上周一直在折腾欧路的词典配置,作为一个 Vibe Coding 的爱好者,主要用的是命令行的 mdict-tuils 工具
使用的过程中,发现这个项目实在是有点年久失修了,顺手优化了一个更现代化的版本,供有需要的朋友使用
Github:GitHub - libukai/mdtt
Pypi:mdtt · PyPI
公众号:李不凯正在研究
MDTT - MDx Dict Trans ToolKit
一个现代化的 Python 3.13+ 工具,用于打包和解包 MDict 词典文件 (.mdx/.mdd),具有高级功能和直观的命令行界面。
核心特性
 完整 MDict 支持:读写 MDict 2.0,读取 MDict 3.0,支持加密词典
完整 MDict 支持:读写 MDict 2.0,读取 MDict 3.0,支持加密词典- 多种输出格式:MDX/MDD 文件、SQLite 数据库、纯文本、分割文件
- 智能命令行界面:具有上下文感知的命令,提供全面的帮助和错误处理
- 元数据系统:自动 .meta.toml 文件检测和生成
- 高级提取功能:按字母分割、自定义块大小、元数据导出
- 开发者友好:现代 Python 3.13+,uv 包管理器,全面类型提示
指令列表
| 命令 |
用途 |
核心特性 |
选项 |
| extract |
提取 MDX/MDD 文件并导出元数据 |
自动元数据导出、分割选项、数据库输出 |
-o (输出目录), --db, --no-meta, --split-az, --split-n |
| pack |
从源文件创建 MDX/MDD(智能输出命名) |
自动检测输出文件名、元数据文件发现 |
-a (添加源文件), -m (元数据文件), 多源文件 |
| query |
搜索单词并智能输出 HTML 文件 |
安全文件名生成、自定义输出路径 |
-o (输出文件), --passcode, 自动 HTML 创建 |
| info |
显示丰富的词典信息 |
美观格式化、多种导出格式 |
–format (text/json/toml), 全面元数据 |
| keys |
列出和过滤词典键值 |
模式匹配、分页、采样 |
–limit, --pattern, 内存高效流式处理 |
| convert |
格式间转换 |
文本 ↔ 数据库转换、保留结构 |
txt-to-db, db-to-txt, 维护索引 |
致谢
本项目基于 Yugang LIU 的原始项目 mdict-utils 构建并进行了重大演进。
虽然 MDTT 已经在现代架构、新功能和增强功能方面进行了广泛重写,但我们感谢原始项目提供的基础工作。
MDTT 的主要差异:
- 使用现代 Python 3.13+ 和子命令架构进行完全重写
- 基于 TOML 的元数据管理系统
- 具有全面帮助的增强 CLI 界面
- 包含真实词典文件测试的广泛测试套件
- 新功能:TBX 转换、智能查询系统、格式转换工具
如果你正在从原 mdict-utils v1.x 升级:
- 更新命令语法为使用子命令
- 替换 -t/-d 标志为 .meta.toml 文件
- 使用 mdtt info 而不是 mdtt -m
- 受益于改进的帮助、错误消息和输出格式
参考资料
amob
2
必须3.13以上版本,用到什么最新特性了?我还在用旧版,没法安装。
你让claude基于mdict-utils和mdict-analysis改写的项目,有必要限制版本吗,ai一般没有python的最新版本知识库。mdict-utils和mdict-analysis都是老项目了。没必要让提示词和ai控制所有代码吧。
这是要加入mdtt的功能吗?不检查一下ai写的文档吗?都不调用mdtt库了,反而在用你test文件夹里的文件。
amob
4
本来python3都能用的东西,没必要让涵盖用户变窄,更新python要做配置和库迁移工作的,一般人不会经常更新python的。版本限制不过是源于你给AI的prompt里的一句话。
The project is built using modern Python 3.13+ with uv as the package manager and build backend.
