哦,好的,还是谢谢啦
2 个赞
想起來,‘等寬’是monospace的意思嗎?(我母語是英語,有的詞不熟悉。)如果是monospace,那EmEditor更適合用monospace。
1 个赞
我也不太清楚哦
1 个赞
您这个有个字的显示也是有问题的

是的。zsbd
1 个赞
手机调用FSung-F无反应,不知道大家是否有能调用的,是不是文件太大了?
辞海字体和中华书局字体兼容吗?
雖然如此,中華書局字體與全宋體,有的字體不合。
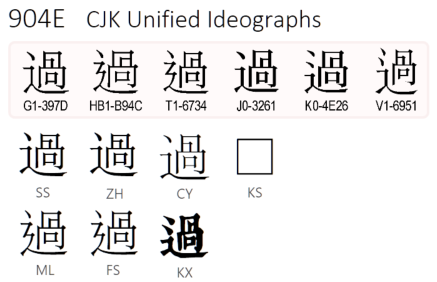
角

SS:Windows SimSun 中易
ZH:中華書局
ML:Windows MingLiU 細明
FS:全宋體
KX:康熙字典(舊字體)
過
廣

在部件檢索/全宋體,標準碼位的“廣””顯示舊字體,新字體在私有區(圖像的右下邊):

總之,若字有舊體、新體之分,但Unicode只分配一個碼位,就要特別注意全宋體字形。我是針對製造mdx而言。字體不同,總筆畫也變了,跟紙書索引的說法也會出衝突。
2 个赞
一、中华书局出版《中華大字典》等古籍的专用字体“中华书局宋体02平面”ZhongHuaSongPlane见
或
二、商务印书馆印刷《辞源》的字体为方正辞源宋体 FZCiYuanSong见
以上这几种字体都是委托方正开发的,码位不一定百分百一致 ,但可能都源于 方正宋体S SIP超大字符集 ,应该说大部分一致吧。这些字体本网站都有,需要花时间比较。
3 个赞
漢語大字典,3446頁:“萈,山羊細角者。”

字的上頭是“艹”(羊)而不是“艹”(草)。這個字形,只有全宋體能顯示。中華書局字型(圖裡標“ZH”)也不行。辭源(CY)和細明字型(ML),起碼用了四個筆畫的草頭,還算接近。

