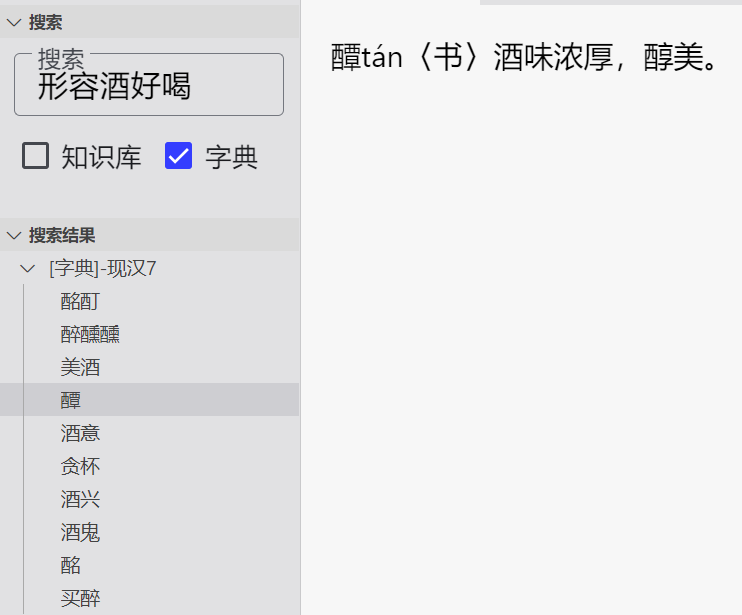
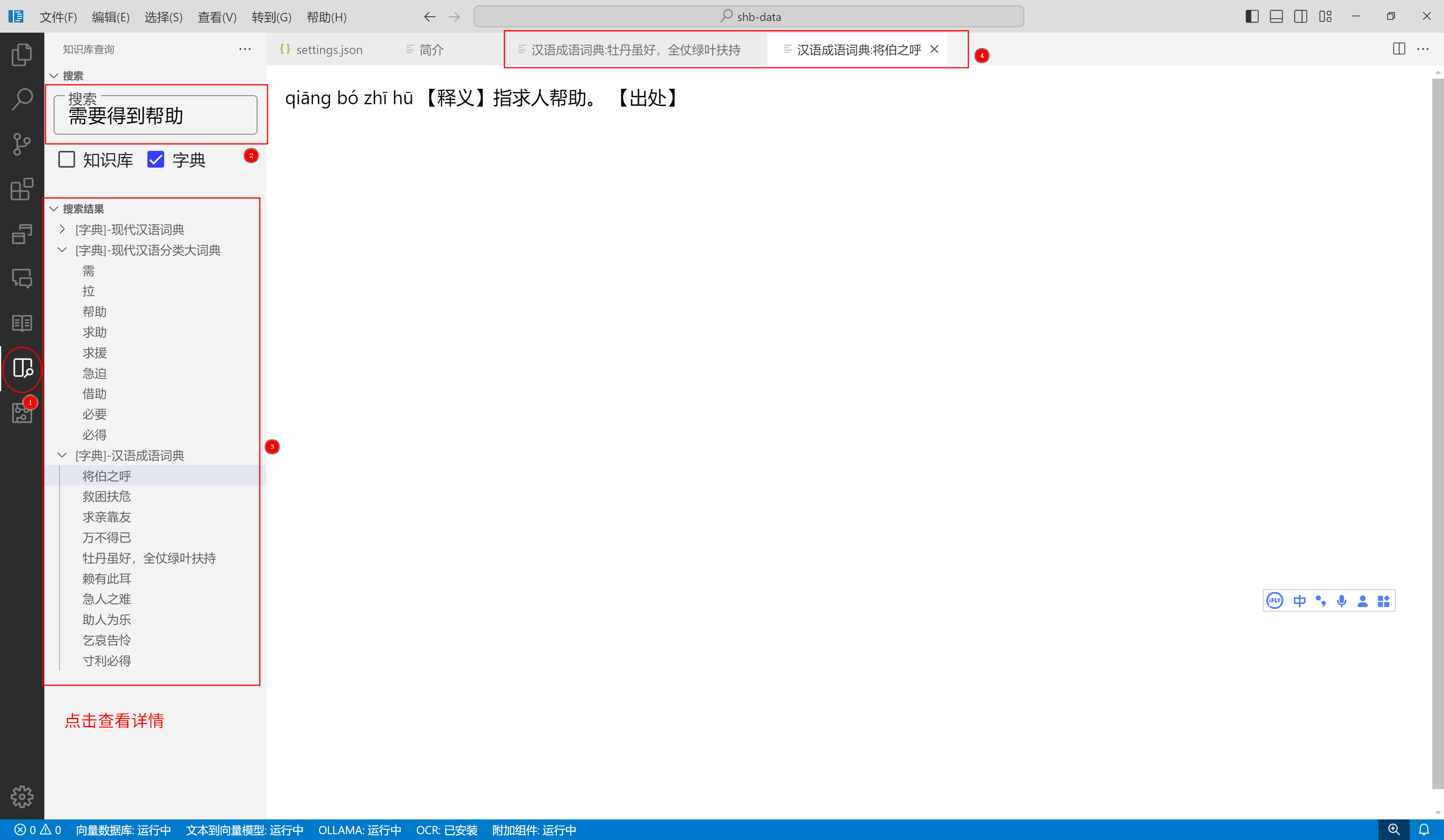
目前感觉用字典的人不多了,论坛里的人除外哈哈。可能是因为搜索更容易获得结果,也比较方便
最近我实现了一个写作编辑器,虽然叫写作编辑器,但是集成