man
22
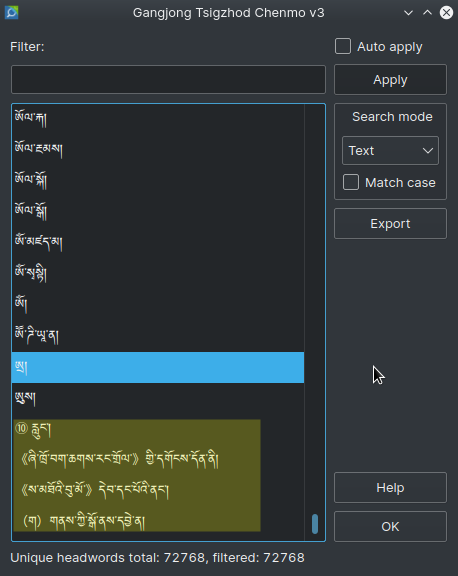
您辛苦了,這些數字開頭的都是在釋義內,這部詞典帶百科性質。我又看了一下代碼,發現有相當一部分的詞條是兩行或者多行。圖1中的གསང་སྔགས་བླ་མེད་རྒྱུད་གསུང་ཚུལ是一個極端例子,詞條正文較長,除了釋義以外,還對其中的五個例子做了說明。以(1), (2)等來分割子義項的似乎只有這一條,但以①, ②等來分割的則共有8540條。我想出了以下四條正則式來找出這部詞典中有多行、混亂的詞條,共找到3622條,其中有些可能沒有問題,沒有找到的可能還有。
-
<p class="body"> *[⓪①②③④⑤⑥⑦⑧⑨⑩⑪⑫⑬⑭⑮⑯⑰⑱⑲⑳㉑㉒㉓㉔㉕㉖㉗㉘㉙㉚㉛㉜㉝㉞㉟㊱㊲㊳㊴㊵㊶㊷㊸㊹㊺㊻㊼㊽㊾㊿]
找出圓圈數字另起一行的
-
<p class="body"> *[〔༡༢༣༤༥༦༧༨༨༩༠།་༐༒ྃ༈༄༅༆༇྅༼༽༾༿༑༔༺༻྄.]
藏文數字和其他符號另起一行的
-
span> *[⓪②③④⑤⑥⑦⑧⑨⑩⑪⑫⑬⑭⑮⑯⑰⑱⑲⑳㉑㉒㉓㉔㉕㉖㉗㉘㉙㉚㉛㉜㉝㉞㉟㊱㊲㊳㊴㊵㊶㊷㊸㊹㊺㊻㊼㊽㊾㊿]
剩餘的除①外圓圈數字另起一行的
-
་<
該行以་結尾,這樣的情況是文章還沒有完
-
">[^ ]+ +<[^་]*?$
該行只有一個藏文“塊”,即只有詞條名或詞條釋義(或釋義的一部分?)
五條加起來:
་<|<p class="body"> *[〔༡༢༣༤༥༦༧༨༨༩༠།་༐༒ྃ༈༄༅༆༇྅༼༽༾༿༑༔༺༻྄.]|<p class="body"> *[⓪①②③④⑤⑥⑦⑧⑨⑩⑪⑫⑬⑭⑮⑯⑰⑱⑲⑳㉑㉒㉓㉔㉕㉖㉗㉘㉙㉚㉛㉜㉝㉞㉟㊱㊲㊳㊴㊵㊶㊷㊸㊹㊺㊻㊼㊽㊾㊿]|span> *[⓪②③④⑤⑥⑦⑧⑨⑩⑪⑫⑬⑭⑮⑯⑰⑱⑲⑳㉑㉒㉓㉔㉕㉖㉗㉘㉙㉚㉛㉜㉝㉞㉟㊱㊲㊳㊴㊵㊶㊷㊸㊹㊺㊻㊼㊽㊾㊿]|">[^ ]+ +<[^་]*?$
這樣看來,有很多 <p class="Body">和該行第一個空格之前 的文本其實不是詞條名,而是釋義的一部分。如果需要手動編輯文件或其他任何事,請您和我說。
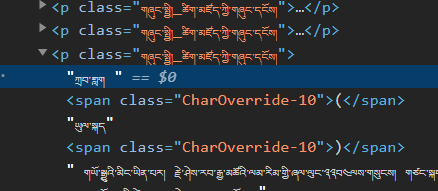
詞條名後的括號是指下圖中這種嗎?這種是說明詞條的詞性或者詞源的,應該放在釋義正文中。

内存溢出的猫
23
新年快乐!
