我正在修改某個HYDZD的電子版,發現其中的 “扎” 條,缺乏第三、第四的讀音(zhǎ、zā)和解釋;
也發現 “用” 字條,有一堆別的內容亂湊進去了(在第20解釋之後)。
這個電子版有很多問題。有時,一條明明該分成兩條;有時,兩條亂幷成一條。
看來雖然內容都在,可是不少內容擺錯了,歸於錯的字條。
如果你的版本比我的更完整或整齊,請跟我分享。
我正在修改某個HYDZD的電子版,發現其中的 “扎” 條,缺乏第三、第四的讀音(zhǎ、zā)和解釋;
也發現 “用” 字條,有一堆別的內容亂湊進去了(在第20解釋之後)。
這個電子版有很多問題。有時,一條明明該分成兩條;有時,兩條亂幷成一條。
看來雖然內容都在,可是不少內容擺錯了,歸於錯的字條。
如果你的版本比我的更完整或整齊,請跟我分享。
至少把你手上那版本的基本情况说详细点吧。总共多少词条,有问题词条截图或者文本。
链接: https://pan.baidu.com/s/1DUfISJOFrXFTUunetMj-FA 提取码: xmmy
这个是隔壁分享的那个。
用正则处理的时候注意19780和83009行,不要又引入新的错误。
一共55433词条
謝謝分享。
看來,我的TXT基本上是一樣的。總共有166,300 lines.
有同樣的tag,有同樣不統一的釋義號碼:(1)-(10)之後就用:⑪、⑫ . . .
區別在我的版本是從MDX unpack出來的,所以次序是按照mdx builder的詞條排法。應當沒差,因為這個數據的毛病不來自詞條的次序。
我用一些search的模式,能夠確定有起碼一百多條,paragraph tag 裡面的釋義內容擺錯了,歸於別條。毛病各種各樣,有的,把某個釋義句子的第一個字當做headword,分成新的詞條;有的,應是兩條混成一條;有的,headword打錯了(用上另一個異體字),使得headword和內容不和。
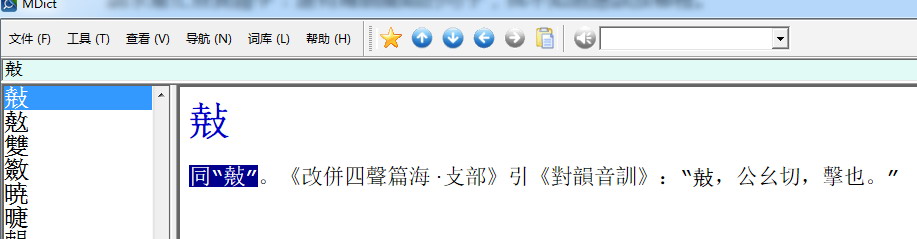
有的,我無法解釋他的原因,例如“扎”字條的第三、第四(zhǎ、zā)釋義組,居然擺在“用”字條後面。“扎”詞條和“用”詞條,內容在字面上沒有任何關係或是重疊的部分,所以我搞不懂這是怎麼回事。而且這兩條,在次序上又不接近。
我前面講得那些一百多毛病,出現在詞條前面,所以更明顯格格不入。可是有的擺錯的內容出現在詞條後面,這類就比較難找出來。
主要的問題在內容擺錯了。不成大事,因為我打算做個"綜合版":文字版,加上可以參考圖像板。光用文字版是不夠的。
完善 漢語大字典,功德無量!
擺錯的內容,我修改了大概150多字條。
還有不少字條漏掉了其中一個釋義,那行只有 ‘p’ tag, tag 中間是空的,例如“侯”字的第二個釋義。
這些內容只能親自打進去。
請求幫忙查異體字:還有幾個擺錯的句子,我不知道應該放哪裡。
例如:
�同“𢿣”。《改併四聲篇海·攴部》引《對韻音訓》:“𢿣,公幺切。擊也。”
這應當是完整的一條,本來不帶讀音的信息,只缺字頭。它指的異體字不是“𢿣”,也不是“𢿲”。需要先找出這字頭在印刷版(圖像板)出現在哪一頁,然後看該字是否有統一碼(Unicode.)
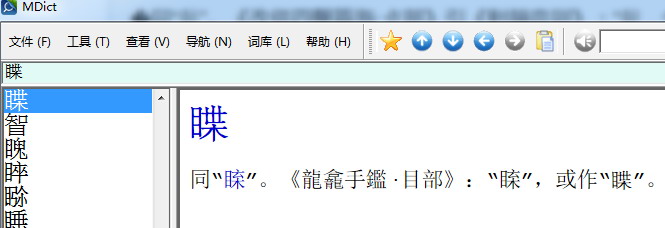
還有:
同“𥇱”。《龍龕手鑑·目部》:“𥇱”,或作“�”。
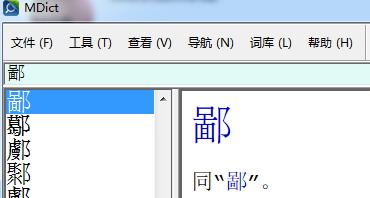
還有一行,只寫:
同“鄙”。
哈哈。我在圖像板查了一堆異體字,找不到。
還有一段:
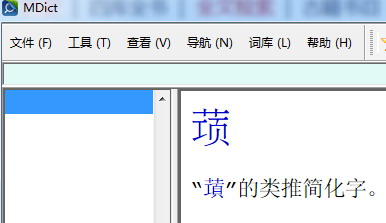
𠍳“𦺣”的类推简化字。
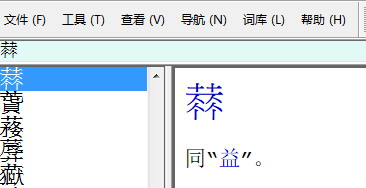
𠍳同“益”。
這裡的“𠍳”字一定是打錯了,可是字形也許接近。理論上,字頭是“𦺣”的簡化字( U+30C5D);可是跟“益”沒有關係,所以我很疑惑。也許這段原來是兩條。我在圖像板找不到“𦺣”的簡體字,也許卻是有,我只不過沒看到。
這個找到了。

可是好像沒有Unicode.
也許可以用 “⿰𠷰阝”來代表,但不完全準確。
这种大型词典,一个棘手的问题是生僻字的正确编码。
建议统一使用《辞源》文字版的那个方正字体
我用了 MS Word 的 Insert Symbol 界面,翻了一下 FZCiYuanSong 的字體:它支持的統一碼只包括 CJK Unified Ideographs Extension “A”-“B”。
“𦺣”字在 Extension B;他的簡化字( U+30C5D)在 Extension G!
我沒有任何字體能夠顯出來 Extension G.
謝謝找出來。麻煩你打出字來;我不知道如何打這些字,或是找出他的統一碼。
—看來,那是完整的HYDZD文字版。
可用“国学大师”网的拆分查字,还有“部件检索”(掌上百科论坛有下载),相互配合使用。没有一种输入法能直接全部打出这些字来!