了各种功能,AI,工作流,脑图,知识库,字典,纠错,OCR等。那么我就先说说字典吧,大家也比较熟悉
字典支持startdict与mdict(v1-v3)两种,如果您只需要字典功能,那么随便建一个空文件夹,然后使用软件打开即可。
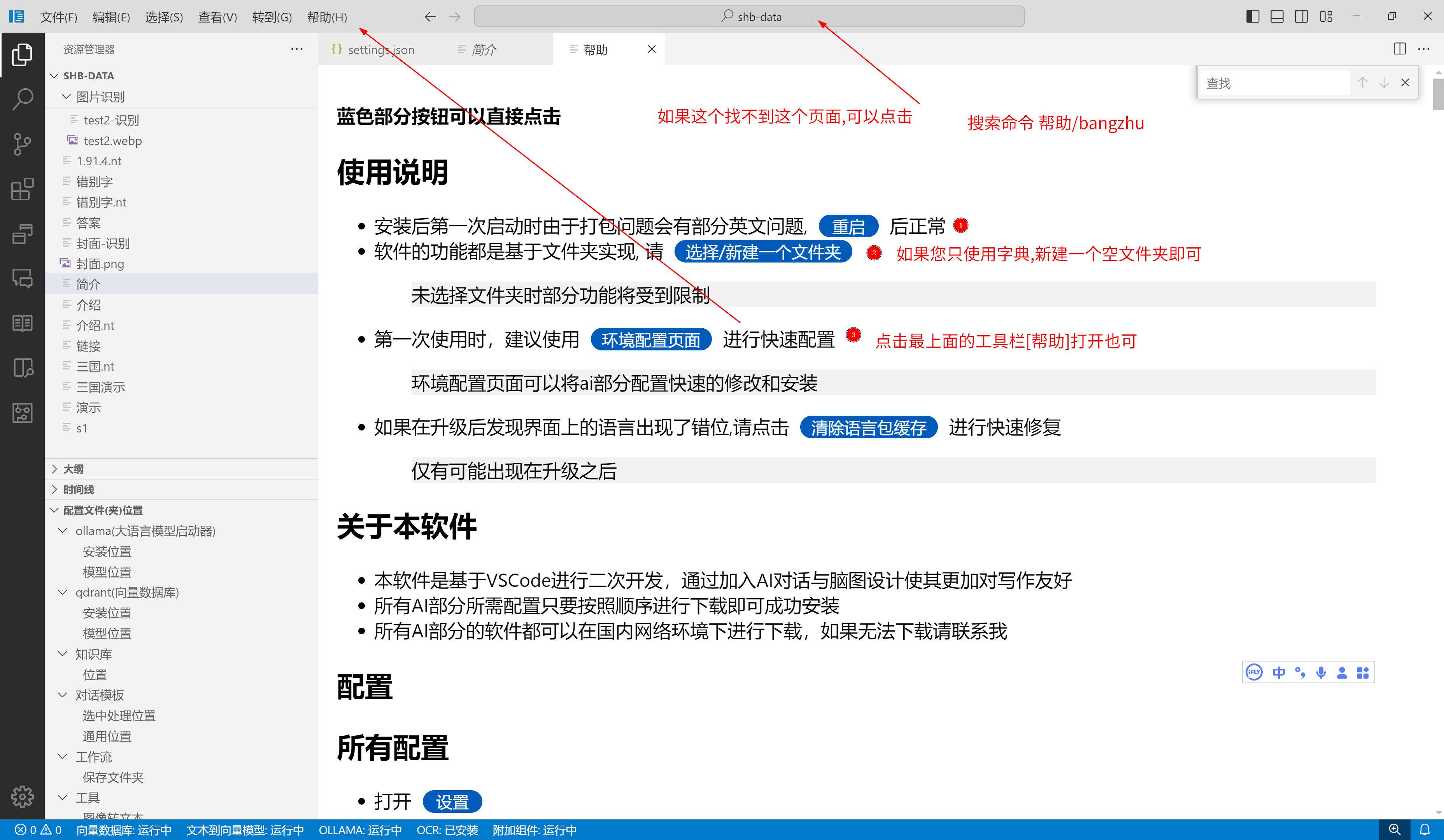
