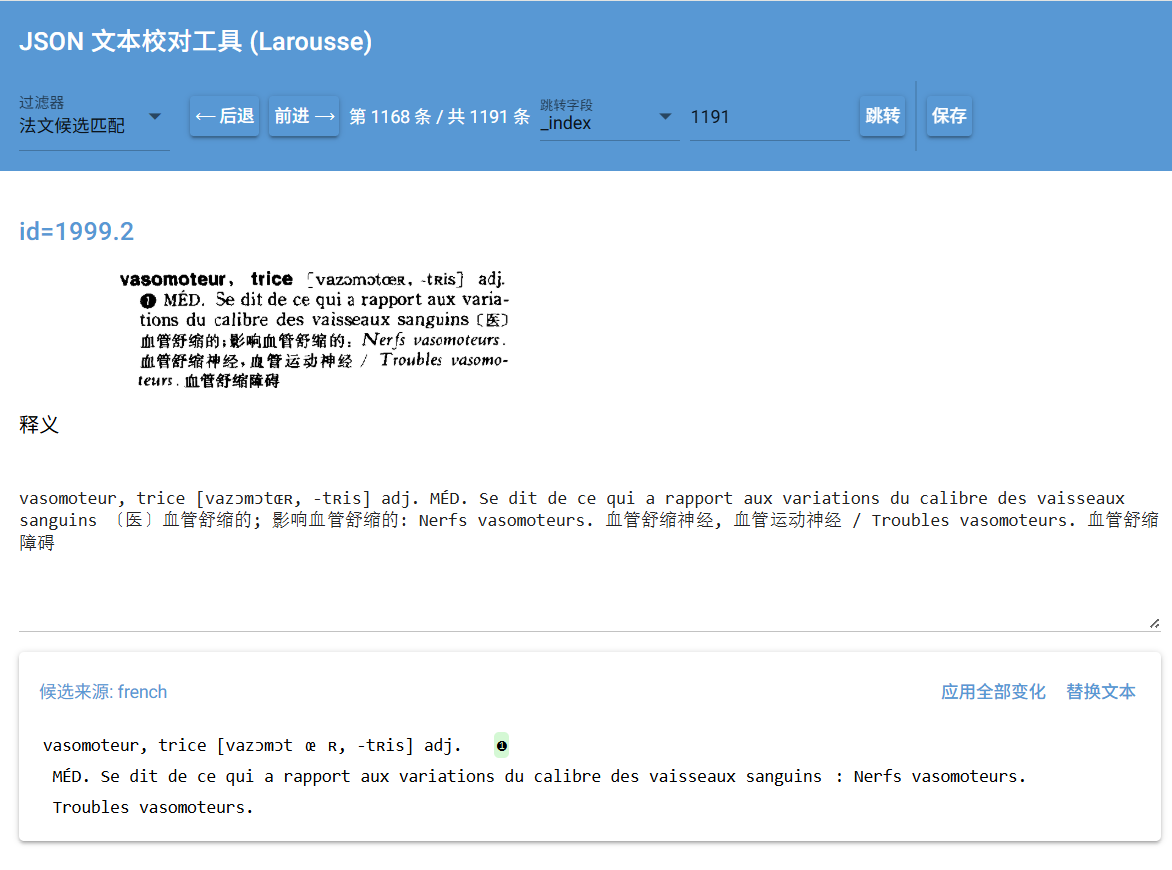
校对工具大更新,支持候选文本用不同的key查找,支持过滤字符比较,可以对比中文和法文,应用变化和替换文本分开。上方可以自定义各种字段跳转(比如拉鲁斯可以跳转到指定页page,指定页指定条目id,指定条目_index和指定单词headword。
3 个赞
相应的切图图片在github上吗?
