阿弥陀佛
1
上次抓书法字典,python表现卓越。
本人完全不懂python,从0开始,用python来学习一下怎样抓取数据。请技术大神不吝指教。@hua,@ sxingbai
直接从案例开始:
比如 我想抓取 https://zidian.911cha.com/
分析地址发现用U码当地址,如“一”字地址为:https://zidian.911cha.com/zi4e00.html
好办,利用EmEditor把汉字转化成U码,得到GB列表的地址
https://zidian.911cha.com/zi7684.html
https://zidian.911cha.com/zi4e00.html
https://zidian.911cha.com/zi4e86.html
https://zidian.911cha.com/zi662f.html
https://zidian.911cha.com/zi4e0d.html
https://zidian.911cha.com/zi6211.html
https://zidian.911cha.com/zi8fd9.html
...
我把地址列表存入TXT,如:保存在D:\地址.txt
其实有了地址,可以用一些下载工具下载,如迅雷、IDM等等,但现在为了学习python,用python怎样下载网页源文件(只要TXT即可,图片另外再想办法),并存入一个TXT中。
接下来怎样做就不知道了,请技术大神指教。
。。。
网页内容分析目前先不用管,只要下载了整个页面,我可以后期再清洗数据。
求简易代码。
需要先在命令行用 pip3或者 pip安装:
pip3 install requests
之后打开 Convert curl commands to code 这个网页, 先看网页下半部份的说明,按提示打开Chrome浏览器复制Copy as cURL的内容,粘贴到网页左边文本框,会自动生成对应的 Python 代码,改下requests.get后面的网址,就可以跑起来了。
这个网址的好处是,用 cURL 生成的 Python 代码会带有身份标识,可以帮助你解决登录问题。
# -*- coding: utf-8 -*-
import requests
import os.path
from os import path
import time
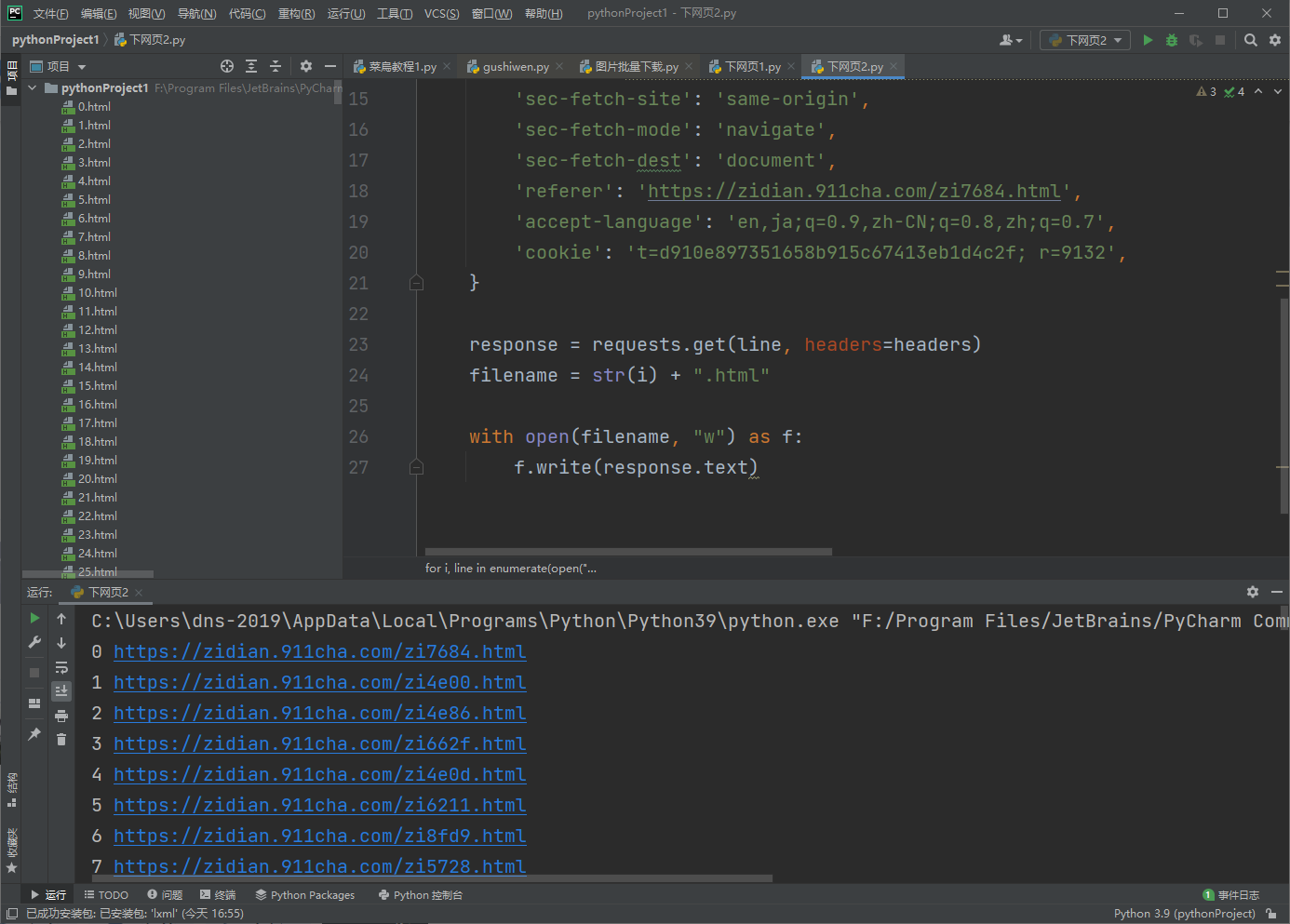
for i, line in enumerate(open("address.txt")):
filename = str(i) + ".html" # 保存的文件名
# 检查文件是否存在,存在跳过
if path.exists(filename):
continue
headers = {
'authority': 'zidian.911cha.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'upgrade-insecure-requests': '1',
