数据日期2024-08-27,全部免费内容都下载了,体积庞大,八千三百万个例句。
主要优先文学,艺术和人文科学,加上科技,医疗,最后才是大众传媒新闻体 (后者量足/满大街/cookie-cutter/机器人一般,就排最后了)
按照时间顺序,越早越古老越好(其实也就是本世纪上半叶)。
2024-10-23: 加了语音 (感谢@Hazuki)
原来的mdd 没有发音(但是支持MDictPC),可以覆盖
另外合并了addendum。
失效:
https://pan.huang1111.cn/s/Nk9D8c1
FREE
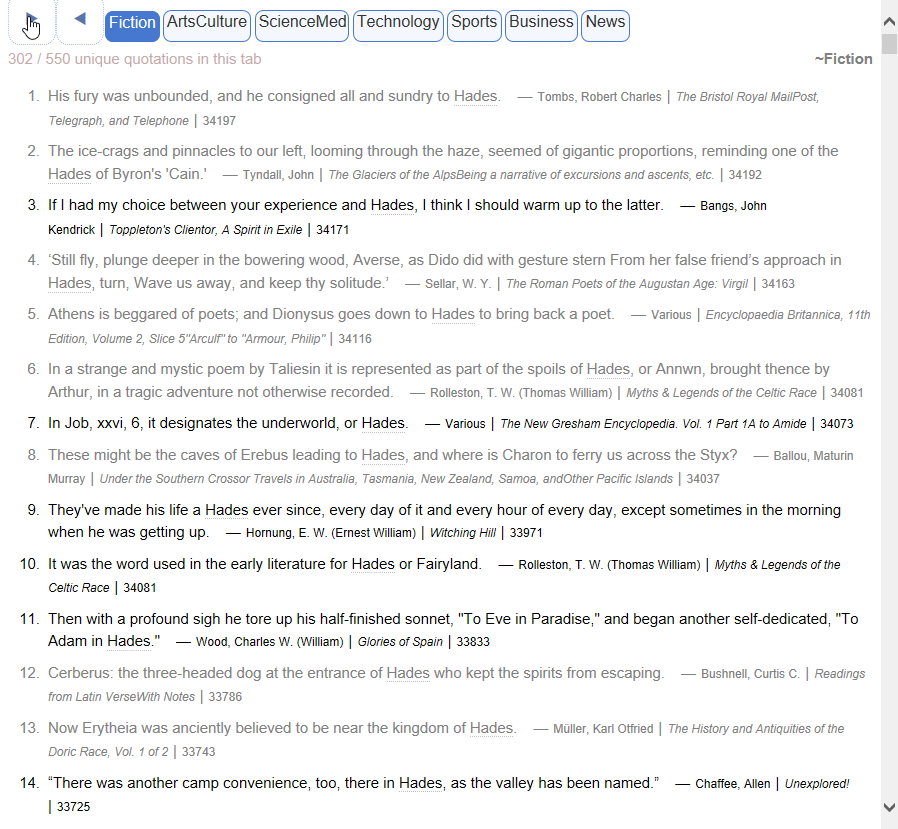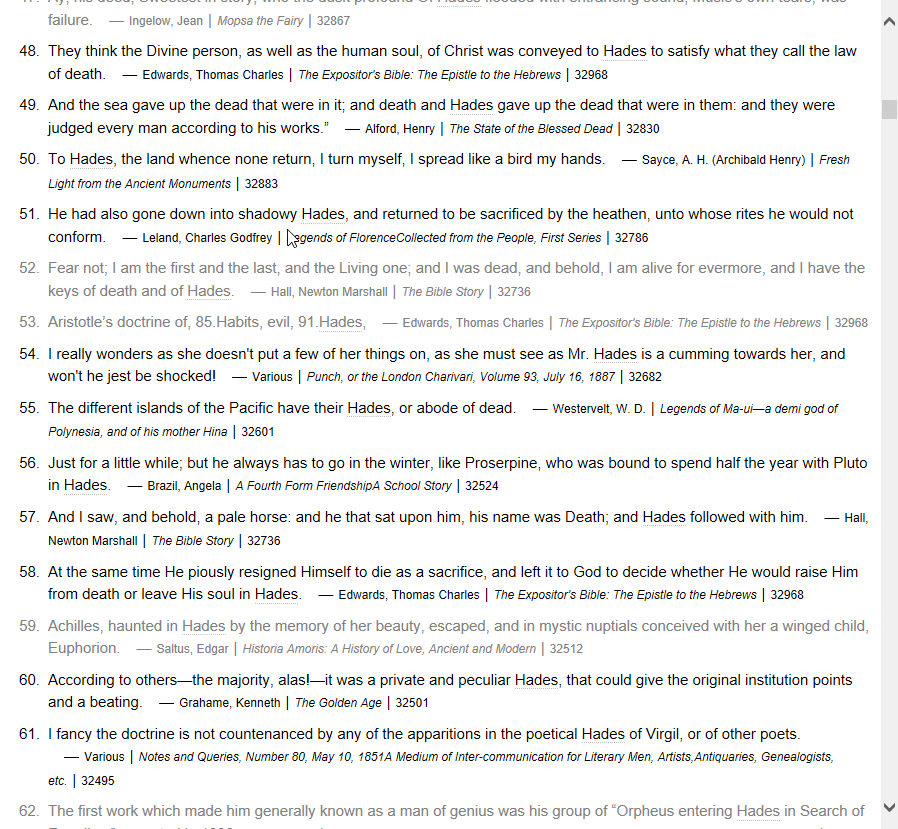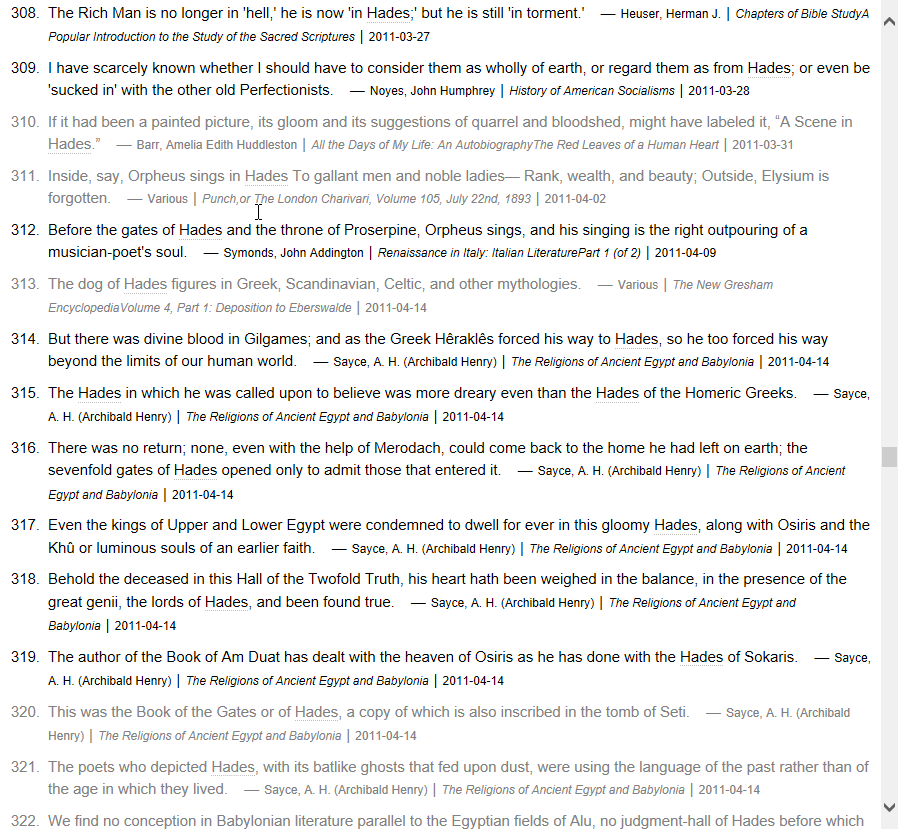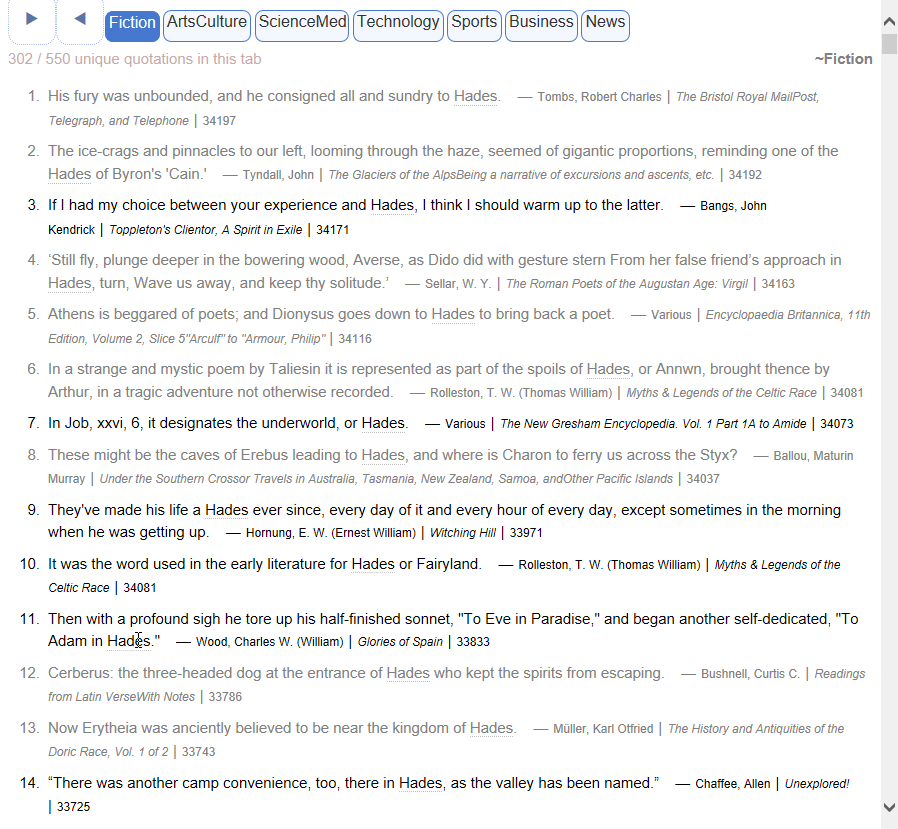
词头147319,来自 Vocabulary.com Dictionary by dfsfd@pdawiki Build at 2018/4/17
headwords.rar (572.5 KB)
mowang
10
8、9G,这种语料库级别,覆盖面应该可以更广些,这个词dozenth竟查不到。