图片是运行时切的,只保留了位置信息在data/image_pos.json,需要把pdf文件放到data目录才能用,pdf我一会传一下
1 个赞
pdf文件下载地址:
拉鲁斯法汉双解词典.pdf
链接: https://pan.baidu.com/s/1Ep0g5pFspXZJC0I0IUekgQ?pwd=3xwm 提取码: 3xwm
1 个赞
建议单独开一贴,供大家关注和讨论
不然就淹没在回帖中了
这个工具还没有通用化,有很多功能没实现,等实现差不多了我再单独开个帖吧。
1 个赞
初步通过与法文版文本程序对比的办法校核了本词典的法文部分文字,错误相对比较少,很多是变音符号丢失的问题。
至此,词典的中法文文字都对比校对过一遍,少不了漏网之鱼,但错误率应该相当低了。
在文本比对的过程中,发现了不少中法文词典本身的错误,一般会顺手纠正,不过如果问题棘手,难以一时考定,则照录双解版纸本书,以之为准。
主要的大山已经翻过了,剩下的毛病主要集中在音标和中法文的标点符号上,应该比较容易处理。
2 个赞
用Gemini从法文图像版里第二次单独提取了一遍音标数据,质量似乎稍微强了一些。用的prompt如下:
请OCR识别pdf文件,从中提取这个法文词典当中的词头(headword)和它的音标,其他数据不需要,全部删除抛弃。
音标数据在黑体字词头后的方括号"[]"内,且在v.t. 、n.m.、adj.这些词性标记之前。
识别时须特别留意音标的正确表示。本词典使用了如下所列的音标符号,不可使用这个列表以外的其他字符,否则就是错误;原书图像不清晰,音标中看似ā的符号,实际应该是ɑ̃。
音标符号列表:
consonnes 辅音([p][t][k][b][d][g][f][v][s][z][ʃ][ʒ][l][ʀ][m][n][ɲ][x][ŋ]);voyelles orales 口腔元音([i][e][ɛ][a][ɑ][ɔ][o][u][y][œ][ø][ə]);voyelles nasales 鼻腔元音([ɛ̃][œ̃][ɑ̃][ɔ̃]);semi-voyelles ou semi-consonnes 半元音或半辅音([j][ɥ][w])
