前情提要:
真用上sqlite才发现为什么自研格式这么香了。用sqlite的话,大批量显示headline(查词的时候显示在左侧边栏的词头,或者说是(見出し))性能特别差。
现在转去自研格式了,正好有这个项目可以借鉴:GitHub - golddranks/monokakido: A Rust library for parsing and interpreting the Monokakido dictionary format. Full test coverage and efficient implementation with minimal dependencies.
今天刚搞懂他的.headlinestore怎么组织的,实现了读取。
非常精巧的格式:
- 文件头部包含魔数、记录数量和关键偏移量
- 固定大小的记录结构(0x18字节)
- 文本和数据的偏移量索引
怪不得一次显示几十万条都是毫秒级的…
5 个赞
@last_idol
at下大佬,你觉得自研二进制词典格式怎么样?
amob
3
不少词典格式,都这个结构的,一个索引表记录大小和偏移,固定大小分块压缩和读取。技术原理简单,所以啥公司都能写出来。优化大小和读取速度主要在于算法的选择。比如安卓app一般直接用c++写native库,java效率不行。没有算法和汇编基础用ai辅助编程的话,还是别折腾性能吧。
amob
4
比起索引的快速检索,一般人更能感知到词典内容的展现速度,goldendict众人共创的基于c++的项目,都有人嫌弃词典一多就显示太慢。真要极致的性能,肯定是直接舍弃html,杂七杂八组件太多,一般人都知道浏览器性能开销多大,有的人用electron展示html,性能天生落后人一截。但是html功能太强大,存储词典内容也方便,展示效果美观,谁会不用呢。
话是这么说的没错。
monokakido也没什么特别厉害的算法啊,就是二分查找page id item id。
我贴的那个github链接里的rust项目读取headline的部分是todo,所以逆向过了。
amob
9
headline解析别人早做完了吧。我以前没运行过,今天试了下可以用。
amob
10
一晃都两年了,都被弃坑了。stephenmk把jitenbot和monokakido都删库了,2024年问了这位他说没精力弄monokakido解析了。
你这是.keystore吧。.headlinestore没有前缀/长度/后缀索引。
amob
12
不太了解,你给的图不太明确,我也没看懂,那应该我理解错了。
铁定是.keystore,因为要先通过.keystore的索引获取pageid和itemid然后在.headlinestore找到这两个id对应的标题。
如果没有itemid,就返回整页,有itemid就跳到页面对应位置(估计是content.rsc里面封装的html有锚点。
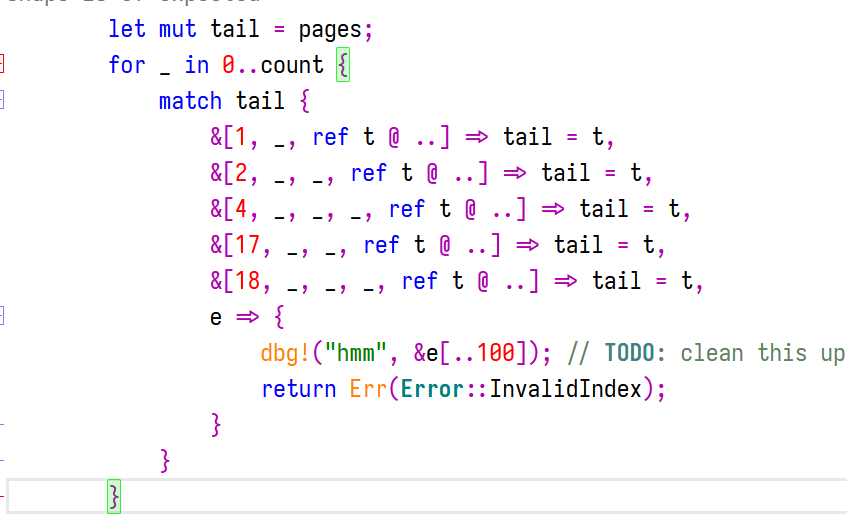
你看headline.rs里面那个todo:就是了,这个没写完。
amob
15
dbg!("hmm", &e[..100]); // TODO: clean this up
话说这个问题你解决了吗,有的keystore好像格式不一样?在 Planned to support 列表里的。
keystore怎么建索引的我还没研究透,这个我也不太清楚。不过不太像是有多种形式的keystore。今天晚上用hopperdissembler研究一下。
?我读取.headlinestore的.py就是靠逆向现在的app写出来的啊
加密了吗?不清楚。
切换了一下旧版app,确实有几部读不出来…
但是我读取headlinestore那个代码确实也是靠逆向新版app写出来。可能歪打正着了…
正文早在前年就已经加密了…至于词头和索引可以说格式变了也可以说没变。headlinestore和keystore也是统合APP后才新弄的格式(这其中可能有稍微修改过数据结构),其实还有更早的不是这两个扩展名的文件。索引文件估计加密可能性不大,物书堂连压缩都没做,为了就是快速查找词条秒出结果。当然正文加密也不是一点办法没有,起码还能用传统操作(比如按键精灵…
2 个赞