pyglossary 在编译词典的时候非常快 , 半个小时都不需要 , 它的原理 跟这个有什么不同吗? 后面我尝试下其他的词典试试看, 有没有可能是这本词典mdx 格式当初用的打包工具的问题呢? pyglossary 转换这本词典是失败的 , 直接失败 。其他词典就没问题。 我当时在隔壁论坛问过了 说好像是打包工具的原因 , 无法解包
第一: 最后再说一次转换为 macos 词典时的时间问题, MDX 转换为 macos 词典, 我试过 macmillan, RHWDAE 这两个, 速度都是很快的, 这次尝试的 concise-bing 遇到的问题前面回答已经说过. 将 MDX 转换为 macddk 所需的文件, wikit 速度是很快的, 但是剩下的是 macddk 的工作, 主要的时间瓶颈在 macddk 上. 希望我这次说清楚了, 以后关于这个时间问题, 我就不再赘述了.
第二: pyglossary 的源码我只看了一部分, 我之前说过, 最终都是调用 mac ddk 命令行去编译生成的 xml, mac ddk 的脚本户去检测你的 xml 是否正确, 如果不正确就无法编译(这就是为什么你要修改中间文件, 然后再编译), 一般来讲, mac ddk 对文件检测通过, 它自己编译应该是没问题的. 你说 pyglossary 转换直接失败, 这你可以去他们项目主页问一下.
2 个赞
![]() 不好意思
不好意思
如果就转换几个词典文件,到网上找找别的格式或者叫作者帮你转换下,没必要这么麻烦开发者,别人电脑没bug,在你电脑上就可能有bug
1 个赞
谢谢, 可能吧。
1 个赞
刚刚转换成功了, 发现连单词都没有 比如 well 、take
1 个赞
想咨询一下,stripkey 这个选项到底会对 mdx 做什么,以及 mdx 索引词头的方式是什么
stripkey 这个选项会去掉词条中的符号然后再排序,如果和mdxbuilder去掉的符号不一致,就会导致排序异常,读取的时候也会错漏词条,这个符号的范围需要制作工具、词典软件和官方的mdxbuilder三者保持一致才行。
