請教 正則執行步驟怎麼看
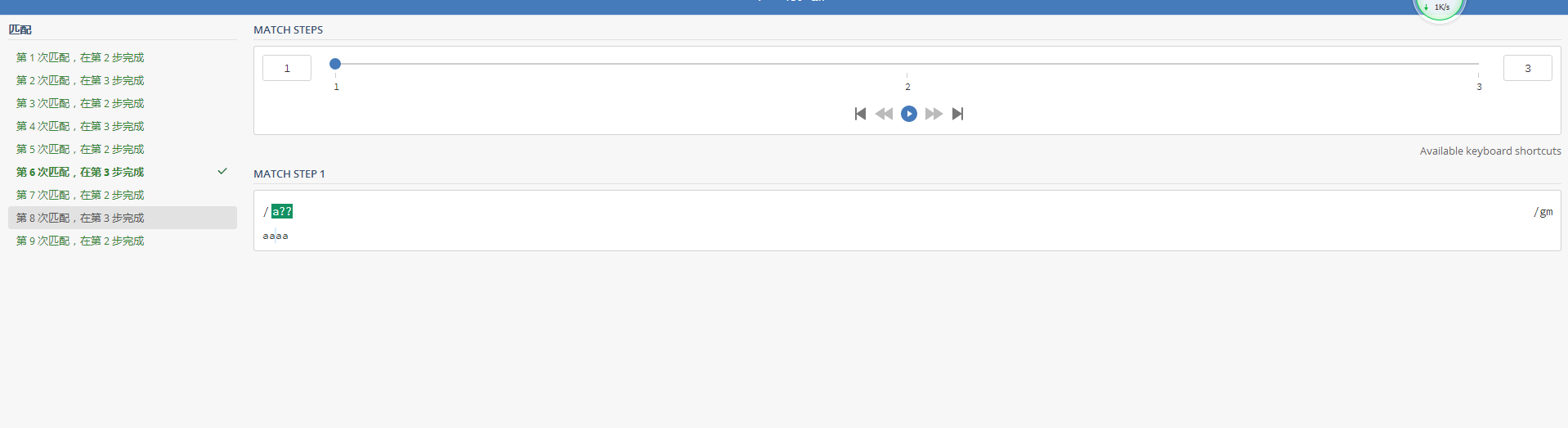
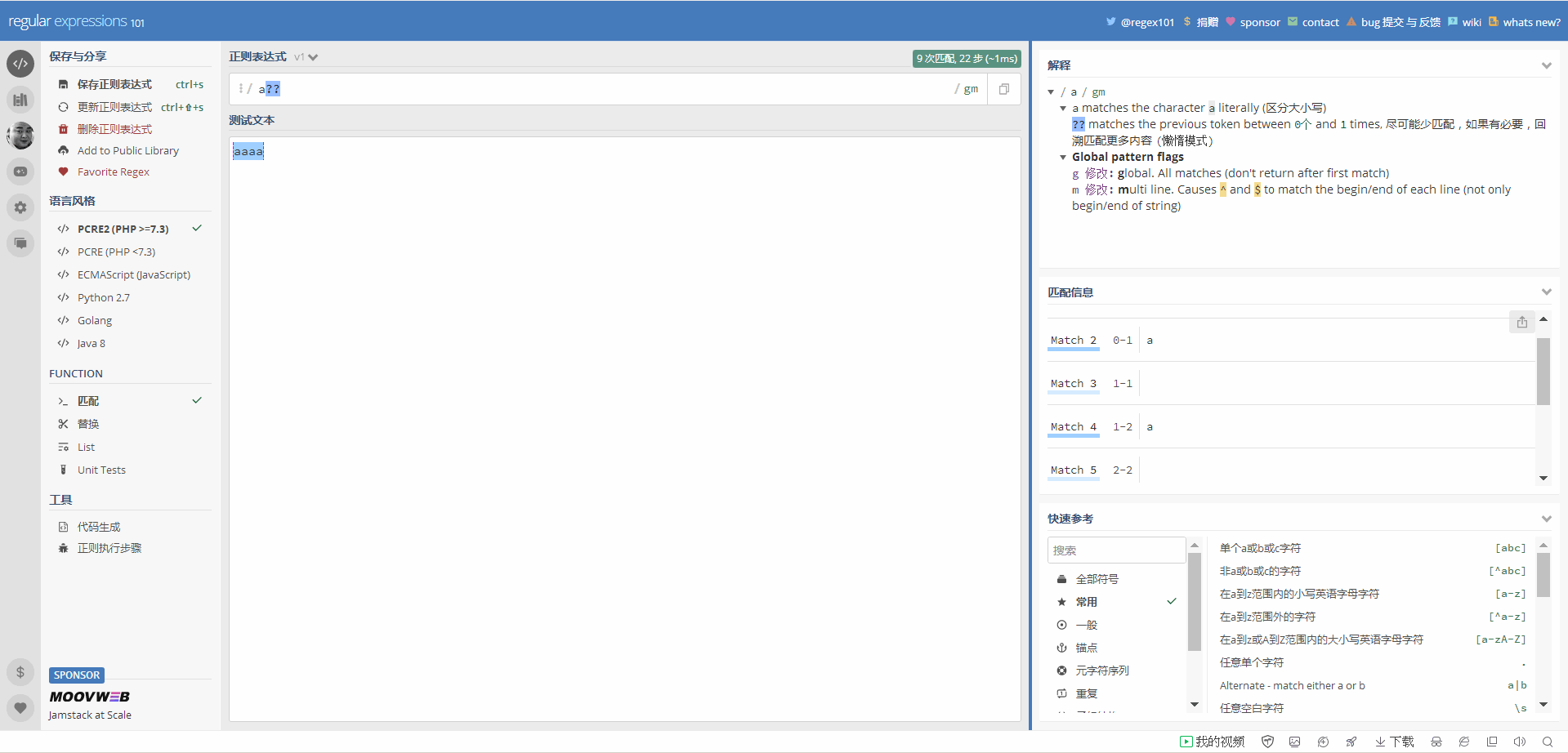
a?? 去匹配 aaaa
為何是匹配了9次, 這匹配的次數怎麼算
Regular expression tester with syntax highlighting, explanation, cheat sheet for PHP/PCRE, Python, GO, JavaScript, Java, C#/.NET.