提取的文件形式当如下,按照词典阅读顺序先后排列:
drôlement [dʀolmɑ̃]
dromadaire [dʀɔmadɛʀ]
druide [dʀɥid]
du [dy]
1. dû [dy]
2. dû, due [dy]
remaillage [ʀəmajaʒ] ou remmaillage [ʀɑ̃majaʒ]
每一个pdf文件有25页,需要全部识别,不要没完成任务就半途中断。
法文版音标第二次提取.txt (857.3 KB)
1 个赞
上面提取的音标文件和正在编辑的json文件差异过大,艰于直接比较利用。于是我再次从json文件里提取相关音标文字,用它们在beyond compare进行了比较,目前有2500个左右的差异。这些差异并不是说正在编校的json文件必然是错的,而是表明其可能有讹误,需要查核原始图像进一步确认。
我把比较结果的报告贴在这里:
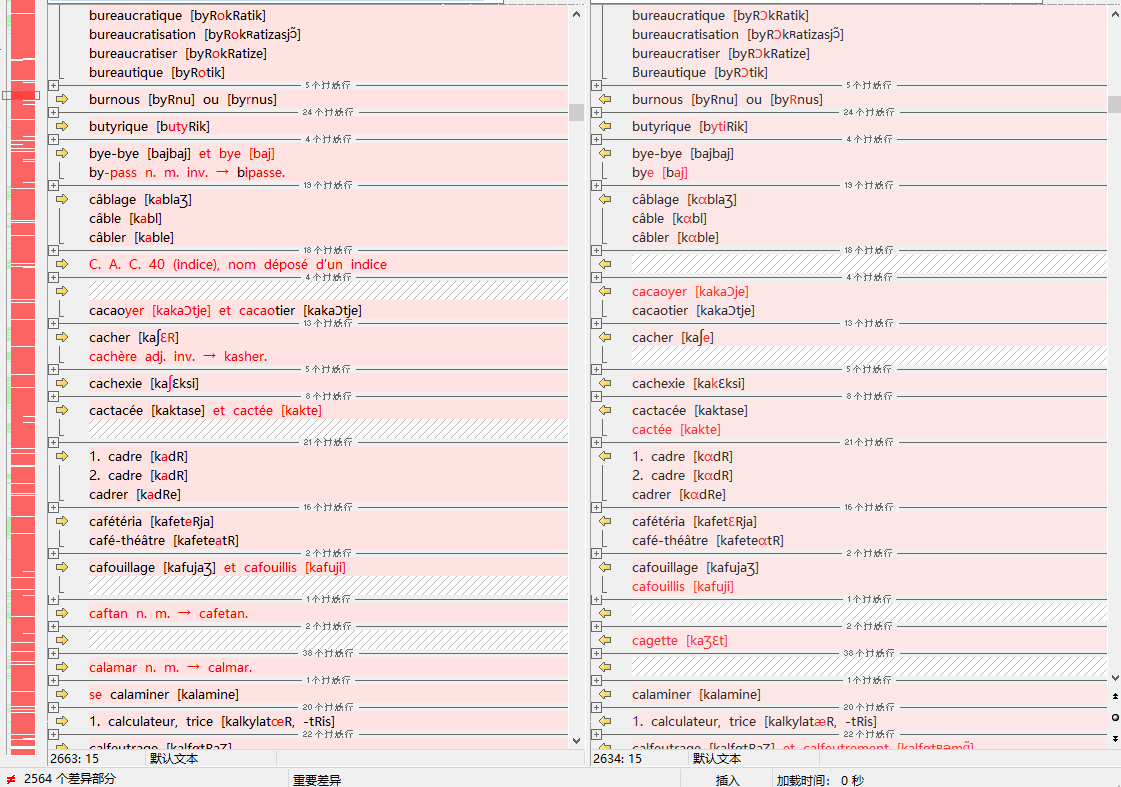
音标比较差异报告(beyond compare).zip (94.6 KB)
感觉这两个版本都有不少错误,我还发现之前有ʃ识别成积分符号∫的,还有个别字母识别成西里尔字母的,这种直接看很难看出来。
我稍微调查了一下,目前网上应该不存在可靠的法文单词音标数据,就连拉鲁斯自己的官方网站,音标都错漏百出,最终只能回到1995年版的法文词典pdf上。人工一个个单词校对,我个人是不可能去做了,退而求其次想各种办法降低错误率。
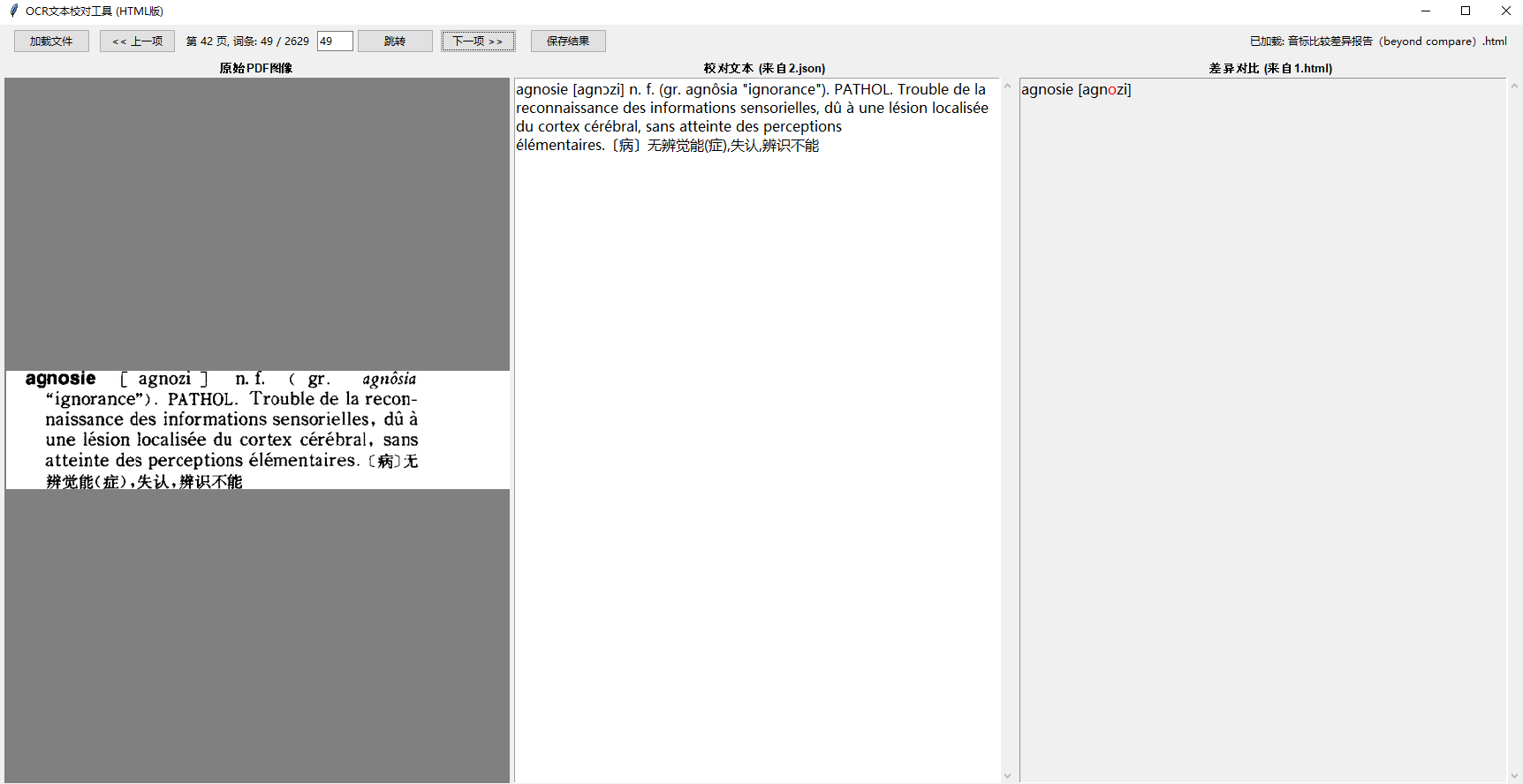
比较json、html差异报告和图像pdf,去改2500个单词的音标,工作量也不小。我打算vibe coding再写一个专门的程序,把有差异的单词、差异报告,和该单词的图像同步放在一个界面,对比它们然后修改json文件,希望磨刀不误砍柴功。
我现在写的校对工具已经支持这种了,把差异的文件新建一个json,headword填词头,然后音标填text,然后建一个候选来源和一个过滤器就能比较了。
