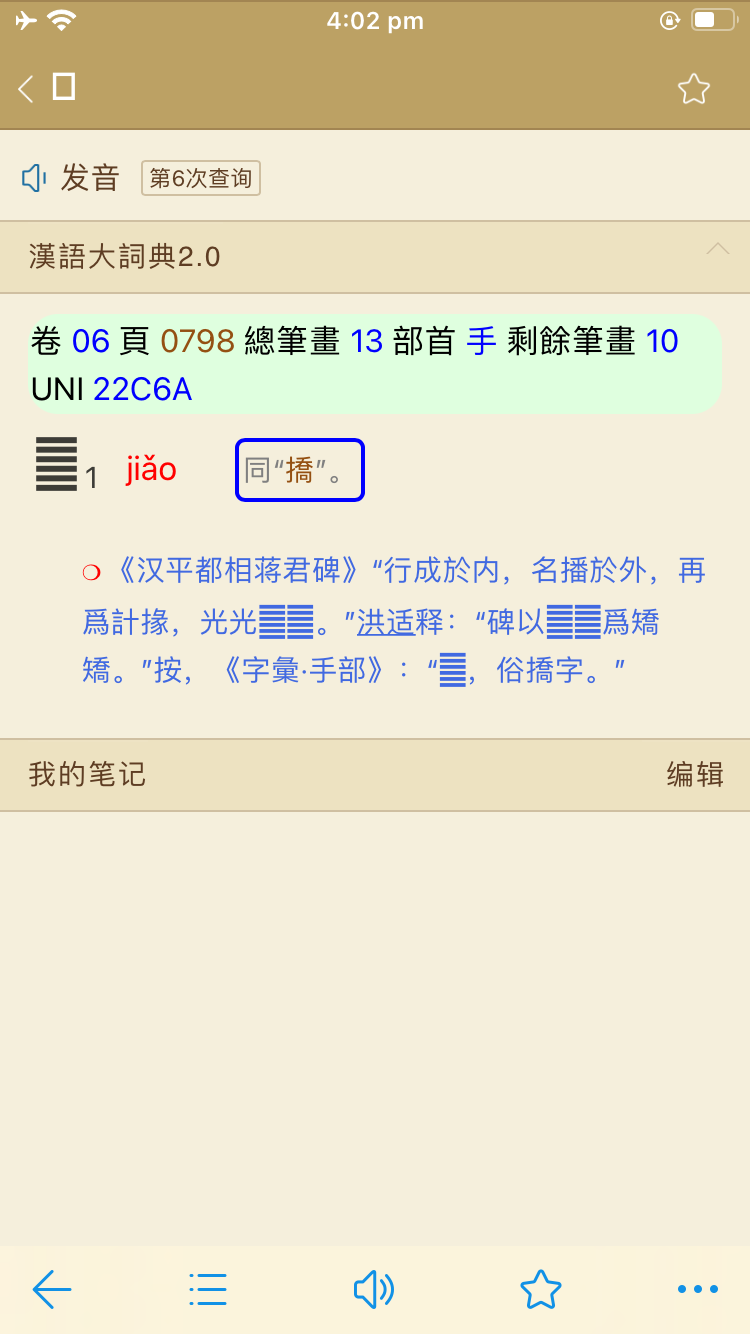
此处书上应该就是U+8E9B。《汉语大词典》的副词中非首字都有标有笔画数。该字标明23画,U+8E97只有22画。至于说和另一处的书证用字不一,这倒不是大问题。《汉语大词典》本就非一人独立编撰,每位编辑看到的版本极有可能不同,各自采录,前后出入的情况比比皆是。
从笔画验证,思路很好!
你发的在这版找不到呀
2.0版本,直接复制搜索呢
我这里显示的就是你列的后面的字。难道我什么时候自己改过了? ![]()
用正则试试,如果还是没有那就是改了,期待早日更新
||㑳|
U+E81A U+3473
||八|
U+E4A3 U+516B
核了一两个字,问题字出现在正文里。
最重要是字头不能用私用区字。一般也只检查这个。
假如连正文的私用区字也要改,就须大费周章。
原来指的正文,这些字真是麻烦 ![]()
因为核了这两个字,发现《汉语大词典》图像版的字头有私用区字:
〖U+E81A〗---->〖U+3473〗㑳
〖U+E829〗---->〖U+3A73〗㩳
〖U+E850〗---->〖U+499F〗䦟
图像版的字头问题不少,漏掉的就有好多,用我合并的版本从文字版直接可以跳转到图像。
昨天又摸索老马那个软件,发现对图像降噪加黑包括放大之后,图像不仅清晰了,而且体积也变小了。不过还没重新合并。
刚才搜了全文,私有区用字共326个。如果想改,可以借助《教育部异体字字典》修改(想当然了,也不行)。
这些私有区的字不知从哪儿来的,光盘版应该没有,我搜了一下我原来用的汉语大词典,只有这一个。
如果知道私用区字的字符编码范围,可以用EditPlus等专门文本编辑器有按照Unicode编码查找的字符的功能。
例如要找文本中所有属于 HKSCS 的字符,因为其字符编码范围是[\uF900-\uFAD9],按照这个正则表达式就能依次搜索查找出来。参见与 @Mastameta 的讨论