个別mdx, mdd指定了字体,解包后也要删除,附上我用的字体包(拆分的全宋体,辞源宋)
FSung-1_01.ttf (4.9 MB)
FSung-2_01.ttf (21.0 MB)
FSung-2_02.ttf (22.3 MB)
FSung-3_01.ttf (3.1 MB)
FSung-F_01.ttf (21.2 MB)
FSung-F_02.ttf (26.5 MB)
FSung-m_01.ttf (28.6 MB)
FSung-p_01.ttf (28.6 MB)
FZCiYuanSong.ttf (17.6 MB)
5 个赞
哥,那我这个是怎么回事啊,安卓手机,请指点一下啊
这个拆分字体怎么用啊,直接全部下载放一个文件夹啊,哥,你这个专名号很全啊,怎么设置啊,你说的这个看不懂啊,怎么编辑字体css,还有删除字体包这些
3 个赞
把所有字体ttf( 其中fsung-m/fsung-p二选一)加载到dict tango(此app本论坛有发布)。以下鄙人稍改的
辭源3文字版2021.mdd (25.5 MB)
辭源3文字版2021.mdx (28.4 MB)
cy3.css (5.6 KB)
4 个赞
已经设置好了 完全正常了 非常好啊
2 个赞
哥,你这个字体包好大啊,100多mb,
2 个赞
王云四角号码?
小时候有背过。
2 个赞
请问您这个具体修改了什么呢
2 个赞
具体细节记不住,和作者原件对照下吧,我也是瞎摸索的(善用GoldenDict右键查看源码)
辭源的數據用 全宋體 不妥,尤其是字頭。
- 首先要知道WFG全宋體的特點:WFG傾向於舊字體,但辭源大多是採用新字體(參考凡例)。
例如:“過“ 字 (統一碼 U+904E)
辭源用新字體。
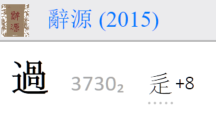
同一個統一碼,全宋體掛的是舊字體:

不僅是“辵”偏旁字體不同,“冎”的上頭也不一樣。總筆畫比辭源多。
若用WFG部件檢索,就知道在很多情況下,新字體不被認可,甚至新體拆出來居然變成舊字體的部件!
![]()
- 還有挪動編碼的問題。例如“卿”字,電子版的統一碼應當是新字體,但font顯示出來的是舊字體(跟印本一樣)。所以隨便換font就錯了。總筆畫應當是12。

- 辭源的電子數據,字頭有私有區字,釋文裡更多。只能用FZCiYuanSong.ttf能顯示。
實際上,字頭的私有區字都能改成統一碼,除了一個字頭以外(全宋體也沒有),只能用辭源的font。釋文裡的私有區字就無法完全標準化。而且,要徹底處理這個問題,得編輯FZCiYuanSong,因為有些字,它不跟從統一碼的標準掛號,必須把他的字形挪到標準統一碼的位子,要不然那個位子是空的。
2 个赞
外挂字体中有FZCiYuanSong,可恢复原数据中font-family,所指定字体稍加调整
2 个赞
我修改的字體,只替換了GBK基本區,其他區字形照舊。爲了手機顯示美觀耐看。原字體太細,又不好看。當然如果追求100%忠實原紙書,那就用原字體就好了。
我也覺得辭源字體太細,不好讀,除非放大,例如用在字頭上。我自己用的mdx,只有字頭和釋文號碼專用FZCiYuanSong。其他內容混合一系列的font。
fontforge 可以调整字体粗细。
http://designwithfontforge.com/zh-CN/Bold_and_Other_Weights.html
1 个赞
我本不知道FontForge能做這個,有空我玩玩看。
我曾經用FontForge作出個補充辭源的font,為了處理辭源挪動編碼的問題(也有些字頭明明有統一碼,但辭源偏要用私有區字)。比方說,如果要把“卿”(U+F37F)改成印本的“卿”(U+2F833),FZCiYuanSong.ttf裡的U+2F833位置居然是空的。所以我把U+F37F位置的glyph複製到U+2F833的位置,這樣MDX能同時保留辭源的字形,又能使用標準的編碼。

FZCiYuanSong-remap.ttf (62.5 KB)
這是補充的font,所以在font-family裡,擺在FZCiYuanSong後面。CSS也得寫一條font-face。
3 个赞
不知道私有区里这样的字有多少,要都能用标准编码会方便很多。
1 个赞
我本來以為統一碼不夠用是因為難字、僻字;我後來發現:很多字,統一碼沒有給舊字體、新字體分別分配碼位。所以會引起這種狀況:
檾,本作“X” (私有區字)
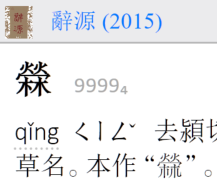
Unicode官方編碼是新字體,“檾”下面是“林”:
https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=檾
舊字體的“檾”,下面是“pài 𣏟” — 統一碼沒有碼位,所以辭源用私有區字。
(WFG全宋體把官方碼位變成舊字體 ![]() ,嚴格來說,是不規範的,但也是不得已,因為只分配一個碼位。)
,嚴格來說,是不規範的,但也是不得已,因為只分配一個碼位。)
辭源釋文裡無法完全去掉私有區字 — 分配的碼位不夠。光是新字體、舊字體之分,就涉及到很多字。
3 个赞


这是全宋体的吗,试试辞源的字体。
用的是楼主文件里自带的css,我不会修改