你的程序逻辑有点复杂,我感到不容易弄明白设置和使用办法,我用自己的程序改,会更顺手方便些,反正现在是vibe coding,也不在乎代码大动干戈、伤筋动骨了。
ai写这种小型一次性程序很不错,不过维护大一点的项目感觉就不太行了,各种乱改,不过我也没用过贵的模型,不知道怎么样。
我个人完全不了解法语,单纯请教一下,ipa-dict的法语音标数据也是不可靠的吗?github上似乎并没有对法语音标可靠性的有效批评。
1 个赞
谢谢告知这个音标数据源,我稍微搜过都没找到。看了一下法文音标,质量好像还可以,但跟词典图像对比过之后,发现不少地方并不一致,比如 abaisser ,词典标为[abese],这个数据库则是 abaisser /abɛse/。或许法文发音同样有不少流变、方言等,不同人认可的正确语音并不一样,没有一个强制性的统一标准,像法兰西学院词典、Petit Larousse、 Dictionnaires Le Robert,都是不标注读音的,我这里在文本化《拉鲁斯法汉双解词典》,注音有分歧也只能以它作为标准参考了,而不能采用 ipa-dict 的音标数据。
不过这些已经不大重要,经过多轮替换,校订,目前词典音标数据的质量已有大幅度的提高,进一步打磨修正参照比对原书图像即可,工作量不会太大。
不同的语言学家对同一音位的理解有分歧是很常见的。ipa-dict是专业语音学家制作的学术基础设施,音位分析的水平是要比绝大多数词典高的。如果ipa-dict和《拉鲁斯》有差异,那大概率是《拉鲁斯》的记音法做了不严谨的变通,或者纪录了常见但不标准的口音。(当然,这谈不上对错)
使用原词典的音标数据是绝对正确的,音标也是词典的重要组成部分,使用任何其他数据源来代替都是对词典的窜改。ipa-dict的数据只能作为一个校对音标时的参考。
或许可以通过分析词典和数据库的音位系统,排除记音法的差异后,再用ipa-dict的数据来核校《拉鲁斯》的音标。不过现在再说这种方法好像已经是马后炮了,AI都快把人类的活干完了。![]()
现在应该先优化一下提示词:
- 用XML标签对提示词的内容结构进行划分和定义,让提示词在形式上达到绝对清晰。
