Langenscheidt are dictionaries for language learners - in all languages. They provide simple explanations, sometimes with illustrations. But they do not provide in-depth knowledge - for beginners and intermediate levels they are not necessary. Try Duden.
Yes, but there is simply no such way, at least as far as I know. I suggested a solution - to use the already converted German-Chinese dictionaries of Langenscheidt or Duden.
找 10 个人提取中文手工插到 HTML 底本里就行了,和韦氏高阶双解的制作过程一模一样,现在 ai 可以介入应该更轻松一些。
不需要这样,可以换个思路直接用中文版本,然后忽略中文对比两版差异,无条件应用德文文本就可以。或者两版都做文本解析,然后在语法树上直接操作。
你这个设想不错,忽略中文对比两个版本的德文,然后直接用官方德文文本把OCR出来的德文给覆盖替换了,但细节还需要进一步研究、实验。
感觉这样复杂了,找一个德语群,直接从里面拉学生就行了。已经有两波人做过这个双解文本了,第一本是付费的,第二本就是不想付费的人拉小群做的。
You can get the comparison text in both languages from here (at least there will be no errors in recognition and automatic text splitting due to line breaks); it also has the latest version of the new German spelling from 2018 (copy/paste will be easier).
Good luck!
搞过两波了, 质量如何,怎么没见词典流传发布出来?这些人可真够可以的,独家之秘,传家之宝,切勿外泄。
和韦氏高阶一样,只有参与的人才能分享,只是一个拿出来卖了,一个没有。