a?
Zero or one a’s (greedy)
a??
Zero or one a’s (lazy)
a*
Zero or more a’s (greedy)
a*?
Zero or more a’s (lazy)
a+
One or more a’s (greedy)
a+?
One or more a’s (lazy)
貪婪和懶墮模式…看不太懂
感謝 endnote 兄指點迷津… Thanks a lot
5个“间隙”,加上4个 “a”,不就等于9次匹配么?
“a?” 匹配的是0个或者1个 “a”,后面的那个 “?”,代表非贪婪模式,也是说优先匹配0个 “a"(间隙),退而求其次匹配1个 “a”。正则表达式能匹配“间隙”,比如 “\b” 和 “\B” 就匹配与 “\w”、“\W” 有关的“间隙”。
regex101 网站,点击右上角“汉堡”图标可以看说明的。
fruition:
每個步驟的解析
耐心看,实在不懂就下一段。大和尚太过于花心。。。。
控制权和传动
正则表达式由左到右依次进行匹配,通常情况下是由一个表达式取得控制权,从字符串的的某个位置进行匹配,一个子表达式开始尝试匹配的位置,是从前一子表达匹配成功的结束位置开始的(例如:(表达式一)(表达式二)意思就是表达式一匹配完成后才能匹配表达式二,而匹配表达式二的位置是从表达式一的位置匹配结束后的位置开始)。如果表达式一是零宽度,那表达式一匹配完成后,表达式二匹配的位置还是原来表达式以匹配的位置。也就是说它匹配开始和结束的位置是同一个。
源数据:123
讲解:首先正则表达式是从最左侧开始进行匹配,也就是位置0处进行匹配,首先得到控制权的是正则表达式中的“1”,而不是源数据中的“1”,匹配源数据中的“1”,匹配成功,将源数据的“1”进行保存到匹配的结果当中,这就表明它占有了一个字符,接下来就将控制权传给正则表达式中的“2”,匹配的位置变成了位置1,匹配源数据中的“2”,匹配成功,将控制权又传动给了正则表达式的“3”,这时候匹配的位置变成了位置2,这时候就会将源数据中的“3”进行匹配。又有正则表达式“3”进行传动控制权,发现已经到了正则表达式的末尾,正则表达式结束。
哇!luker 兄,一語點出重點觀念…現在才知道間隙也能匹配…讚!…
endnote 兄,謝謝你,讚!漂亮了!解釋好詳細…我得好好看看研究一下
网站右上位置,图标是“三根横线”,点进去之后,前两个选项就是对匹配结果的解释。
lurker:
写的跟佛经一样,越看越迷糊
哈哈,也许吧。各花入各眼。这篇文章阅读量- 33万,比较适合我。
看看大和尚的机缘如何,不过烦恼即菩提,我猜他马上就要初窥门径了。但最首要的,需要让方丈棒喝一下,罚他面壁十年不得近酒色,方能登堂入室。
Endnote 兄,小弟已關機很久了!已快要不能人道了…哈!哈哈哈哈哈!
endnote 兄,謝謝你詳細地說明,終於搞懂匹配和位置,和你說的控製權和傳動了… thanks again
Regular expression tester with syntax highlighting, explanation, cheat sheet for PHP/PCRE, Python, GO, JavaScript, Java, C#/.NET.
fruition:
搞懂匹配和位置
位置是行首行尾之类的信息,匹配是字符内容。程序其实很笨,你说不清楚它就会乱七八糟的找。
明白这些概念虽然才算刚入门径,但却是至关重要的基础概念。
继续找例子来揣摩,熟能生巧
endnote 兄
Regular expression tester with syntax highlighting, explanation, cheat sheet for PHP/PCRE, Python, GO, JavaScript, Java, C#/.NET.
贪婪与懒惰的理解,首先要知道
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。
表达式怎么写,是基于充分认识你所需处理的文本之上的。
如果所需处理的文本变的更复杂了,表达式可能需要调整。
再次感謝 老哥帶路指引,都不知道有這麼多教學…比YouTube還多…謝謝啦!
fruition:
有這麼多教學…比YouTube還多
给大和尚再推荐一个正则Interactive Tutorialhttps://www.regexone.com/
①一個問題請較,若是要替換的字串很長,已超過 emeditor or ultraedit 替代框內的長度,該如何處理<p><a id="0001" href="entry://C4">Jump to Chapter 4</a></p>@endnote @lurker