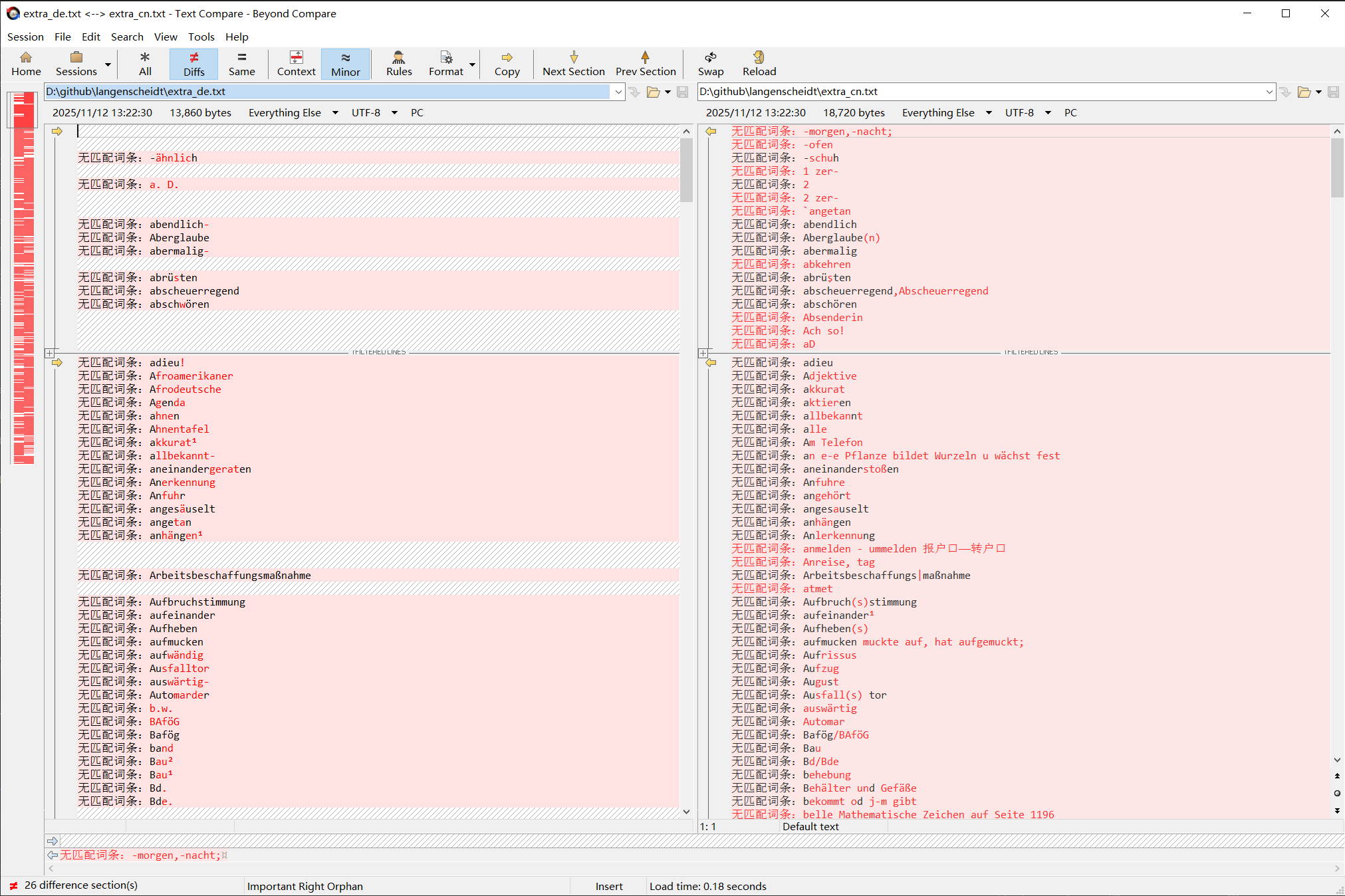
对比德文版自动修复了大部分词头问题,但是还有500多个词头匹配不上
然后切图程序改下参数就可以用了

这是目前匹配错误的词头列表,已经排除了一些明显不是词头的:
extra_cn.txt (18.3 KB)
extra_de.txt (13.5 KB)
对比德文版自动修复了大部分词头问题,但是还有500多个词头匹配不上
然后切图程序改下参数就可以用了
这是目前匹配错误的词头列表,已经排除了一些明显不是词头的:
extra_cn.txt (18.3 KB)
extra_de.txt (13.5 KB)
谢谢,辛苦了。不过对朗氏德汉双解的文字比对校订,我有点畏惧,觉得工作量很大,搞不动。
感觉等对齐词头后先把忽略德语对比中文,然后直接用工具插入德语原版里比较容易。但是德语感觉应该抽取固定格式,改成语义标签和css,这部分反而比较麻烦。
中文译本多事,翻译插入了很多可能不需要翻译的缩略语,像[口],K-(复合),Vi(不及物),它们实际对阅读的流畅度来说是造成干扰的,支离破碎,令人不忍卒读。这种破碎性也干扰了OCR的正确率和后续程序的有效处理。
补充paddleocr识别版本:
langenscheidt_paddleocr.7z (8.4 MB)
楼主好,我根据你的txt文本生成了mdx和mdd文件,现在排版还有些问题。不知道你有没有经验。现在虽然还有些错误,感觉基本可以用了。
把mdx和mdd发出来呗
(帖子已被作者删除)
现在问题还比较多,文本没有校对过,只是初步的一个