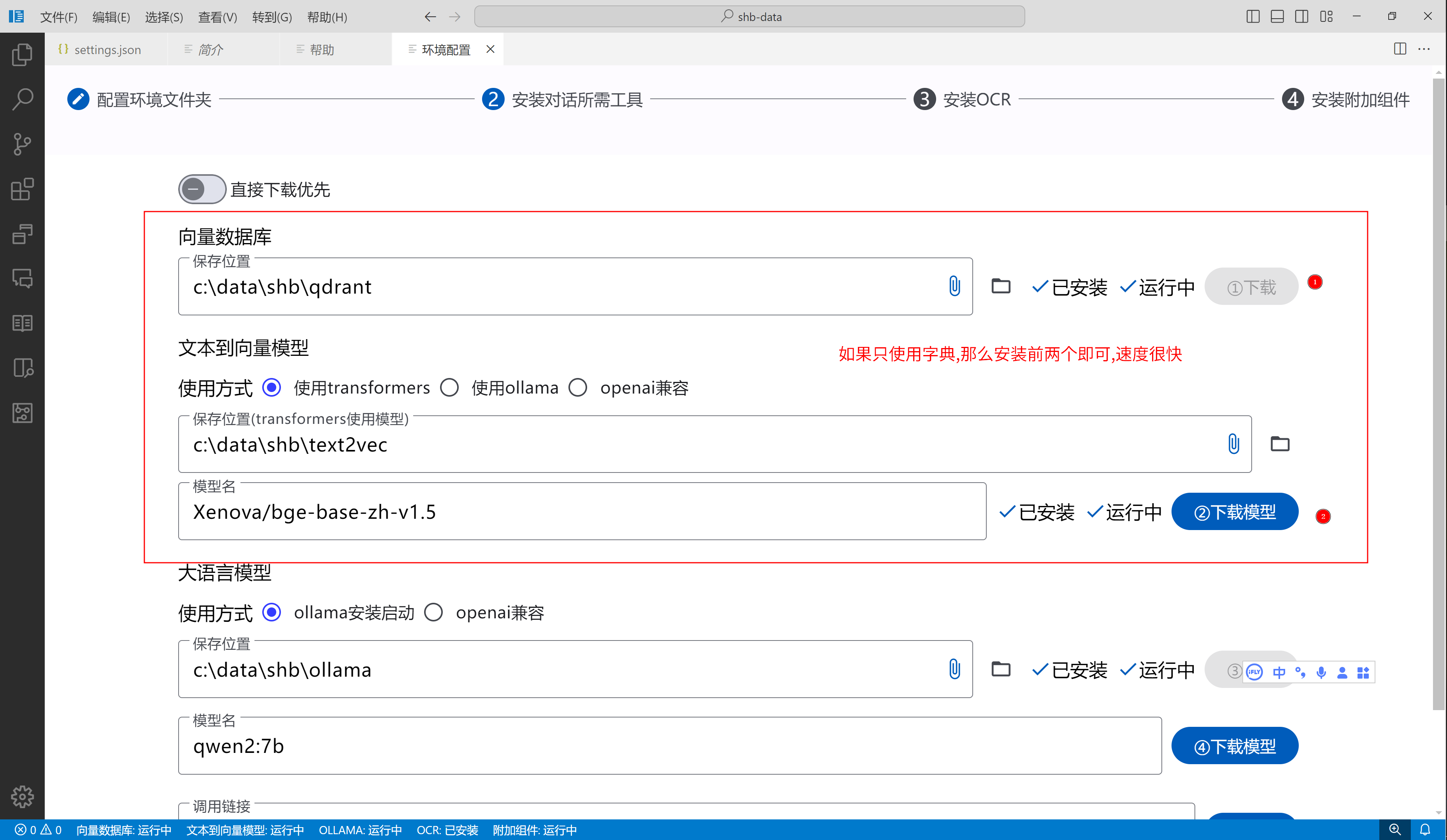
使用字典之前,您需要先下载一个模型,用于搜索使用
然后,您就可以导入字典了。目前导入字典的速度可能有点慢,我导入一个成语词典,大概使用了十几分钟吧。有人可能要问,我以前也用过其他的字典软件,都是非常快的,为啥这个这么慢?
