在词典–程序添加了以下命令行搜索命令
rga %GDWORD% "E:\00000\Search\TLP-3-columns.txt"
因为内容是德语,输出结果中一些德语字符出现乱码。
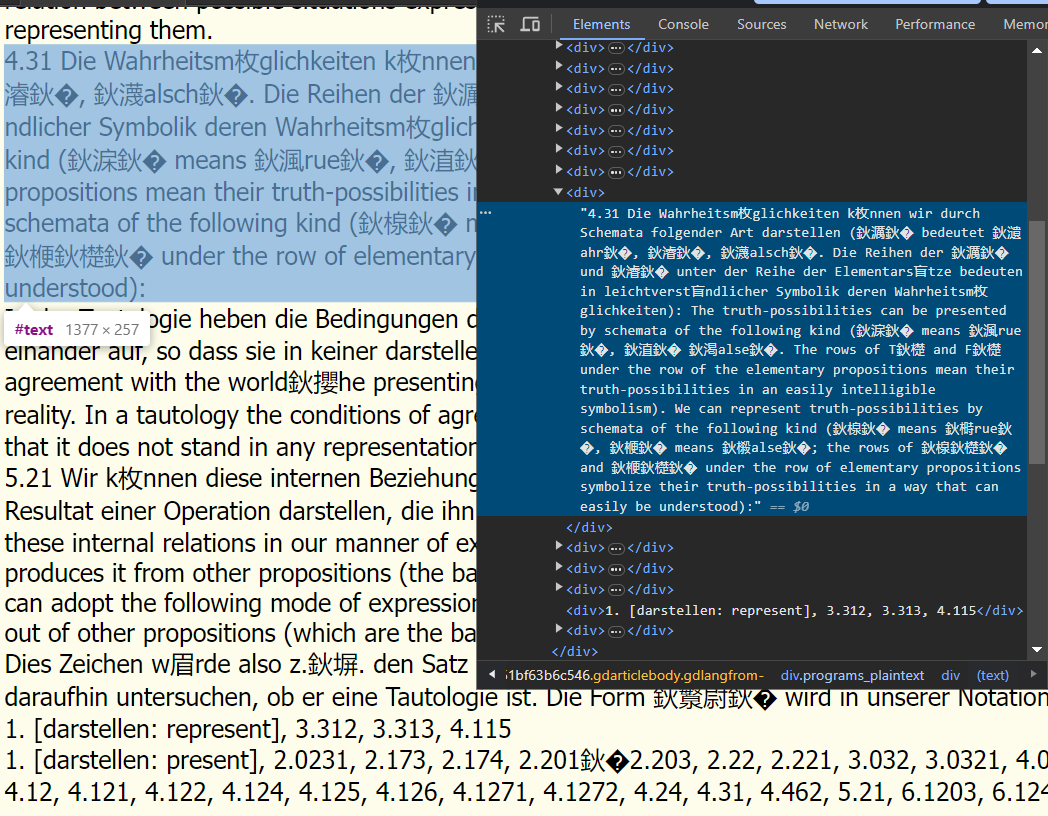
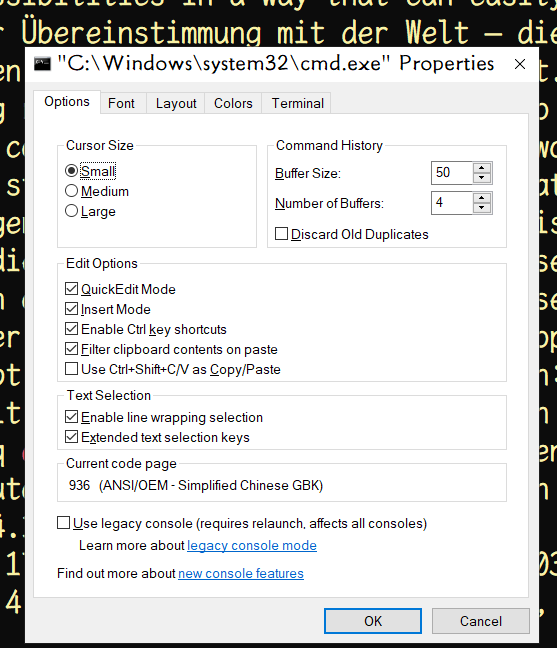
尝试在cmd中使用同样的搜索命令,但不会出现乱码。检查发现cmd页面编码就是GBK:
在PowerShell中查看系统编码信息:
[System.Text.Encoding]::Default
BodyName : gb2312
EncodingName : Chinese Simplified (GB2312)
HeaderName : gb2312
WebName : gb2312
WindowsCodePage : 936
IsBrowserDisplay : True
IsBrowserSave : True
IsMailNewsDisplay : True
IsMailNewsSave : True
IsSingleByte : False
EncoderFallback : System.Text.InternalEncoderBestFitFallback
DecoderFallback : System.Text.InternalDecoderBestFitFallback
IsReadOnly : True
CodePage : 936
尝试在命令行指定编码格式,但结果没有变化:
rga -E UTF-8 darstellen "E:\00000\Search\TLP-3-columns.txt"
请请教如何修改GoldenDict输出编码,避免字符乱码问题。
GoldenDict + Markdown(or 任何格式化良好的文本) - GoldenDict - 掌上百科 - PDAWIKI - Powered by Discuz!
查到之前也有人发现这个问题:
- // 因为 Windows 默认编码是 GB2312,所以本项目全部转换成此编码,包括 php 内部编码、本文件以及 note 文件保存的编码。
- // 最后输出时给 GoldenDict 时,不是很懂 GD 的编码机制,反正试验结果是:外部程序类型选纯文本时,必须输出 gb 格式;类型选 html 时,必须转换成 utf-8 输出给它……尝试全部使用 utf-8,但怎么试都是乱码,所以只好过程用 gb,最后一步转成 utf-8 给它。
- mb_internal_encoding(‘GB2312’);