'dnt': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.4 Safari/605.1.15',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'sec-fetch-dest': 'document',
'referer': 'https://zidian.911cha.com/zi7684.html',
'accept-language': 'en,ja;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'cookie': 't=d910e897351658b915c67413eb1d4c2f; r=9132',
}
response = requests.get(line, headers=headers)
# 打印文本行,去除前后空格换行,http状态码,响应内容长度
print(i, line.strip(), response.status_code, len(
response.text))
# 发现会返回空文件,检查响应内容长度,大于1000,再保存文件
if len(response.text) > 1000 and response.status_code == 200:
with open(filename, "w") as f:
f.write(response.text)
# 等待5秒
time.sleep(5)
阿弥陀佛
3
已经安装了PyCharm Community Edition 2021.1.2 x64,requests库也装了。
复制上面的代码,保存到run.py文件里,网址放 address.txt,和run.py 放同目录下。运行python3或 python:
python3 run.py
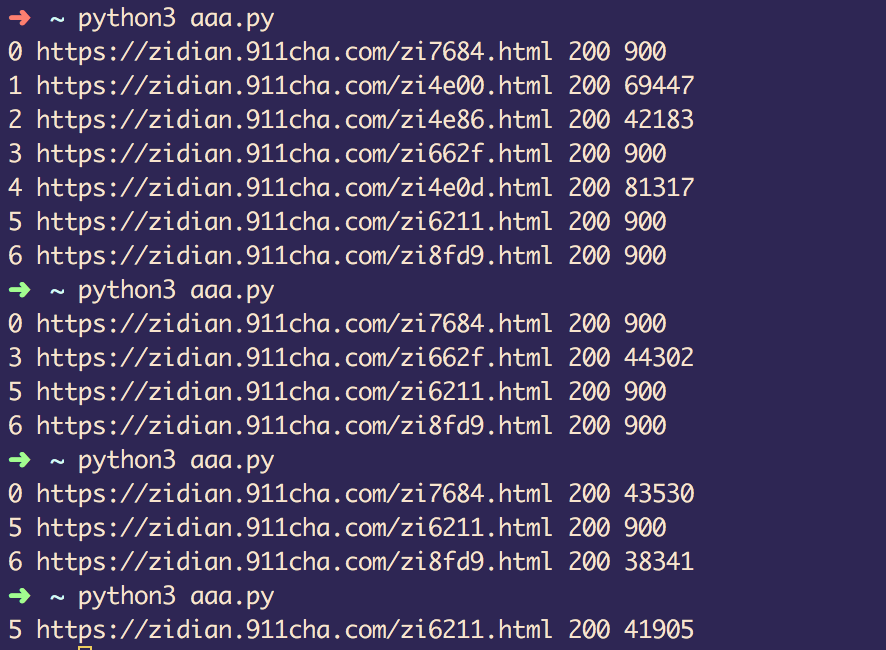
网站会返回空内容给你,多跑几次就出结果了,代码已经更新。需要删掉之前的 html 文件重新跑。下图最后的 900 是网站返回了空文件。代码里会检查返回的内容长度,低于1000的,不保存 html 文件,下次再跑。
阿弥陀佛
10
942 https://zidian.911cha.com/zi6b27.html 403 146
943 https://zidian.911cha.com/zi5948.html 403 146
944 https://zidian.911cha.com/zi80a9.html 403 146
945 https://zidian.911cha.com/zi4e60.html 403 146
946 https://zidian.911cha.com/zi6731.html 403 146
947 https://zidian.911cha.com/zi6548.html 403 146