参考 #386
如果是 mdict-utils 来制作词典的话,它会去掉处理上面的短横(连字符),但长横它不会处理,长横就会参与到字符的排序中去。
词头排序完,然后按顺序每64k的字符压缩在一块,比如这个64k的压缩块里有1024个词头,词典软件会读取第一个词头和最后一个词头,按顺序把所有压缩块的前后词头提取出来去掉符号后就成了索引(第一次stripkey),当需要查找词头的时候,先去掉词头中的符号(第二次stripkey),通过词头和索引对比,判断词头所在的压缩块位置,确定压缩块把词头解压出来后,再次去掉符号(第三次stripkey),按顺序对比具体的词头。(大致是这样,具体细节模糊了)
2 个赞
请教demo这种多词典server是怎么实现的?Wikit (Beta)
$ wikit server
wikit-server
Run wikit as an API server
USAGE:
wikit server [FLAGS]
但现有的flags只有c h v三者,都和server无关
谢谢你的解答
我用好多关键词翻了一遍论坛,这里提到 stripkey 的行为是去掉 ASCII 范围内的非字母,即只剩下大小写共52个。但是不知道出处是哪里,原贴编辑掉了。并且没有提到 ASCII 范围外的字符,或许是原样保留或许不是。
我觉得还是应该逆向一下 MDXBuilder 来找到答案。
1 个赞
这个有兴趣可以看一下 wikit 源码, 目前我在用 tauri 来编写 wikit-desktop 桌面程序, 基本思想是使用 client-server 模式, 因此会增强 server 这方面的功能, 以数据库的方式来实现查询(数据库充当索引功能, 不过后续也会参考其他检索技术比如 elastic 中用到的技术来设计新的索引方式), 具体文档还需要等我实现完了才会更新, 如果对 server 功能感兴趣, 可以先等一等. 先放几张桌面端(wikit-desktop)截图:
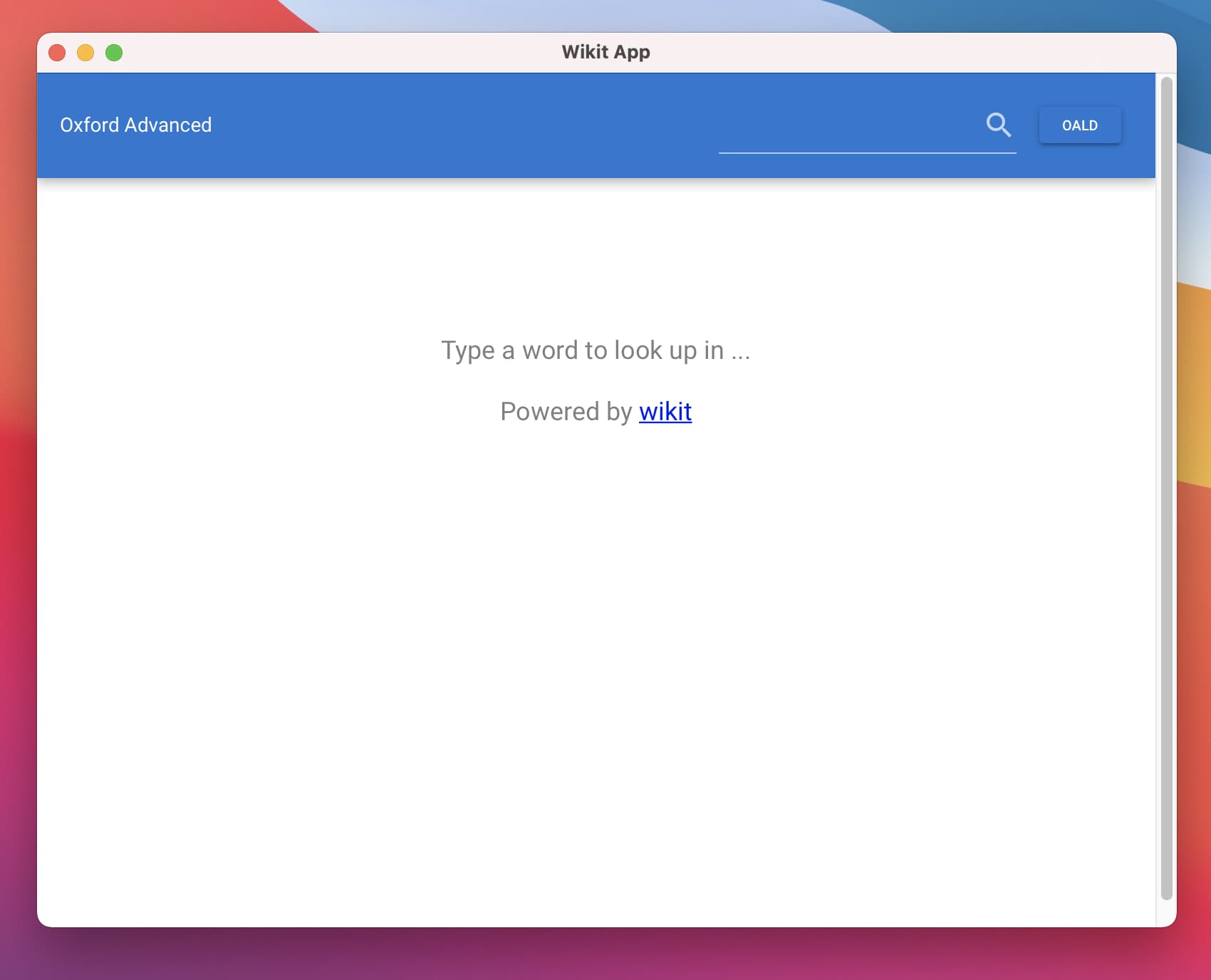
