excel表格数据,另有csv和json格式,它们比较大,一般人也用不着。
资料来自 www.kaixims.jp 网站。
中國古籍總目.xlsx (7.7 MB)
中国古籍索引网好几个,有多家机构联合做的,压根用不到这日本人弄的玩意,就这还要付费,坑坑有信息差的日本人。
看了看这公司官网,老东西挺多,没多少稀罕东西
本地数据怎么和多家机构联合做的什么“中国古籍索引”比,除了在线查询,能用它做统计吗?www.kaixims.jp也不是日本人做的,而是强国人干的,败坏日本的名誉规避可能的版权问题。
研究人员也就用古籍目录收集不同版本对校差异,统计真的是很狭窄的目标人群。
我查不到这公司的背景,但卖的很多东西能看出来是搬中国公司弄的,不知道有没有授权。
(帖子已被作者删除)
具体我也不清楚,猜测无论日本的、昆山的凯希,都应该是中国人主持的,套了很多层皮布迷魂阵,套利,规避版权问题等。
guji cn 网大家都知道的,但我认为这些东西,就是浪费财政拨款做做样子。一个破书目网站,查询一下都要手机实名注册登录,这些人真是失心疯了。
是怕偷数据,注册登录能限制访问、限制爬虫、限制复制、限制接口。字体都用的中华书局宋体,背后的电子化工作多半是籍合网或者上海古籍出版社(上海世纪出版集团),中华书局的古籍数据保护多严格,你也应该知道的。这是一门生意,是出版社和公司的数字产权,不是全民共享的知识成果。古籍早就被私有化了,不是大家的,是少数人的。
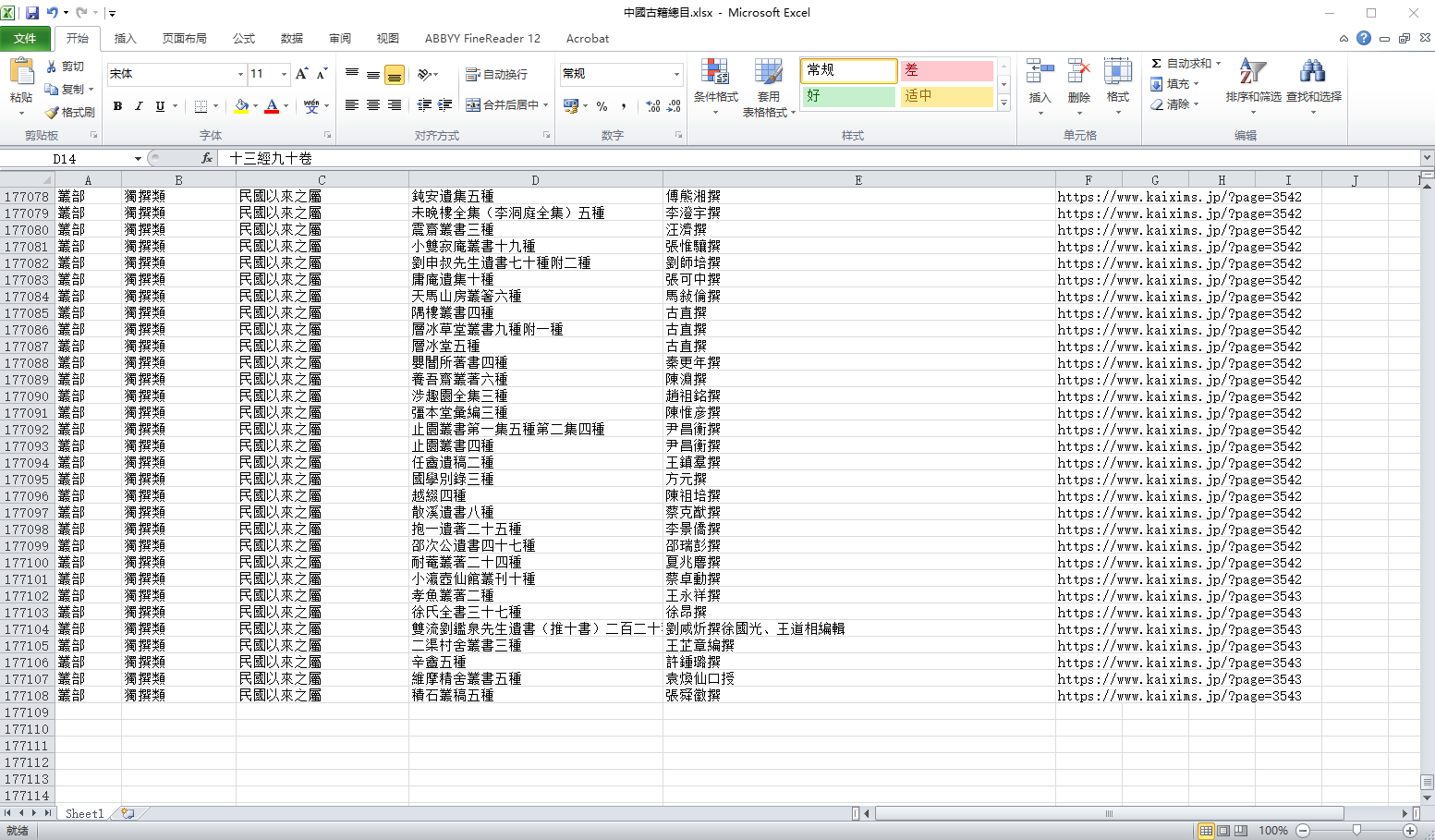
中国古籍总目二十几万条?我记得中国古籍是数量是在百万部这个数量级
古籍总目(二十六册)多少年前编的东西了,现在都用数字化平台。古籍整理一直都在进行的。
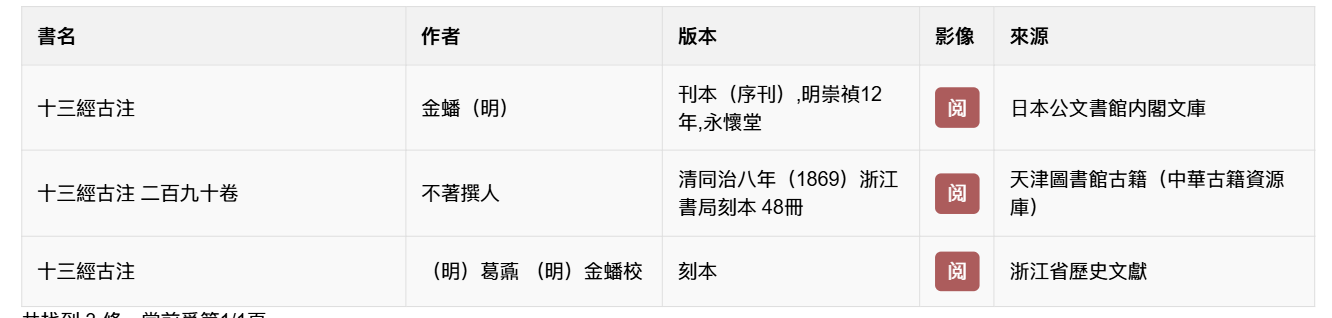
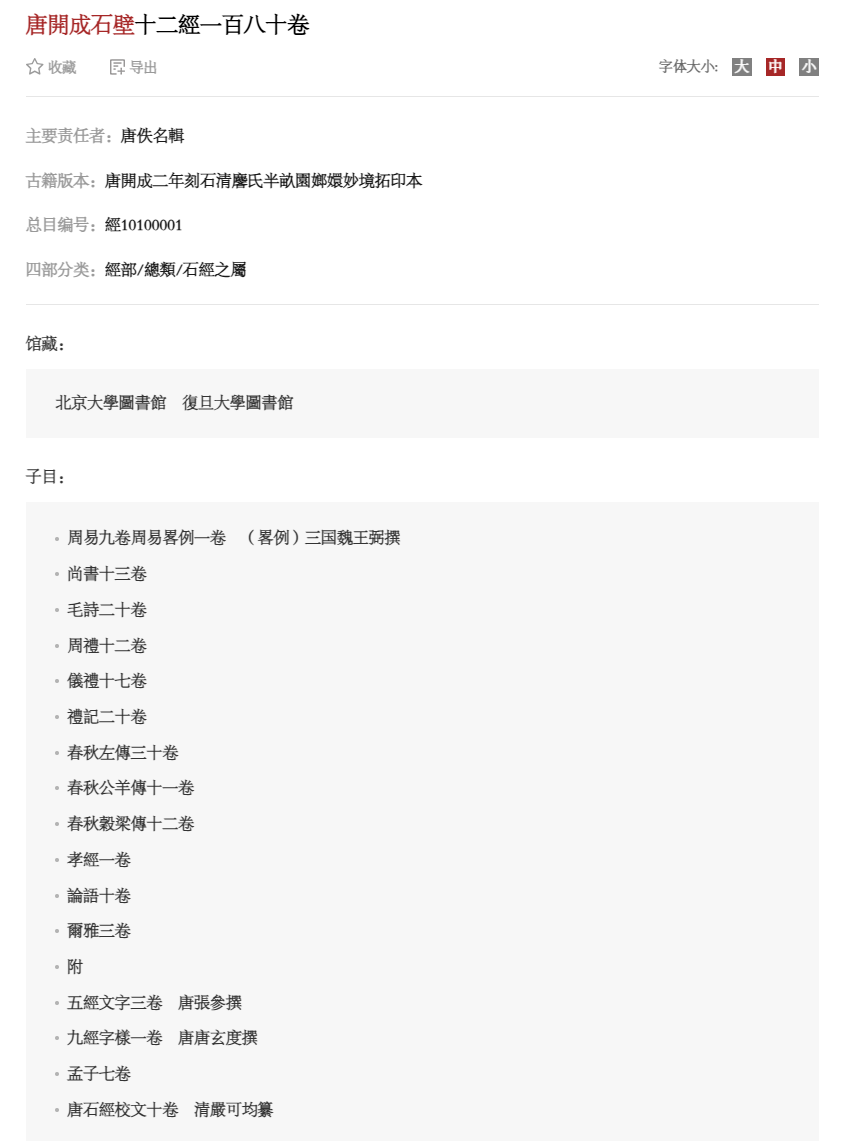
古籍的“种”、“版本”和“件”等是完全不同的概念。
二十万条是合并了相同的版本,同一版本会有多件原典流传,这个数据没有显示版本,所以几乎没什么用。
文本化的索引“几乎没什么用”,这在freemdict倒是很新鲜的想法,一竿子打倒了很多付出辛苦劳作的人。
重点是残缺数据没有用,他们很清楚最重要的信息是版本、子目、馆藏,所以才有人乐意付费。你拿着这个数据,输入古籍名称查询,是要拿来找作者的?
“版本、子目、馆藏”,难道不会用别的工具继续查?有了索引,在纸本pdf上定位都会容易很多。我就是做一个简单的搬运整合,没有想法或者义务把饭都喂到别人嘴里。
对于能做数据库的人来说,数据总是可能有用的。
例如,书名数据库可以用来校对书名,作者数据库可以用来校对作者的姓名。
例如,可以尝试用这个书名书目去套上《中国古籍总目》的ocr文本,书名套上符号(如【】),就可以用程式抽出来做书名页码索引。
我看到数据总是先收着。有些数据是收了十年后才想到方法用上的。用上后就觉得很有用。
這個公司就是做雕龍古籍庫的