amob
1
网上到处找不到解除限制的现成脚本和教程,无奈,自己逆向了一下微信混淆后的js。
本来是想写油猴的,但是发现混淆的代码太复杂,不知道怎么hook进去。以下只能提供复杂的js替换方案,能总比不能来得强。
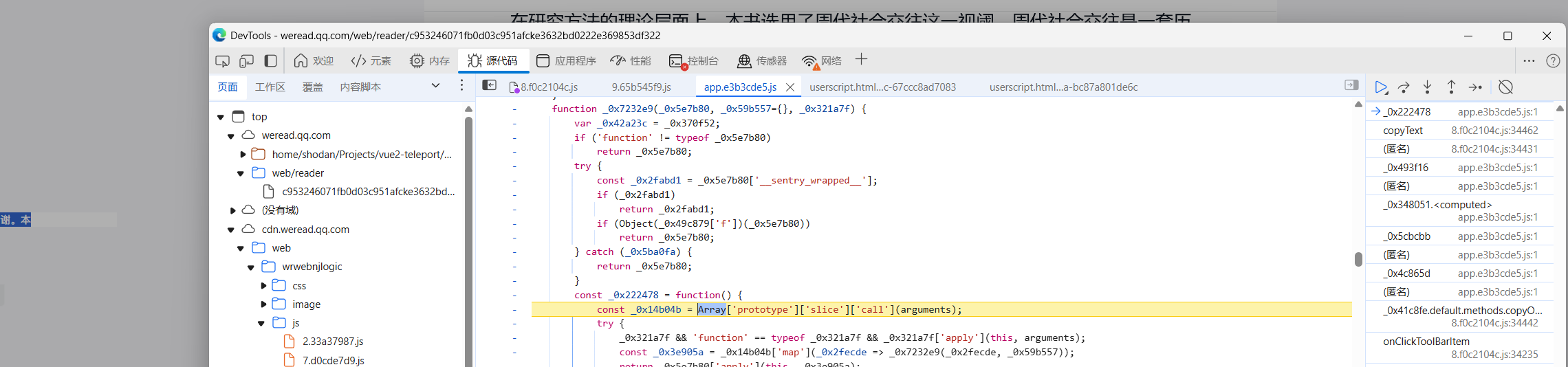
F12打开DevTools,进入“源代码”界面。
找到8.f0c2104c.js文件,右键替代内容。
随便选择一个喜欢的文件夹

允许完全访问权限

找到离线在本地的js文件,替换为我提供的。
8.f0c2104c.7z (2.9 MB)
成功,无限选中内容,方便复制。建议切换为上下滚动阅读进行复制。原始情况官方只让一次最多选中500字内容,还限制复制的频率,非常恶心人。
3 个赞
amob
3
今年要下载微信读书已经非常困难了,爬虫非常容易封号(具体可以看github项目的issues),是微信最近几个月的反制措施。
既然拿不到源文件缓存进行解密,确实可以考虑复制,但是这样复制没有保留分段和换行信息,其实效果不好。
我是个人需要大段大段复制内容。
原来不能使用Ctrl+C进行复制,建议结合以下油猴脚本食用:
在微信读书网页版中新增复制快捷键
关于weread的下载:
jooooock/wrx: 【暂停维护】电子书导出工具,支持大部分电子书网站,可导出 HTML/EPUB 格式
drunkdream/weread-exporter: 将微信读书中的书籍导出成epub、pdf、mobi等格式
分段和换行复制时是有的,被微信替换掉了。归根结底这种破解项目不应该开源,有心的话直接上传书籍就好了,开源会增加破解难度。
amob
5
远古时代,微信甚至零混淆。。。也没有什么canvas画布绘制文字。
微信读书PC版如何禁止复制文本_微信读书不能右键-CSDN博客
amob
6
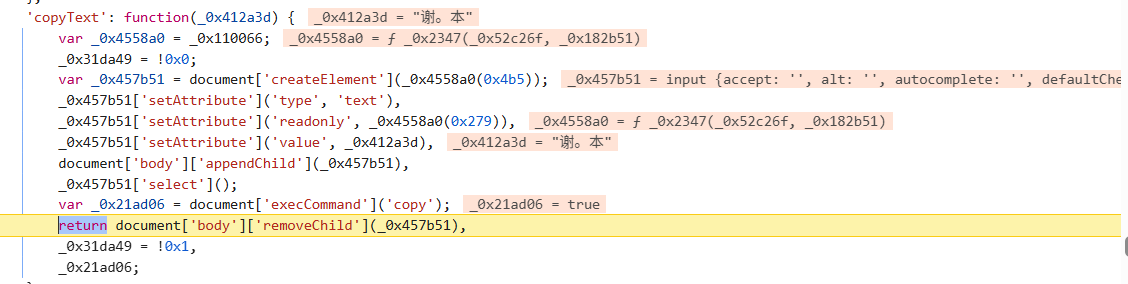
不是吧,只有使用<p>和<div>等block标签,浏览器才会自动在复制中加入换行符,是没有硬编码的换行符存在的。而微信是用canvas画布绘制,浏览器不知道它其实是由<p>标签包裹的(源代码完全看不到),我们是解密后知道其实都使用的<p>。
加入断点后可以看到隐藏在后方的文字被select了,是完全的纯文本。我将其他先行执行的校验函数直接跳过,微信并没有进行替换操作,传入剪切板的就是没有换行符的文字。
1 个赞
amob
8
我顺便说一下现在weread的复制原理,可能是preventdefault阻止了select默认行为(你添加select断点不会中断),通过js为这些文字添加了class,然后css显示高亮,然后你点击复制按钮就会直接传递此class包含的文字,然后进行复制长度和复制频率的校验,确认小于某个值然后才会告诉你复制成功。
1 个赞
amob
9
那个时候可能还不是canvas绘制,貌似是直接的明文,去年我看到jcz777直接复制了一整本weread的书,完全无阻碍。格式排版都是完整的,像是打开F12复制完整html的。
1 个赞
应该不是这本,23 年就没有完整 HTML 了,因为 23 年有人开源过破解源代码的项目,也有人通过复制文本 + 按键精灵获取书籍,所以我认为那个时候复制是有换行的。
1 个赞
amob
11
反正现在没人这么干了,复制完全报废。解密缓存方案也是今年刚看到,以前肯定不是缓存注入canvas的。
1 个赞
把 weread-exporter 转成油猴脚本,应该可以绕过爬虫识别,只会有频率限制,毕竟用的真实浏览器,指纹什么的全是正常的,而 weread-exporter 使用的 pyppeteer 很早就上黑名单了。
1 个赞
amob
14
上次看到canvas绘制网页,还是识典古籍,源html完全看不到文字内容,只好抓包看到json传递的chapter明文,都是有校验参数的post请求。canvas用来防轻松的爬虫确实是好主意。直接selenium和get下网页完全行不通,必须得逆向post请求中的参数如何获取。抖音和北大还是仁慈了,如果再给json来个服务器加密,本地解密用wasm,谁还不老实了。
1 个赞
amob
15
有兴趣,但没这个技术,不是我熟悉的开发环境,需要花的时间太多。
amob
17
识典古籍,简单的页面解析json文件就行了,但有一部分,需要无头浏览器模拟访问,我不久前都写过小爬虫,测试成功。不过它的数据一直在改进完善当中,当前批量下载到本地也没啥太大意义,对个别书特别感兴趣,想个人进一步研究和改进倒是可以把文本扒下来。
博主,请问下现在这个解除复制限制的脚本不能用了吗?我试了下不行。