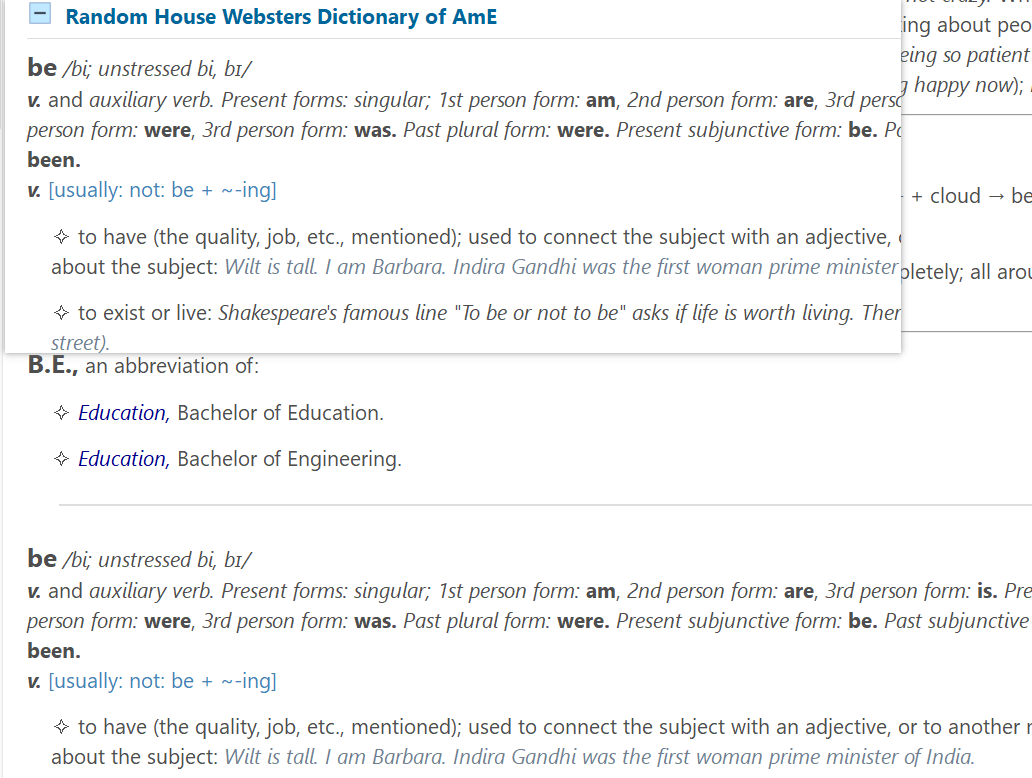
bother 词条标签错误的解决方法:
for ell in s1b.select('.rh_ex > .rh_lab:last-child'):
if ell.parent.contents[-1] != ell:
continue
for els in ell('span', string=re.compile(r'^[][]$')):
els.decompose()
ell.unwrap()
bother 词条标签错误的解决方法:
for ell in s1b.select('.rh_ex > .rh_lab:last-child'):
if ell.parent.contents[-1] != ell:
continue
for els in ell('span', string=re.compile(r'^[][]$')):
els.decompose()
ell.unwrap()
我查看了make和take词条,发现一处问题:
make词条rh_lab在rh_ex前面,而take词条rh_lab嵌套在rh_ex里面。
这个我知道,暂时不解决是因为一些 .rh_ex 的位置可能还有问题,要先把外层搞定了,再搞内层。
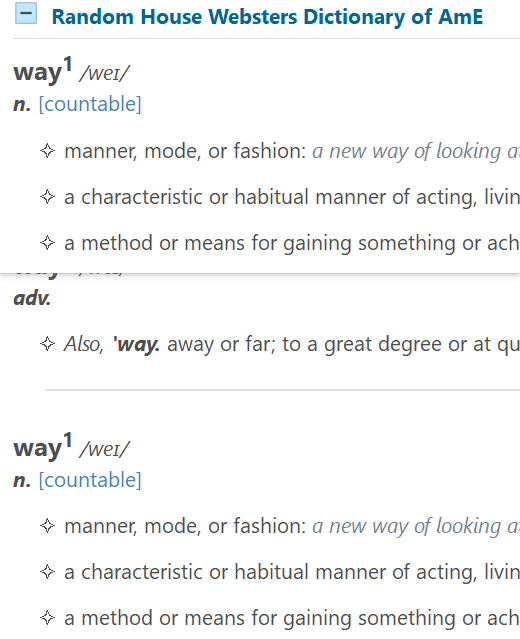
.rh_ex 位置问题,我修了很多,下面是少量代码:
dfs = ['sdef', 'def']
for df in dfs:
for de in s1b.select(f'{df} + .rh_ex'):
dps = de.find_previous_sibling(df)
dee = de.extract()
dps.append(dee)
这本词典有啥特色?首先,释义简洁,经典的一长一短结构。再就是,语法信息丰富,给了一堆 pattern。以上评价没带回忆滤镜、新鲜感滤镜。天若有情天亦老,做人没心最自由。
接力:
链接: 百度网盘-链接不存在
提取码: cud4
同意,我也是看上了这两个优点
大侠,css 与新版本mdx不匹配了。可否考虑修改更新一版呢。
反馈问题的朋友,最好不要删帖,不管我解没解决。再次感谢反馈。
可能不是缺义项,因为这本学习者词典是在兰登韦氏足本词典的基础上,删减、改写得来的。有些生僻义项没收,空缺了,很正常。重申一下,本人只解决 html 结构问题,没有能力也没有时间做校对。
看了PDF,没毛病

参照其它prefix类词条,划线处应为rh_ex标签

词组拆分需要人工逐条校对,我暂时不会做,可能永远不会做。
明天会发一新版:根据加号合并部分 .rh_lab;去除词头前后引号。
至于 iota 词条中括号多余,其它词条无此类问题,所以我不会手动更改或添一行代码替换(代码已经够复杂了);缺例句标签,找不到特征批量添加而不引入错误,我不会针对性替换(理由如前所述)。