1 个赞

請注意:「酉」部件已出現在計數類天干地支,不必重複在宅具類,刪了。
我建議:若不勾選「無理拆分」和「包容異體」,搜尋會更快、更準;找不到字才勾選。
界面版本:2022.1.6更新。
html版反應最快。用 FireFox/Chrome/IE 打開,然後在遊覽器加 bookmark.
核心程序的修改(跟WFG商量過):
- 巕@艹→䒑(更新到Unicode 14.0字形)
- 瘝 @疒𥄳→疒罒!疒𥄳
- 𭟹𮂂𮃻𮐻𮞭𮨘:@㠯→㠯
- 𰯽𰯾𰯿𰰀𰰁𰰃𰰄𰰅𰰆𰰇𰰈𰰉𱃺:@舌→
- 𱁭@靑→青
- 啓𪤔𫎠:@戸→户
- 𡴟@䶹(手)→屮(草)(說文:𡴟,“从𣎵。”)
- 𥅱@≅→屮(草)
- 𢟃𣂹𤔠:@≅→䶹(手)
9 个赞
您好,最新版本在nonwill的goldendict上无法显示部件界面,希望检查一下,多谢了
你的记事本得引用全宋体的字体
1 个赞
Unicode14是九月14才能正式发布呢吧,到时候wfg估计会更新
14新增加的汉字不多吧估计几百个?我是瞎猜的,官网的文档都是英文的啊
Unicode 14.0加了9個漢字,全宋體已經提早加了其中8個。
一個字是特別為《漢語大字典》而加的: 619頁,第5字:𫜸( U+2B738),讀huà。之前是用相容字叱(U+2F83A)來代表,字體不合。
一個加了“𨞪”的簡化字,古地名。《漢語大字典》只收了正體字,沒收它的簡化字。
也有 公安部治安管理局 提供的:
- 鿾 桂平县地名。https://hc.jsecs.org/irg/ws2017/app/?find=GDM-00031
- 鿿 南海市地名。https://hc.jsecs.org/irg/ws2017/app/index.php?find=GDM-00085
另外有三個澳門字,一個港字,一個越南漢字。
14.0,除了新字以外,有的舊字也改了規範字形,這方面全宋體還沒更新,雖然部件檢索程序已經更新了一部分。
最近最大的變化還是Unicode 13.0,其中有 2,000《漢語大字典》的字頭,害得我花了一個禮拜把原來mdx私有區字改成標準字。還在整理一些東西,所以這個mdx沒發。
4 个赞
我總是勾選“複製模式”(能夠自動複製所點的字),所以不會碰上那個問題。
不夠選的話,就會跳到unihan網頁去查字。我覺得這個功能沒多少用,不用也不虧。在遊覽器,這個程序是正常的,不知道在MDict環境為啥出事。
unihan資料庫網頁好久沒更新了,而且他的“字條”不提供該字的規範字形表(Unicode Code Chart),所以沒有價值。理論上,Unicode Code Chart PDF內容都應當拷貝上去。也許因為知識權而不這樣做,或是他們缺人工。
不知道是否有这样子的工具:
利用部件檢索找到某字的Unicode码后,
想用该码位值,去查找PC硬盘上某个字体font文件里头、该码位值有无对应的字(如有能显示该对应字)。
要是一次就能同时查找多个不同字体font就更好了
如果不是要在部件检索的网页里直接实现的话,可以参考这个看看
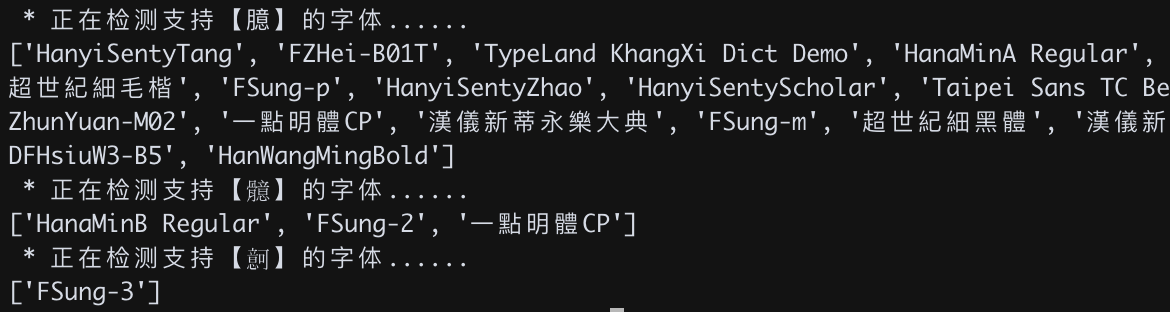
import unicodedata
import os
import sys
from fontTools import ttLib
fonts = []
for root,dirs,files in os.walk("/Users/usr/Library/Fonts/"):
for file in files:
if file.endswith(".ttf"): fonts.append(os.path.join(root,file))
FONT_SPECIFIER_NAME_ID = 4
FONT_SPECIFIER_FAMILY_ID = 1
def shortName( font ):
name = ""
family = ""
for record in font['name'].names:
if b'\x00' in record.string:
name_str = record.string.decode('utf-16-be')
else:
name_str = record.string.decode('latin-1')
if record.nameID == FONT_SPECIFIER_NAME_ID and not name:
name = name_str
elif record.nameID == FONT_SPECIFIER_FAMILY_ID and not family:
family = name_str
if name and family: break
return name
from fontTools.ttLib import TTFont
def char_in_font(unicode_char, font):
try:
for cmap in font['cmap'].tables:
if cmap.isUnicode():
if ord(unicode_char) in cmap.cmap:
return True
except:
return False
def test(char):
print(" * 正在检测支持【" + char + "】的字体......")
array=[]
for fontpath in fonts:
font = TTFont(fontpath)
if char_in_font(char, font):
tt = ttLib.TTFont(fontpath)
array.append(shortName(tt))
return array
for uni in [b'\\u81c6',b'\\U00029aa3',b'\\U0003049a']:
char=uni.decode('unicode-escape')
print(test(uni.decode('unicode-escape')))
1 个赞
谢谢提供代码~
可见各个字体的同一码位,对应的字有可能不一样。
这种工具对于制作生僻字较多的电子书挺有用的,可以帮助选择合适的字体。
遥想下一个功能是,对于某种字体尚不存在的字,能生成一个类似风格的图片。比如用选定字体中的月和意,动态合成一个与本字体风格类似的“月意”出来。
臆想一下哈。
關鍵詞是對應。字形“對”才對應,也就是說,拆分出來的部件完全一樣才對應。
問題是只有全宋體被index過,有完整的拆分序列。雖然中華大字典提供了IDS(ideographic description sequence)信息,他做得很隨便,不規範,從他的IDS不見得能夠準確地構造出來中華書局字型的字形。
再說,很多部件不成字,因此沒有Unicode編碼,必須用私有區部件來創造一個拆字的“語言”。總之,除了全宋體以外(原來用全字庫IDS當基礎),其他font沒被index,甚至沒有完整的做index的“語言”。沒有index的話,你只能用肉眼判斷是否是“對應”字,自然沒有程序能夠準確地處理。
字形不僅是地區的差別,比方說,細明跟全宋體都是所謂繁體字字型,但它們字形(即拆分出來的的部件)並不一致,尤其是B擴展區的字。辭源字型跟中華字型都是大陸的,甚至是同一個字庫製造的,但它們的字形也有分歧。
上述,針對“一碼多形”的字碼而言,不是講字形固定的字(像大陸用的簡體字)。
unicode中日韓字符的基本設計畢竟是讓不同寫法共用一個編碼。
我作了個 全漢字碼字形譜mdx 來做這個,曾經有念頭把所有多形的字碼標上,但又回到上述問題,必須有index才能做成,要不然每個字碼要用肉眼手工去標。
1 个赞