- 告诉AI应该做哪些事,而不是不应该做哪些事:在提示词中告知不要AI输出某些内容,反而可能会提高这类输出的权重。这就如同告诉一个人“不要在脑中想象一头粉色的大象”
- 提示词使用第一人称:第三人称提示词下的AI是努力理解提示词,被动遵循用户指令的助手。而第一人称的提示词会让AI内化指令,以相对主动的方式来执行指令。(不能设置系统提示词也没有关系,可以用
<system_prompt>标签来假装这是系统提示词)
实际即使在拉鲁斯自己的系统内,就我所见,官网、1995年法文版、双解版的音标有时也存在微妙的差异,这种神仙打架,一时难以裁定,为了省事,我个人通常会尊重底本,以双解版的原始图像为依据来处理,除非说它明确错了,才会予以修正更改。
我当下的目标定位是OCR、文本化《拉鲁斯法汉双解词典》。至于对词典本身全面编辑、校正,那学问可大了,自忖没这个能力也没这个时间,我曾经随机抽了一页词典文本让顶流 ai 挑刺查错,洋洋洒洒一大堆,说至少三五个“严重错误”,从古希腊语、原始日耳曼语讲到北非文化、普罗旺斯民俗,真真假假,煞有其事,要搞清楚明确得做大量的学术调查和研究。
可能是我没表达清楚,我的意思是:通过对比ipa-dict的音标数据和《拉鲁斯》ocr文本的一致性,来检查《拉鲁斯》的音标文本是否存在ocr错误。两者毕竟都是用IPA对标准法语发音的纪录,排除对音位理解的不同后,差异应是极小的。但既然gemini输出的音标质量已经达到了你的要求,这就有点多此一举了
原书本身存在的问题根本不需要去管。我认为其实就连已发现的原书确实存在的错误也没有必要去修改,最多加一条校记即可。因为只是几处错误的修正在整部词典的体量面前实在是于事无补,而这却破坏了电子化文本与底本的一致性,给涉及词典版本的严谨研究造成不必要的麻烦。
给词典做修订不是电子词典制作者该做的工作。工作量太大,总会有失误的时候;而且没有同行评审,谁也不知道改的对不对。这种涉及到词典编纂和语言学的事情还是得交给专家来做。
现在的AI确实有能力辅助学者进行学术研究,但捏造事实的能力也是相当恐怖的,除非你是相关领域的专家,否则基本无法辨别内容的真实性。如果使用AI来做学术研究,使用者的学术水平至少得和AI同级,并且有方法能验证AI输出的内容。
2 个赞