给欧陆和其它竞品都配上ocr识别库嘛,人家拿着锅碗瓢盆,跟屠龙宝刀怎么去比吖 - 楼主要是能够点选或Hook一下图片上的文字就更赞啦,哈哈哈
我是觉着吧,楼主太偏颇啦,拿自个的Hook去跟竞品的OCR比 ,没多少意义啦 - 其它竞品也是可以接入AHK的,或者直接调用什么Capture2text什么的,但都没有做。
楼主其实也可以考虑一下的啦,现在流行自主研发,其实也不必在意是否自主啦,如欧陆和GD++还不是站在高人的肩膀上做了些改造嘛,但技术创新和核心竞争力是一定要有的啦
给欧陆和其它竞品都配上ocr识别库嘛,人家拿着锅碗瓢盆,跟屠龙宝刀怎么去比吖 - 楼主要是能够点选或Hook一下图片上的文字就更赞啦,哈哈哈
我是觉着吧,楼主太偏颇啦,拿自个的Hook去跟竞品的OCR比 ,没多少意义啦 - 其它竞品也是可以接入AHK的,或者直接调用什么Capture2text什么的,但都没有做。
楼主其实也可以考虑一下的啦,现在流行自主研发,其实也不必在意是否自主啦,如欧陆和GD++还不是站在高人的肩膀上做了些改造嘛,但技术创新和核心竞争力是一定要有的啦
也就为了自己用的舒服罢了,无意苦争春
春华秋实嘛,大家都是来建设论坛的,楼主其实可以考虑一下啦
搞不定,也无意搞,还望真正高手出马为你解忧
这可不是个人需求啦 - 利坛利民嘛,况且也不需大劳力 - 纯粹技术堆砌,前无故人,功德无量,楼主考虑一下嘛,好东西别藏着掖着的嘛
鄙人不才,没有这番技术,还望高手解答
依楼主的散文水平,不需要先生的啦
哈哈哈哈,舞刀弄剑一番还藏着掖着莫不是私下里要…
别在这儿揶揄别人
原来还能这样玩,厉害了。话说回来,上面的比较中 Capture2Text 和 GD Nonwill 都是用的 Tesseract 引擎,不过同时识别多语言前者貌似搞不定。功能上比较,各有千秋吧。
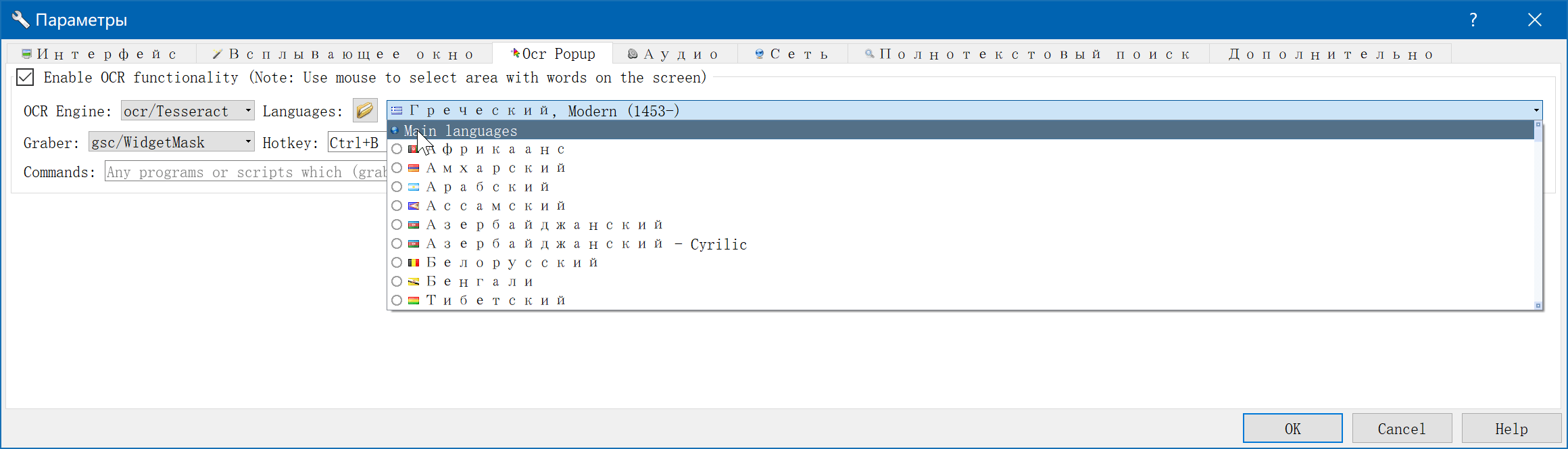
看我截图嘛,GD++中貌似选中大分组后,这个组下选中的语言都参与了OCR的。
其实Capture2Text中也是可以使用多个语言的吧,但调用程序应该是运行时传语言参数进去的啦,可以适当修改一下 AHK 的脚本应该能实现吧(这个具体我就不懂啦,只能大致看个所以然)。
只是不管如何,都是Tesseract 的功劳啦,GD++的所谓 OCR 和 划图 插件,应该是干了 Capture2Text 一样的活吧
http://capture2text.sourceforge.net/#command_line