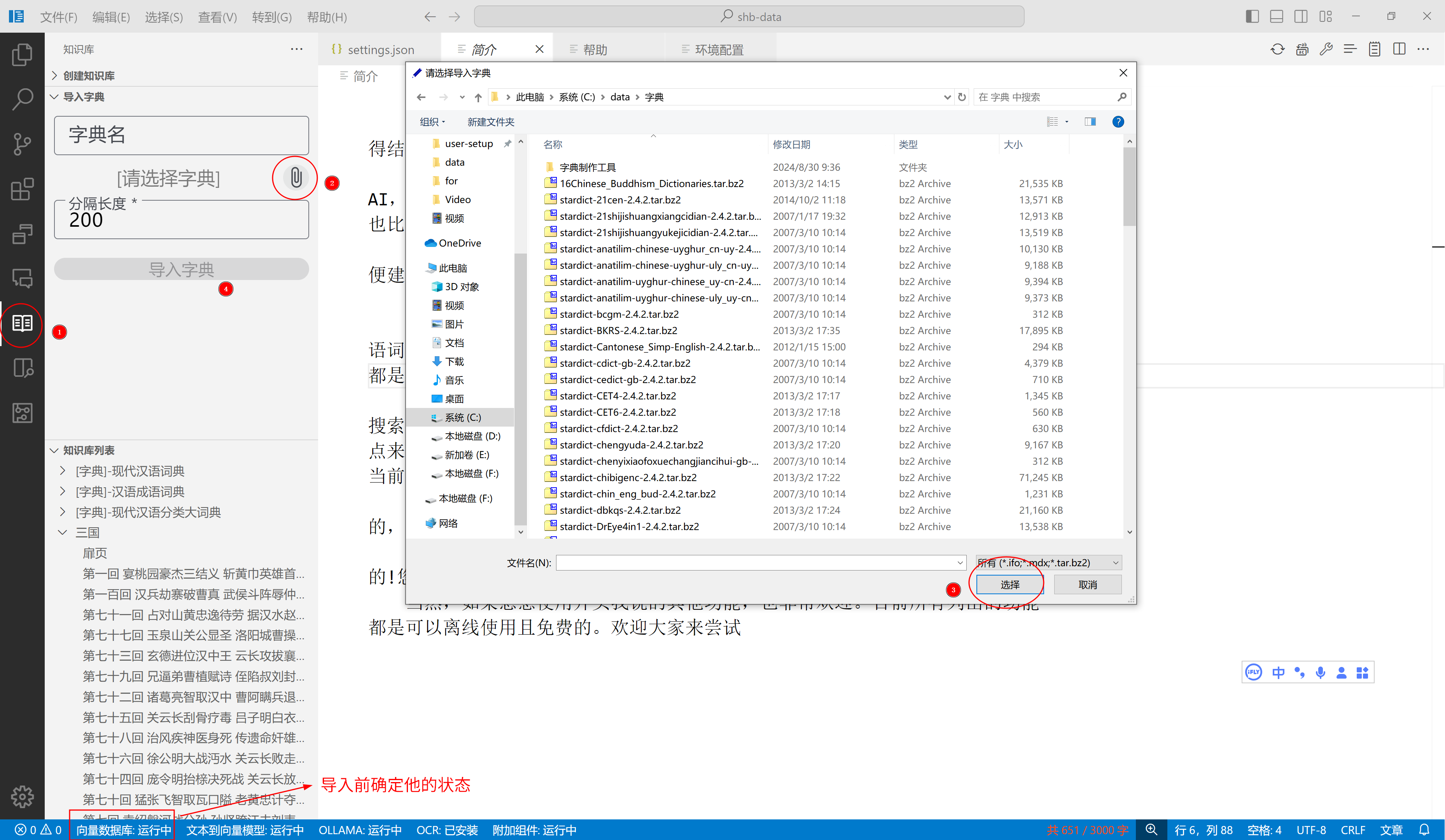
这就与之前让您下载的模型有关了,字典导入时,会将文本处理为向量,用于搜索使用。当你进行搜索时,结果不是模糊搜索,而是语义相似的搜索,更直白一点来说:假如要搜索高兴相关词语,那么目前就有可能出现"欢呼雀跃",“快意当前”,"助人为乐"等词语。我想大家应该想要这种功能吧?