948 https://zidian.911cha.com/zi888b.html 200 36274
Traceback (most recent call last):
File "F:\Program Files\JetBrains\PyCharm Community Edition 2021.1.2\jbr\bin\F\PY\PycharmProjects\pythonProject1\下网页2.py", line 38, in <module>
f.write(response.text)
UnicodeEncodeError: 'gbk' codec can't encode character '\U00020024' in position 10817: illegal multibyte sequence
进程已结束,退出代码为 1
没结果
你之前跑完一个正常的 html 文件都没有吗?403说明你被屏蔽了。需要跑慢点。代码已更新,加入延迟,gbk 问题,用我传的文件跑。
run.py (1.5 KB)
learn python the hard way,我是用这个入门的。
阿弥陀佛
14
0 https://zidian.911cha.com/zi7684.html 200 900
1 https://zidian.911cha.com/zi4e00.html 200 900
2 https://zidian.911cha.com/zi4e86.html 200 900
一直是这样。
正常访问能打开吗?900 说明网站那边识别了你是爬虫,所以把你屏蔽了,只返回空内容给你。原因很多,如果 IP 地址没被屏蔽,可以伪装的更像一点,可以使用 Python 操作浏览器去爬取网站内容,但需要进一步学习 Python 的基础知识。
pip install playwright
playwright install
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("https://zidian.911cha.com/zi7684.html")
print(page.content())
browser.close()
https://playwright.dev/python/docs/intro/
你复制一份你自己的 cURL 替换我代码里的,跑跑试试,只需要替换 headers 的内容,先少跑点,只放5行网址试试。
阿弥陀佛
18
@sxingbai 能否有空指点一下,不用考虑反爬、数据清洗。我需要的是 已知地址列表,如何下载整个地址表的网页的代码模板,这样类似的网站就可以套用模板。 比如您写的图片下载代码就很好用,可套用,重复使用。
lurker
19
你就按 last_idol 的提示、推荐的教程一点点往下学呗。别总想一口吃成个胖子。客观但不客气地说,之前那个下载图片的 Python 代码问题太多了,经不起问 What If。比如:网址要是有重复咋办?某次 requests.get() 要是超时咋办?