我打算把unabridged的字典里面的词头另外分开做一个补集, 前提条件是corpus里面有这些词头的例句
encn
12
VocabularyCOM 内在的词表,我在去年做了一份,目前应该是最完整的。
另外,我做 VC Examples,下载数据只下载了一个小时,网速大概 10MB/s。最后打包成 mdx 体积 3GB,我估计 VocabularyCOM 完整例句库做成 mdx,体积至少几十 GB,可能超100GB。
免费的部分不能超过550个例句/genre,reverse chronological order.
也就是说过去的就没法读取。不排除付费的可以。比如有些单词显示27000个例句。
我这里速度很慢,大概并行5个的话15个小时。体积原始数据大概50GB。
你推荐的词条是那个#15楼合并的吗,凡是不在voca里面的词条都没有任何例句的。
encn
14
以下内容凭记忆回复,现在可能不准确了。
我记得获取例句有两个接口,一个是分类口(文学、科技等),这个接口很坑,每次请求最多返回50组例句。但还有个 random 口,该接口每次请求可返回至多500组例句。
我是先用分类接口,雨露均沾,各类别都下载一点例句。然后直接走随机接口,大力出奇迹,全速下载例句。随机口返回的好像大部分是文学类别例句。
词表就用上文的三合一词表吧,它是目前已知最完整的 VocabularyCOM 内在词表。
encn
15
使用随机接口,理论上应该可以离线整个例句库,但是 mdx 太大,也没法用了。
我还没有试过不过滤的random接口,如果它多快好省,我就试一下,外加去个重。不敢想象最后体积有多大。voca很可能有某种限制,待发现。你的strategy我觉得很好。
加了addendum,含有从2018年后词头1051。只要下载新的mdx,体积45MB.
新词条来源依据
1) Vocabulary.com 2023.12.02 (欢迎使用反馈) - 英英 - FreeMdict Forum
2) MWU2023
去了几十万个词头以内重复例句的现象,修复了一些不规范malformed json问题。
体积只缩小了几十MB。
实际上9千多万个例句,里面有四千多万是重复的,但是它们被分散放在了不同的词头下。也就是说,平均每两个例句就有一个重复,但是是归纳到其他词头以下的。也可以认为是一个例句里面会有两个词头被Vocab官网highlight,然后重复出现于各自的词头里面。
这是vocab官网的问题。不打算删除这类的一句两用的地方。不过删除了以后,体积会减半!(可用性可能也减半,毕竟第二个词头里面就没有那同样的例句了)
Date in title is rewound to 29th.