阿弥陀佛
1
先下载整页版词典,也可自己做整页的。整页和教程推荐此教程:一键制作图片词典 MdxSourceBuilder - #39,来自 huamaofan
今天以此为例:先下载
【整页版】中国历代官制大辞典(修订版) - #9,来自 tzq0014
一、解压MDX,MDD,用 MdxExport.exe 这工具。MdxExport3.5-MDX与MDD资源导出小工具。
得到TXT和图片。

二、处理图片,先切白边,用老马的ComicEnhancerPro。比较简单,也有相关教程。自己找下。切白边后,效果如图:
2.1、有部分图片要单独处理。此书为例:有1、3、15、89、210、355、443、494、623、711、776、829、875、900、913、924、932、935、937、939页要单独处理。用PS处理下。移到左边,方便切分。否则不好看。还有的更复杂,像王力古汉语字典、辞源之类的,中间断开,分为上下两块。也要单独处理。如果没有中间的部分,此步可省略。
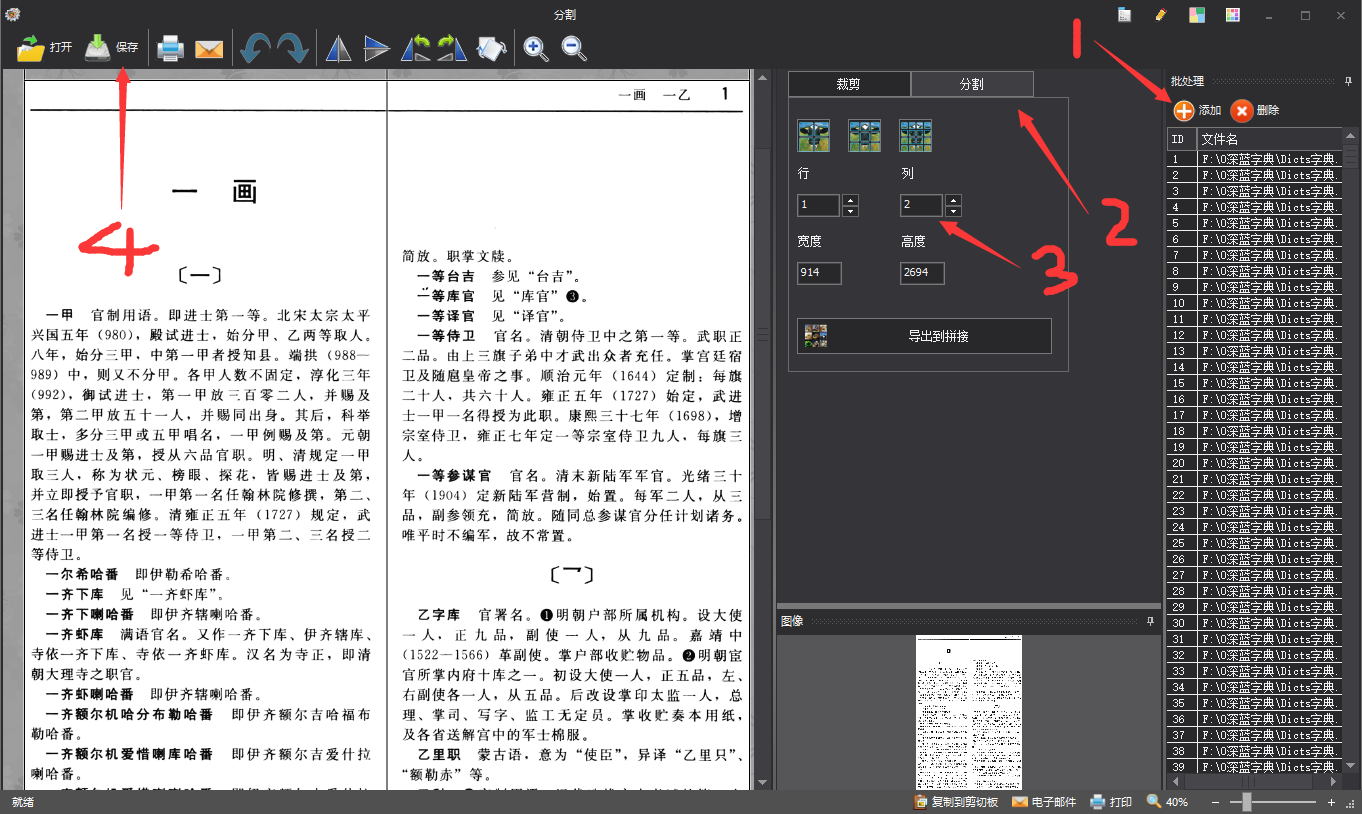
2.2、切分图片。切之前先检查下白边是否都切干净了,有的四周有污点,软件切不干净,要单独处理。切分图片我用的是图片工厂。也可用其他软件。
等会。。。完成之后,跳出:
已经切好了:
全部提出到根目录:用此小工具,复制到此文件夹,双击运行即可
提取子文件夹中的文件到根目录.rar (184 字节)
完成后删去空文件夹,效果如图:

重命名:我用菲菲更名宝贝,其他都可以,_1_替换为.即可。其实不更名也行。我习惯更名,显得简洁些。
更名后:

把不用切分的图片和已经切开的放一起。进行二值化处理,就是去色,压小图片,否则图片太大。老马软件ComicEnhancerPro
此处可单独出一教程:要求不高的,可自己简单摸索。不难。参数要反复调试。达到最佳效果。图片较多,此处要花些时间。。。
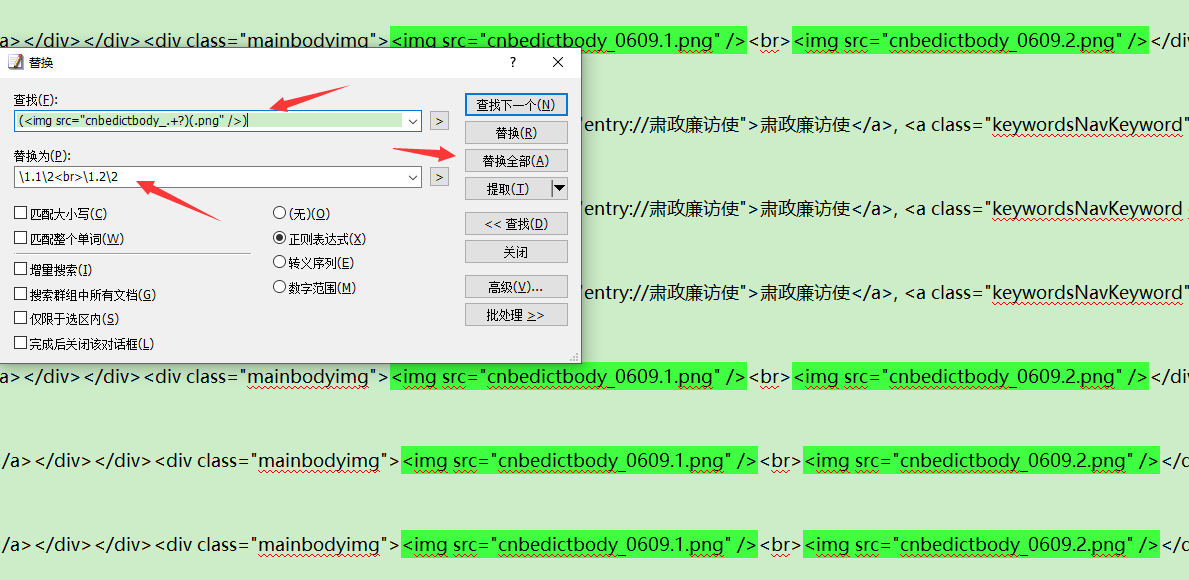
三、以上,图片就处理完了。接下来要处理TXT。软件推荐EmEditor,处理大文件流畅!要懂点正则:
(![]() )替换为\1.1\2
)替换为\1.1\2
\1.2\2
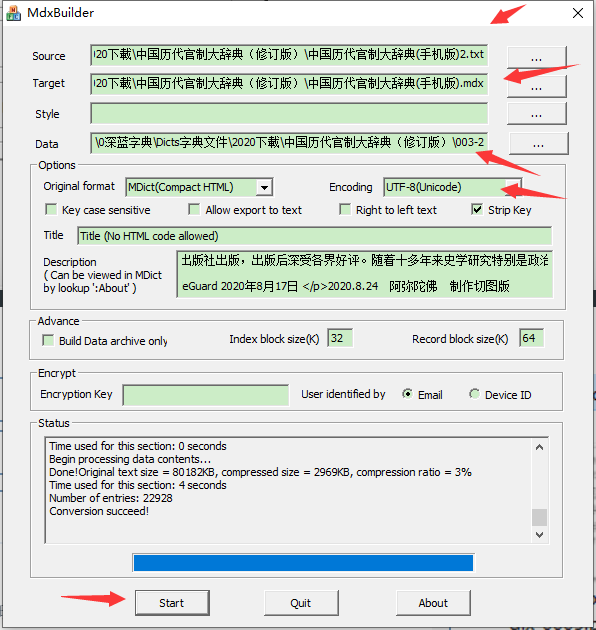
四、重新打包。工具MdxBuilder3.2
CSS可放在图片文件夹里一起打包进去。

这样就完成了切图版!
完成的成品效果图:
成品下载:
链接:
https://pan.baidu.com/s/1BGNeJwVw8mz5XGM0noI7GQ 提取码: uch5
師兄,太強大了,讚呀!在下,都搞不定老馬的切邊,都用scantailor,為了切個邊,手指都搞到快中風…切邊真是太麻煩了!
ComicEnhancerPro 的自动化处理很强大,可拿几张图片试验几次。
如果处理的图片质量没问题,则选择自动识别范围,页面大小选切割后大小(如选周边填白,则页面还是有空白)。
如果处理有扫描黑边的图片,第一遍可考虑不切空白四周,先去黑边居中。有的pdf 奇偶页其实是有规律的,那可以分开两次分别处理(识别范围红色方格做下调整)。等没问题了,最后一步再去除四周空白。
