前几天,侄女问我得意洋洋这种格式的成语还有哪些,我说了几个,但显然不够多。 于是想用正则提取一下一些成语词典的词头。
(\w)\1+$
^(\w)\1+
我还不会搜索相邻两个字不重复的情况,请方家指教。
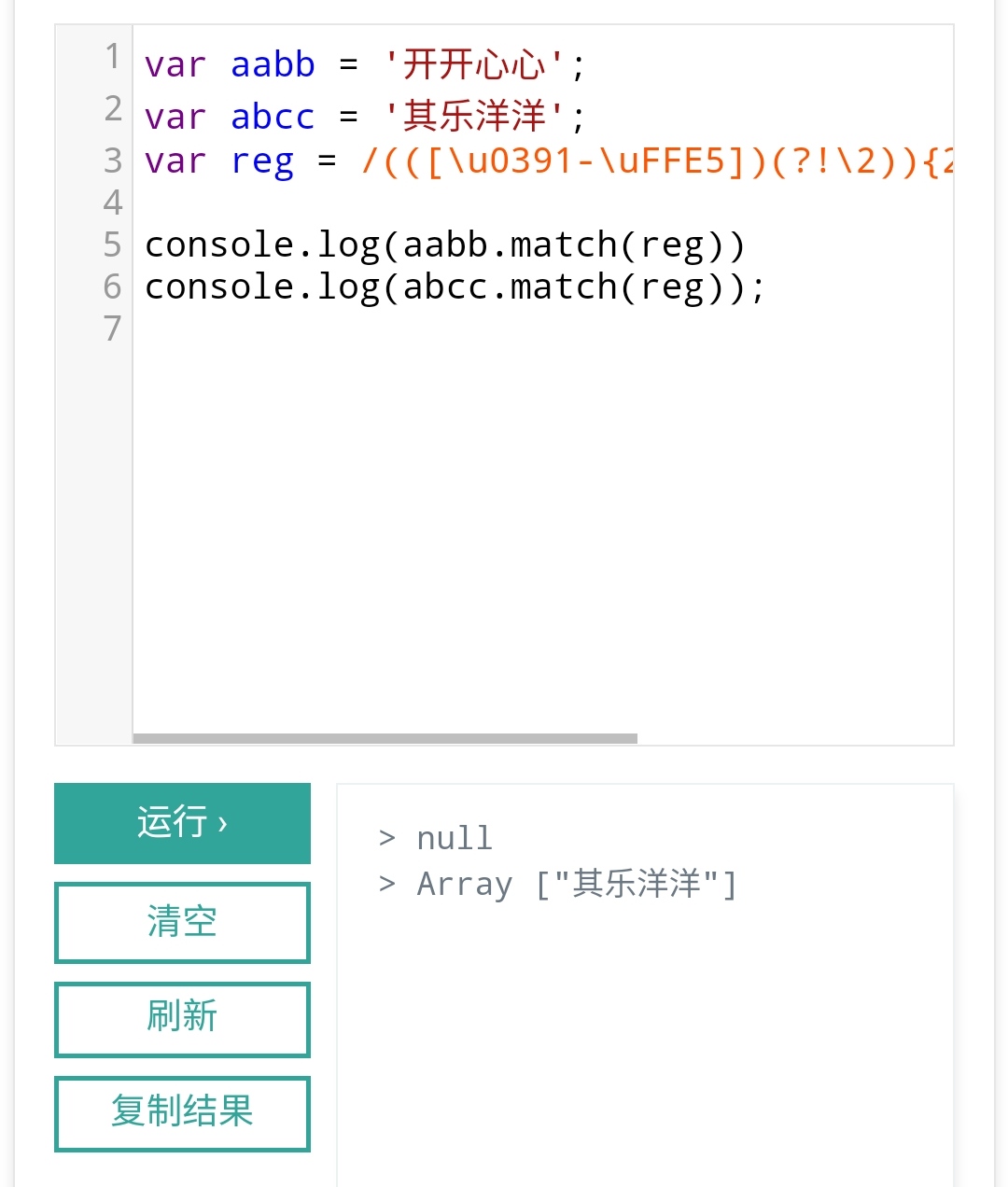
(([\u0391-\uFFE5])(?!\2)){2}[\u0391-\uFFE5]{2}$ (JavaScript 的 \w 匹配不了汉字)
(([\u0391-\uFFE5])(?!\2)){2}[\u0391-\uFFE5]{2}$
\w