-l, --language <language> (OCR language to use.)
我试了一下,好像一次只有一种语言生效,也许是姿势不对。
我用它,主要为两个:识别整行 和 识别光标前方整行 功能。GD++要实现此,也许还需更深度整合 Tesseract。
不过话说回来,识别大块区域、多种语言,似乎并非刚需,使用场景略感局限。
群里有讨论过这个,n大说这个工作量太大啦,而且也不实用 - 毕竟是款查词典软件,不需要pdawiki上那些个OCR作词典软件的功能 - 参数太专业我辈小白也都弄不明白啦
是的,只能拿来炫技的啦,一般不会有人这样花里胡哨的操作啦
但选中分组后,随意识别分组下的语言,同时省去了划屏前去修改设置ocr语言的麻烦,还是不错的啦 - 随你俄中英,都不需要再费心去设置里调教了
楼主要深入研究 Tesseract 并应用到 AHK 词典软件中去,那是最好的啦,可以参考个开源软件的:
它里面对 Tesseract 的参数设置做了精细处理的,貌似也是俄罗斯大佬开发的,只是颜值上与楼主的大作完全没法比啦,仅供参考还是可以的吧
感觉还是应一分为二地看,同时勾选多个语言分组,方便是方便了,识别速度和识别率却下去了,对于复杂的图片环境还是不希望把英语识别成了鹅语。若可有一个快捷键切换语言则是极好的。
这个操作本来就没必要的,精通八国联军的精英们估计也不会用到啥OCR取词的啦
这个也是有的哟 - 彩蛋,没开放到界面直接配置而已 - 大致要等到 Chrome 浏览器核心版本出来才会放 ui 上啦
看来你与Nonwill大佬有过深入交流,也许你可与其谋求实现 “嵌入管理和下载freemdict网站上的词典的功能”
没有啦,n大不用电报,我们有个单独的电报群,只沟通学习软件相关技术 - 其实也就是指GD和Anki啦,里面有两位负责linux和mac的会及时与n大邮件沟通,另外n大收到的所有GD++的用户需求邮件都是转发到那里讨论的
哈哈,这个就不说了,去年初有这么一个邮件需求的,n大说有一丝儿交情在里面,有点难为,但最后还是没有做 - 主要是大家讨论下来不想跟版权利益方产生啥子矛盾, 现在想想要是做上了该多好啊
求适用 tesseract-ocr-w64-setup-v5.0.0的中文语言包,谢谢。(目前我在图片版的PDF上只能框选英文,不能框选中文。)
貌似都跑去pdawiki挖矿啦
楼主自个儿去github或镜像站上下嘛