首先是 gangjong,匹配没用正则,而是模块解析,只用了藏文数字那部分,现在应该没问题了
gangjong_v3.mdx (5.2 MB)
处理脚本在 这里。
需要转成 GoldenDict 专有格式吗?
另外 gomde 发现:
- 一些条目名带引号的条目;
- 第一个
<span> 前没有内容的条目;
- 整个
<p> 无 <span> 的条目
-
class 不是 གཞུང་སྤྱི།_ཚིག་མཛོད་ཀྱི་གཞུང་དངོས།,是否可以直接舍弃
应如何处理?
man
24
新年快樂,您辛苦了。
Gangjong v3仍有幾個問題:
- 詞條名尾的
། 或 ་ 或 ་།等能否去掉?
- 用22樓的正則式一找,很多多義項詞條沒有收錄,如
ཀུན་རྫོབ་ཤེས་པ,གསང་ཆ等。
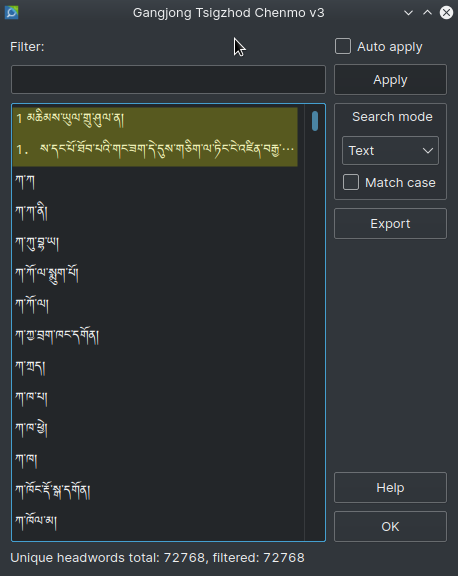
- 收錄的多義項詞條很多只有第一個義項,如
ཀུན་གཞི,གསང་བའི་བདག་པོ等:
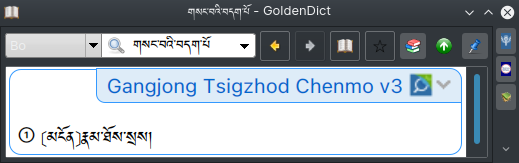

- 一些多餘的詞條,這些其實都是文中某一條釋義的一部分,特別是
ནད་རིགས་སྤྱིའི་དབྱེ་བ།這條,子義項中又有子義項,好幾層,特長。གནས་ཀྱི་སྒོ་ནས་དབྱེ་ན།和(ག)གནས་ཀྱི་སྒོ་ནས་དབྱེ་ན།都是這個詞條中釋義的一部分,卻多截出來了自己作一詞條,下圖是明顯能看出來的幾個,但像གནས་ཀྱི་སྒོ་ནས་དབྱེ་ན།就一眼看不出來:
- 30個字母本身沒有收錄。
-
གསང་སྔགས་བླ་མེད་རྒྱུད་གསུང་ཚུལ的詞條有問題,正文重複且不完整,子義項丟失了原文本的換行。
- 能否不要將詞條名從正文中刪除,保留在開頭,正文中的詞條名可以不用去掉།和་།,這樣有利於全文搜索。
- 有時候似乎是以།或་།來斷詞條名的,但有的詞條名是以ག結尾的,如
ནད་འབུ་འགོག་བྱེད་ལས་ཆོག ,收錄的詞條名是 ནད་འབུ་འགོག་བྱེད་ལས་ཆོག གློག་ཀླད་འཕྲུལ་འཁོར་ནང་གི་དངོས་པོ་དང་བྱ་བ་སྟོན་པའི་ཆེད་སྤྱོད་ཐ་སྙད་ཅིག་སྟེ།,可能還有別的情況,用第一個空格不行嗎?
Gomde
- 四本我都沒有去掉正文之外的文本,圖中帶引號的是第一本的前言。
-
- 2, 3沒有例子,您看是否同1?
-
གཞུང་སྤྱི།_ཚིག་མཛོད開頭的class應該都是詞條。不只是གཞུང་སྤྱི།_ཚིག་མཛོད་ཀྱི་གཞུང་དངོས།
mdict文件是goldendict能用的,所以不用別的格式也沒關係,謝謝您。jupyter文件看着挺亂,您能傳一份.py嗎?