Vim
9
Tg群中前不久有高人帮我使用 OpenCV 处理切边,很好很强大,需要的可以去学习
annham
10
您好,如果是三栏,该怎么替换呢,希望帮忙解答,多谢了
阿弥陀佛
11
(<img src=“/.+?)(..+?width=“100%”>
)
(<img src=”/.+?)(..+?width=100%>
)
\1.1\2\1.2\2 兩欄
\1.1\2\1.2\2\1.3\2 三欄
annham
12
您好,多谢回复。怎么跟上面的教程不一样?还有,如果是四栏呢,譬如您最近制作的古音汇纂。
annham
14
您好,这一部分(…+?width=100%>)在上面的教程中并没有啊,这怎么替换呢
annham
16
您好,教程中关于txt正则替换的图片中显示的是(![]() ),并没有(…+?width=100%>)这一部分呀,这是您新制作的词典当中的吧?
),并没有(…+?width=100%>)这一部分呀,这是您新制作的词典当中的吧?
真是坏呀,这是把扁担箩筐都给备好了就等苦力上阵了呀 
但是,有时候源文件质量才是最麻烦的。
这本英语搭配大词典,以前在隔壁看到过有人发贴展示过做好的词典MDX,似乎是更清晰的版本,没有公开分享,而手里边只有这个1.5G的,文件很大,但扫描质量其实不高,应该是读秀抓下来的,我试图处理下,但显示效果提高有限,而且文件大小又增加许多,只好放弃。
老马切边,是设置一个之后自动识别、切图吗?上手了一下,要一张一张切吗?