拉鲁斯在等 wynick27 兄根据清晰版图像制作新的image_pos.json词条坐标数据,旧版本,.这些符号肉眼都看不清,没法校对,而如果用全页图像比照,速度太慢。我自己也可以搞这个json数据,但相关代码是他写的,我没他熟练,就不越俎代庖了,碰巧的是,十一期间 nick 正在外面旅行,身边没电脑,那就只能缓一缓。
1 个赞
用百度的 ERNIE-4.5-VL-28B-A3B 又识别提取了一遍《德汉小词典》,该模型指令服从能力差,输出文本格式混乱,千奇百怪,但就文字本身的准确度论,还是很不错的,可以与Gemini的OCR结果对比校对来纠错。比较软件建议使用Beyond Compare。
德汉小词典 - ERNIE.txt (2.3 MB)
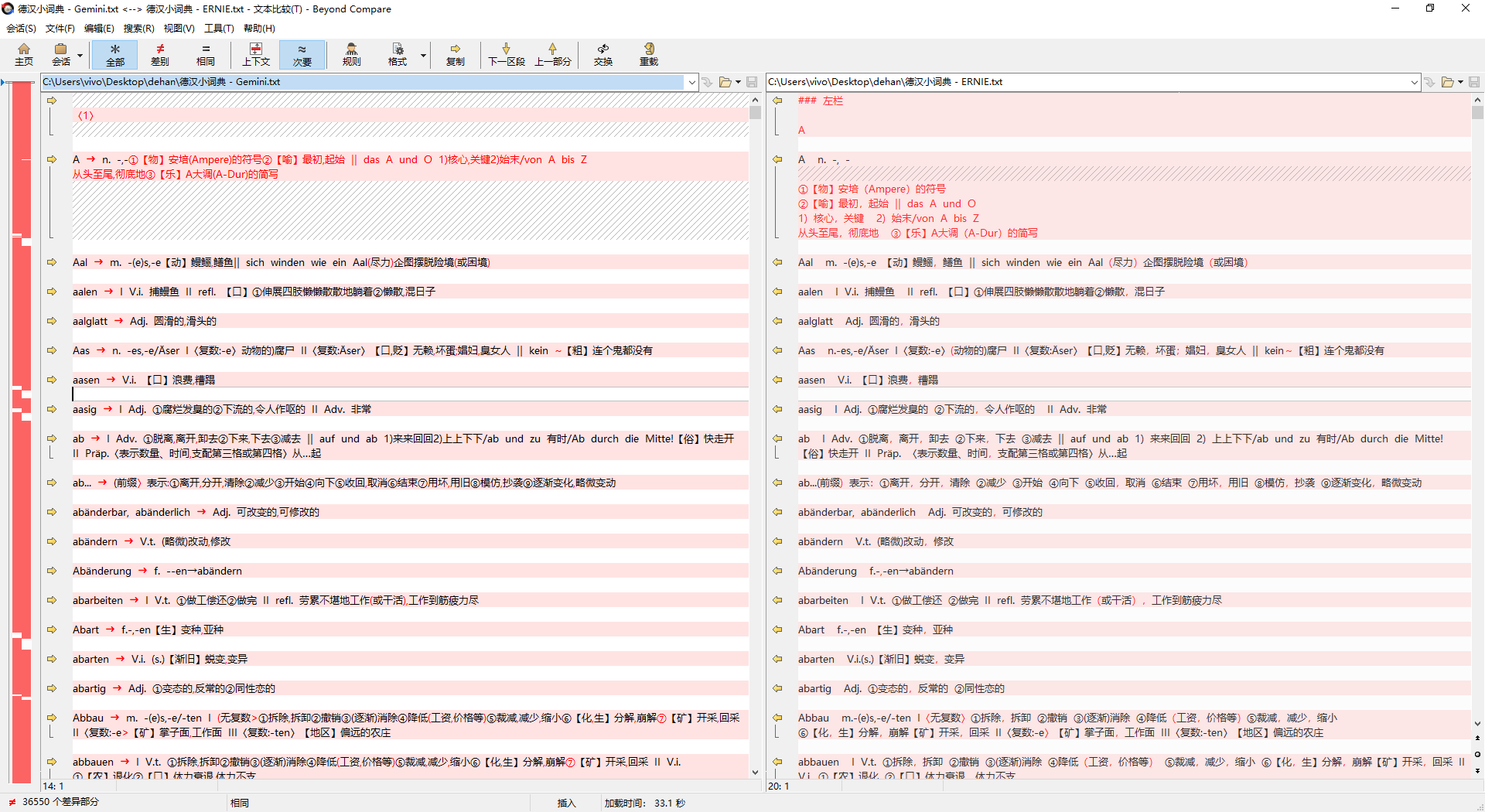
我已经把《朗氏德汉双解大词典》用 Gemini OCR了一遍。识别出来的文本尚未整理校对,或有各种错漏,上传到这里供参考,请谨慎使用。
文件见主帖更新。
用合合也OCR了一遍,跟Gemini的数据粗略对比,感到这批文本的识别质量挺高,中德文文字本身讹误很少,主要毛病集中在标点和一些特殊符号上。
朗氏词典不打算细校了,干这个太耗费精力和时间,不过也创建了一个github repo ( GitHub - mahavivo/langenscheidt: 朗氏德汉双解大词典 ),主要批量修正某些明显的问题。

1 个赞
这个是根据2010版还是2023版识别的啊
用的是2010年的灰度图像版,2023年双色版解析度比较低,二者文字应该一样,没更改。
清晰度足够,朗氏词典里的文字、符号 Gemini 没有不认识的,它产生的错误,主要可能归咎于 LLM 内在的随机性。这种情况下,多次用同一 Gemini 模型识别,然后互校,也是一个不错的办法。
我把用合合识别的结果也贴在这里,它格式混乱,不处理,直接对比文本困难。但可以挑选一定量的文本互相比较,看看ocr的错误率怎么样。
朗氏德汉双解大词典 - TextIn.txt (12.2 MB)
Duden Bibliothek能分享下吗?实在找不到3.0和5.2版本的词典数据库,以前网上的链接早就失效了。
我这里是3.0版,体积比较大,5g,怎么传给你?
用任何你习惯的方式
用 gofile 上传了,因为无法保证长期有效,就不公开分享了,私信发给你地址。