那就别管我说的吧,不麻烦您了。
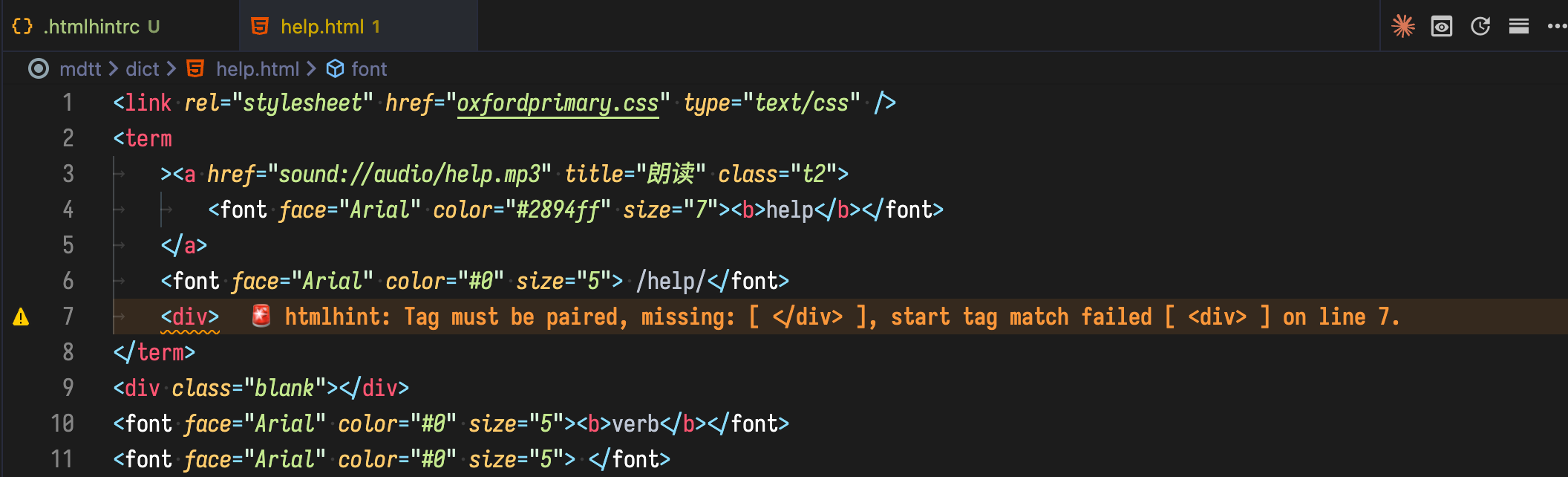
提些建议:一个更好用的打包工具应该可以帮助作者检查 HTML 标签缺失和错位,因为很多人用的正则替换的标签;压缩 HTML 文件,合并连续空白和注释;检查各类锚点图片音频链接是否完整;检查可能的 @LINK 指向错误和循环跳转问题。
这个工具只是用来打包和解包的,具体的文件修改我都是用 VS Code 打开 TXT 来手动处理,1G 以上的文件处理也很快
欢迎反馈问题,暂时纯满足自己需求,后面可以增加功能
可以加上让老版本python用户试用的方式
pip install uv
uv venv --python 3.13
. .venv/Scripts/activate.fish # 我用的是fish shell
python --version # 确认版本正确再继续
uv pip install mdtt # 直接用pip不成功,需要用uv pip
mdtt -h # 验证安装
处理大型文本的时候,这种错误非常常见。
尤其是词典,凡是自己动手处理过的就会知道,总是有各种各样的例外。这时候使用正则全部替换,就会有风险。
这也是为什么我认为,要设计一种类SQL/JSON之类的数据结构去涵盖各类词典基本上不太可能。因为就算是一部大书内部,都可能有各种例外。
检查 HTML 标签缺失和错位,其实挺难的,尤其是各种嵌套中的嵌套的时候。使用过L兄提供的检查结果报错清单,我发现:两个相邻的closing tags顺序颠倒可能会产生N个报错信息,这个时候无论是程序还是肉眼都不好判断该问题所在。
如果可以用 JSON 的话,用 JSON Schema 做验证就好了,如果是检查 HTML 格式的话,可以用 HTMLHint 试试,我的处理方式是直接提取一个 query,手动做检查基本上就 OK 了
我是认为新格式覆盖常用词典就可以了,SQL/JSON 都可以,混合 HTML + 特殊标记也行,结构化的词典数据有很多玩法可以开发,本来就是从零开始能把常用词典做维护好就不错了,如果和 mdx 没有区分度,用户为什么要迁移到你的新格式上。这个想法开始就没有考虑论坛里的词典大户,因为他们迁移成本太高,很多作者都找不到了,不太可能放弃 mdx。
检查 HTML 标签缺失如果是在正则批量替换前后执行,帮助会很大。如果文本替换很多次,那基本没救了,错误数量少的话还行。
正则批量替换的时候都不知道哪些页面会出问题,打包工具的前置检查很有必要。
专门写了一个 uv 使用介绍,可以快速搭建 python 环境,可以看看有没有帮助
一个 uv 打遍天下:最便捷的 Python 开发环境管理工具
amob
19
楼主不想弄,我自己来吧。我发布了mdtta,去除了python版本限制。all credits to mdtt。
在我的旧版python上一切运作正常。
pip install mdtta
希望能对想用的人有帮助,主要是给没有新版python的省点事情。