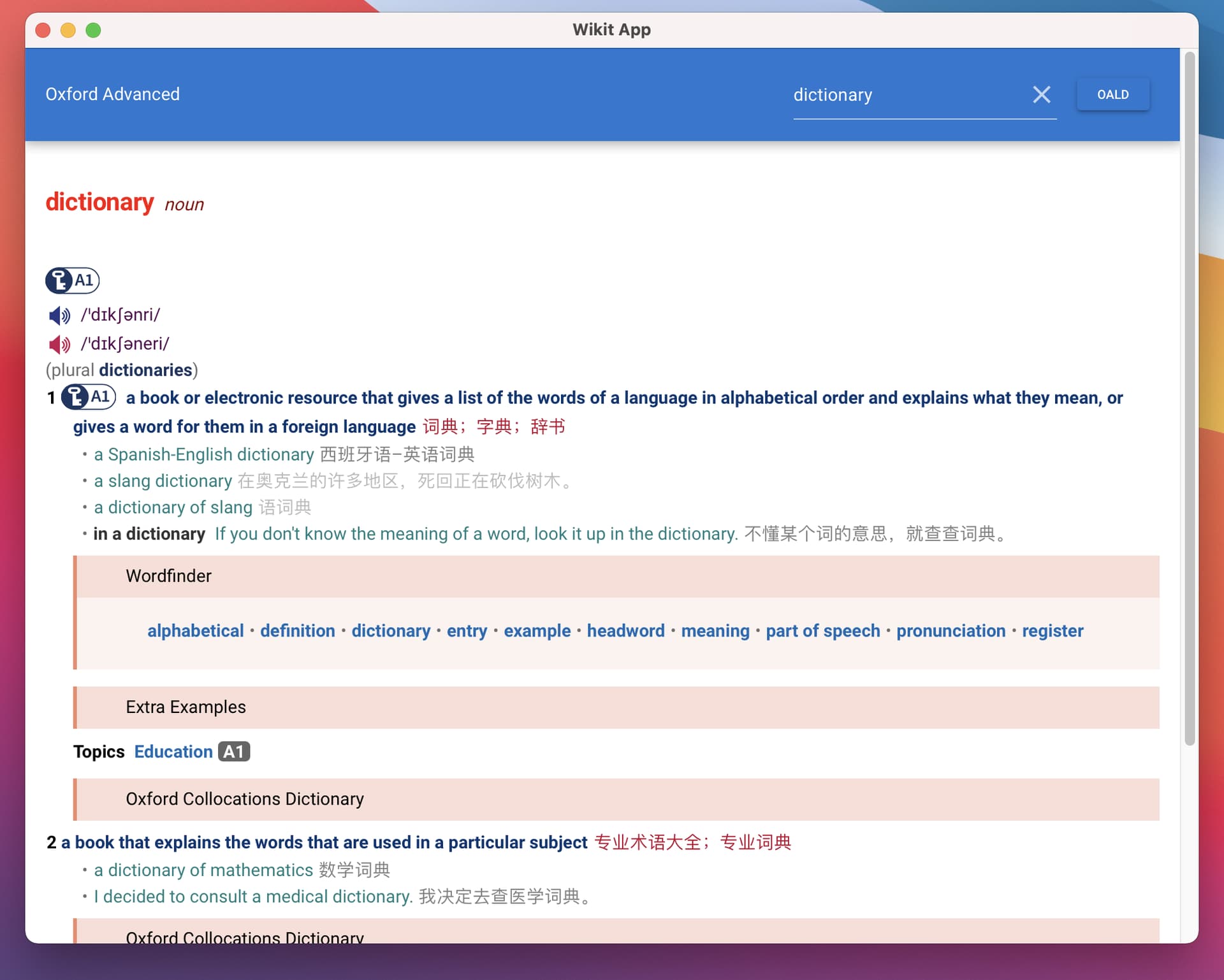
2 个赞
范围是限于词头部分还是包括正文部分?
但我发现有些mdx经过多种工具加工,在某个链条中把词条正文的所有格符号给搞没了,因为原文本使用的是全角的’,而非半角字符'。典型的是目前Use the Right Word的英文版mdx,造成理解困扰。
范围是词头中的符号吧?
虽然mdx2.0 算是基本开源了,但没有统一规范的结果就是有时候兼容性会有小毛病
1 个赞
应该是限于词头的,毕竟没有理由去掉正文里的符号,并且这个验证起来也很简单,你可以试试。
1 个赞
还有一个问题,看前面讨论,好像都说 mdict 格式的索引很烂,我想知道烂在哪
请教下,用了楼主的example执行wikit create的时候,报错:Error:[cli/src/main.rs].[148]:Failed to get input resource format
@richman 可以到 git 项目里面提 issue
1 个赞
看了wikit源码,感觉非常好。准备开始用桌面版,也会用wikit格式制作生词词典。
2 个赞
I am sorry, I do not understand why mdict-utils should be avoided over the official mdxbuilder. Perhaps this is a translation issue.
很抱歉,我不明白为什么应该在官方mdxbuilder上避免使用mdict-utils。也许这是一个翻译问题。
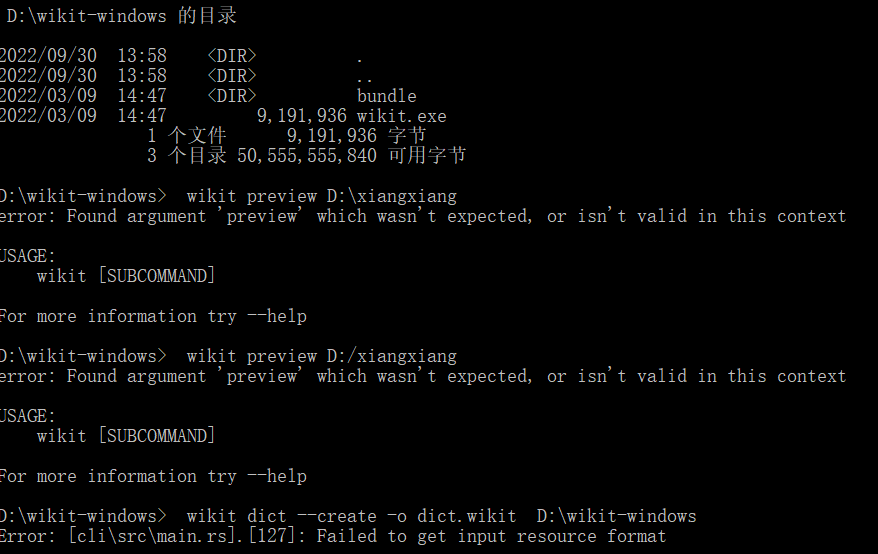
刚找到这帖子基本没看懂,wikit tauri 这名词都是天书。已经有人开始用了?只有一个疑问,既然制作工具和客户端都重新做了,貌似就没有必要和 mdx 有什么瓜葛了,mdx资源转出来也不难。是不是有什么原因不能直接用现成的数据库文件格式如SQLite的.db格式,甚至是直接用mdx的源文件txt,而资源包就直接是zip文件