既然导入慢了,那么搜索当然会非常快,目前来说搜索的速度几乎是无感知的,完全不需要等待
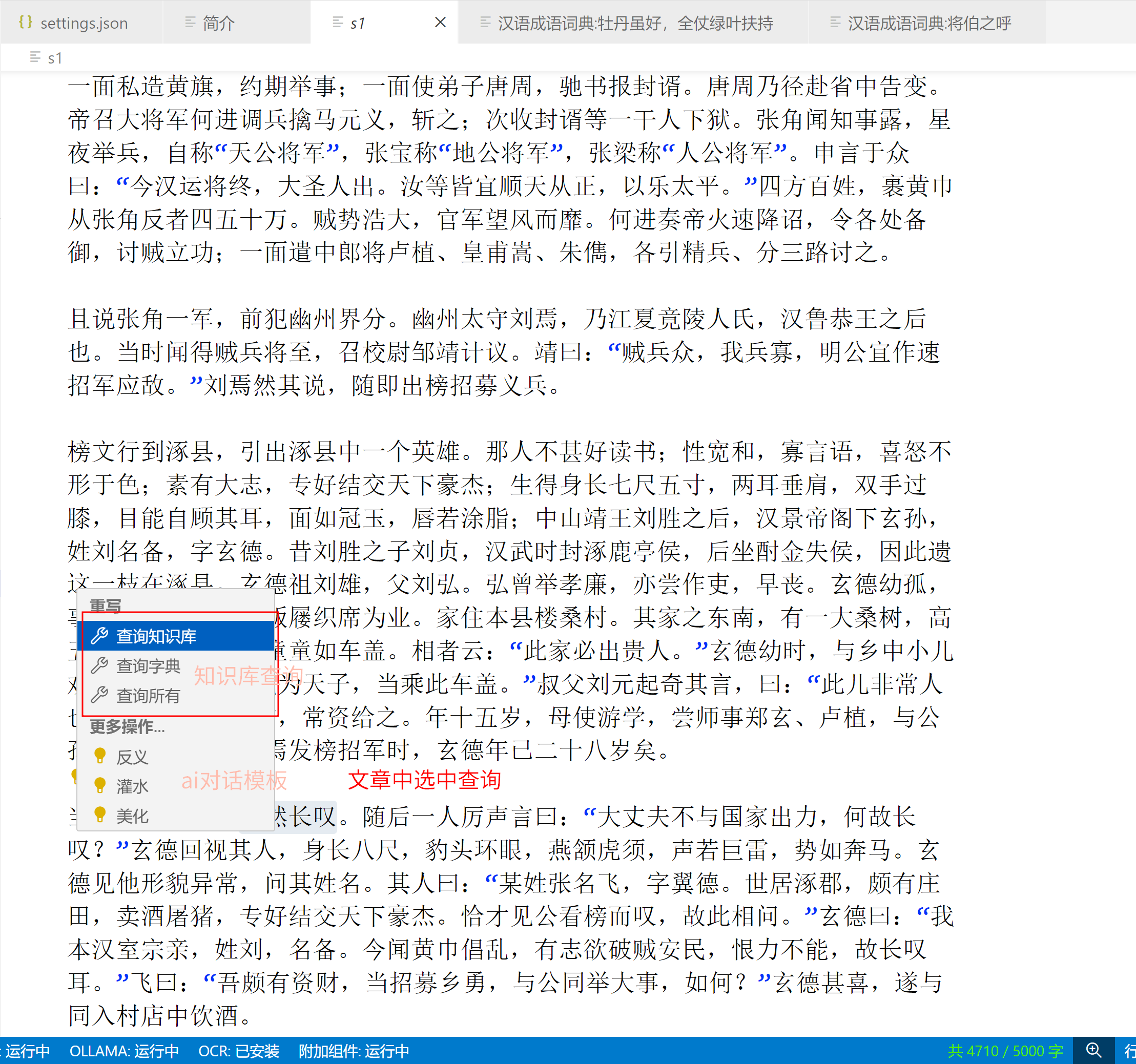
最后,以及最重要的一点,虽然软件和模型需要下载,但是下载后是完全离线的!您不需要接入任何大语言模型就能实现这个智能搜索。
当然,如果您想使用开头我说的其他功能,也非常欢迎。目前所有列出的功能都是可以离线使用且免费的。欢迎大家来尝试
下载地址: http://shenghuabi.top/api/download/win32_x64
理论上是不需要翻的,如果你用idm下载可能会有问题(不过我现在正常了,之前有问题),您可以使用本地浏览器自带下载试一试.因为我确实用了一种重定向,所以虽然我这里不需要其他手段,但是不清楚其他人是否正常(测了下也没被国内屏蔽),如果再不行的话我再调整下
有可能是cloudflare 在国内又被劣化了 
我研究下国内哪个方便一点吧…主要是是用收费的怕被刷流量.本来就不要钱的东西到时候还欠运营商一屁股
首次运行,在第4步安装附加组件–2。安装文本纠错模型,这步骤,总停留在下载提示阶段—下载中。。。
这个他首先会安装python,然后pip下载依赖.依赖下载完成后会去下载模型
这个模型部分也是用的cloudflare去下载的…所以有可能今天cf抽风导致下载有问题 这块我是真没法解决,只能等待.因为如果不用代理的话,直接连hg可能更无法下载…点击运行中或者你点下左下角的附加组件,会弹出日志,看看有没有什么问题;
搞过开发,本机已经有python环境的,能否在您的程序中,给个设置,手动指定一下对应的目录啥的,省的重复下载。或者干脆就说明白,用的啥东东,自己在您的程序外部设置好了,然后通过配置文件,或者你自己程序的能公开的接口设置啥的,手动指定。缺啥pip依赖的,搞过开发的,都有本事摘下来。
