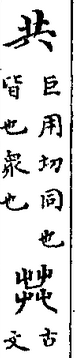玉篇8.10.7z (882.4 KB)
修正了几处错误,排版小调整。


玉篇.css (1.0 KB)
9.18玉篇.mdx (745.7 KB)
1.补入部分异体字头
2.修正正文部分错误
3.加入专名号
4.修正断句不正确问题,但不保证100%正确。
玉篇8.10.7z (882.4 KB)
修正了几处错误,排版小调整。
我这goldendict排版不对劲啊。但欧路词典没问题。

看css中AA语法,可跟据软件情况自行修改。目的是隐藏。
认知范围以外……先mark
无法图文对照吗
關於上面RANP0提的“中”字條,出現“�”符號,看來原是XML unicode,我修改了整個文件,應當正常了(但好像重複了字目):

MMedit玉篇.rar (739.3 KB)
——————
謝謝樓主分享。
據wiki,
“封演《聞見記》宣稱《玉篇》共16,917字。”
“今所傳本已非顧氏原書,自唐孫強增加字數,宋陳彭年、吳銳、邱雍等又重修,稱《大廣益會玉篇》,共有22,561字。”
這個MDX有22,807字頭。
數據是有標記,但沒有CSS來分辨內容層次。
“#”號碼,總共有542項,是《玉篇》用的部首。例如“中”歸“丨”。
有36圖像,例如“言”:
不知道“β”符號是有標記的作用,還是亂碼衍文。
字頭用了20個私有區字:,,,,,,,,,,,,,,,,,,,
看來,這些私有區字是全宋體的(來自部件檢索吧),跟開心宋KaiXinSong字型的私有區字不重疊。要標記,用全宋體顯示。
XML unicode源文件就有,即该字的unicode统一编码,没舍得删除,隐藏不显示即可。不隐藏就显示出了该编码所代表的字。β为源文件自带,我没换,可以任意换成其他字符,主要以示跟前字之间的区别。至于字数多了,主要是正文中有亦作“X”、也作“X”等内容,但“X”字没有字头,本人另加字头跳转,所以就多了一些,掌上百科有个宋本玉篇的mdx,字头比这版还多,什么原因我也不清楚。我也是用他提供的源文件制作的。
20多个全宋体私有区是来自部件检索,我在css中引用了字体,可跟据软件实际情况自行调整。我自己在深蓝软件上能正常显示。
有的“AA”跟“A4a”標記內容不是重複的,也許值得注意,例如:
𪗓

𥲩
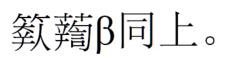
樓主用心,辛苦了。處理跳轉很麻煩。
不好意思,我在 .7z 包裝沒看到CSS,在MDD也沒有。是不是之前發的?
玉篇.css (1.0 KB)
漏发了
字头后边〔〕内的字是纸质版玉篇的正字。行序代码的后三位是此字在纸质版中的列数和字数,即最后一位数是该字所在列为第几个字,前两位是所在的列数。如054即第五列第四个字,便于对照纸质版找字核对。
瞧了一下玉篇的542部首,挺有趣的。有的是在部件檢索第一次見到的,有的字形組合沒見過。分得很細膩,例如叒、叕,呵呵。
解包 发现css没有加载
这样就行了

玉篇.mdx (750.4 KB)
用MDict,CSS文件跟mdx同名就能實現,可以減少mdx體積。在討厭的GD,mdx數據需要提到css。是規範做法但GD就那樣呆呆的。
MDict做法也有另外的好處:可以同時套上兩個css,mdd包的,和使用者在外面提供的。
确实。我以为大家都用GD的哈哈
《中華大字典》列出《大廣益會玉篇》的字條頁碼,總共有~21,915字條。(比這個 大阪大学版本 少~900條。版本不同,頁碼不合。)值得注意的是,據《中華大字典》,《大廣益會玉篇》有700多字這個大阪大学版本好像沒收。我提供當做參考而已。
《中華大字典》引《大廣益會玉篇》,另外字頭.zip (4.5 KB)
字單裡,應當有不少只是表面上的差距,因為用了不同Unicode碼位、另外字形。而且什麼算是同一個字是有爭論的餘地。但這類應當是少數。
有所更新,需要的重新下载mdx。
感谢更新,但还是排版不生效,如图 
前面不是说过了吗 GD要再加一行链接
(虽然我也觉得这样故意不兼容GD不太好
巿,甫味切。蔽市小皃。《說文》普活切。艸木市市然、象形。
市字都應作巿。
確定一下字形,數據可以更新到Unicode 15:
甾(甾):𱰭
緇(緇):𱹼

共的古文,字形有誤,𦱠是不同字,不相關。
Unicode 缺。說文作𦱹。