为了照顾普通用户,所有环境都会自己下载,不会依赖任何本机环境的python及依赖
简单的说就是会下载一个python,然后执行的时候,PATH会指向这个python目录,保证所有依赖都是使用自己的这个Python环境执行,因为代码是依赖python的,而python又有很多版本,总不能让小白也自己去下载一堆东西…
所以里面的Pip镜像我是配好了的,hg镜像也配好了,理论上不会出现问题.我拿了另一台没python环境的试了下是正常的.但是我也不能保证肯定100%正常,所以希望大佬们有问题多多反馈
大佬卡哪一步了?左下角会显示附加工具的状态,点击会打开日志,如果有问题可以查看那里
电脑没有装python,点击环境配置没有任何反应。对这些技术不懂,暂时不弄了。
用了一下搜索功能,真快。感觉超越市面所有类似软件,已把电脑中的同类软件,通通删除了。
词典还在导入中,不知道又会又什么惊喜。
多谢测评,看来还是值得试试。但昨天程序还没下载完,中途没有速度了。不知道模型有多大,恐怕得几个G吧?
正在准备改下下载方式(用户不用管,改后台接口).改完后下载软件会有改善.模型相关的也应该会有改善.昨天我看了后台有10%左右的失败概率…(免费的东西果然是最贵的)
本软件,应该是第一款Ai搜索离线词典吧。令人兴奋!
就是导入太慢了,6.9万的词条,笔记本电脑导入长达近两个小时。早上用台式机导入到5千1百条时就卡死了。
这样的速度,就没有意义了吧?如果导入《中国大百科全书》得多长时间?不敢想象。
好有毅力…我一般都用的是1w左右的…没想到还有7w条的.这个速度后期会优化的,因为当初设计的时候最开始没导入字典,所以压力没那么大用的cpu跑的.未来会改成基于gpu的