阿弥陀佛
1
原數據似乎是出版社放出的,不知 是他們有意還是無意,這數據是殘缺的。不完整。
說明:數據不太完整,如 很多字最前面的 《説文·部首》。原數據缺失。追求完美的可以手動排查,加上。
收錄11670詞條,其中 116條 詞頭亂碼。需要手工校對。切詞版有13636條。
我沒空去校對了,如有興趣的書友,可自行校對。
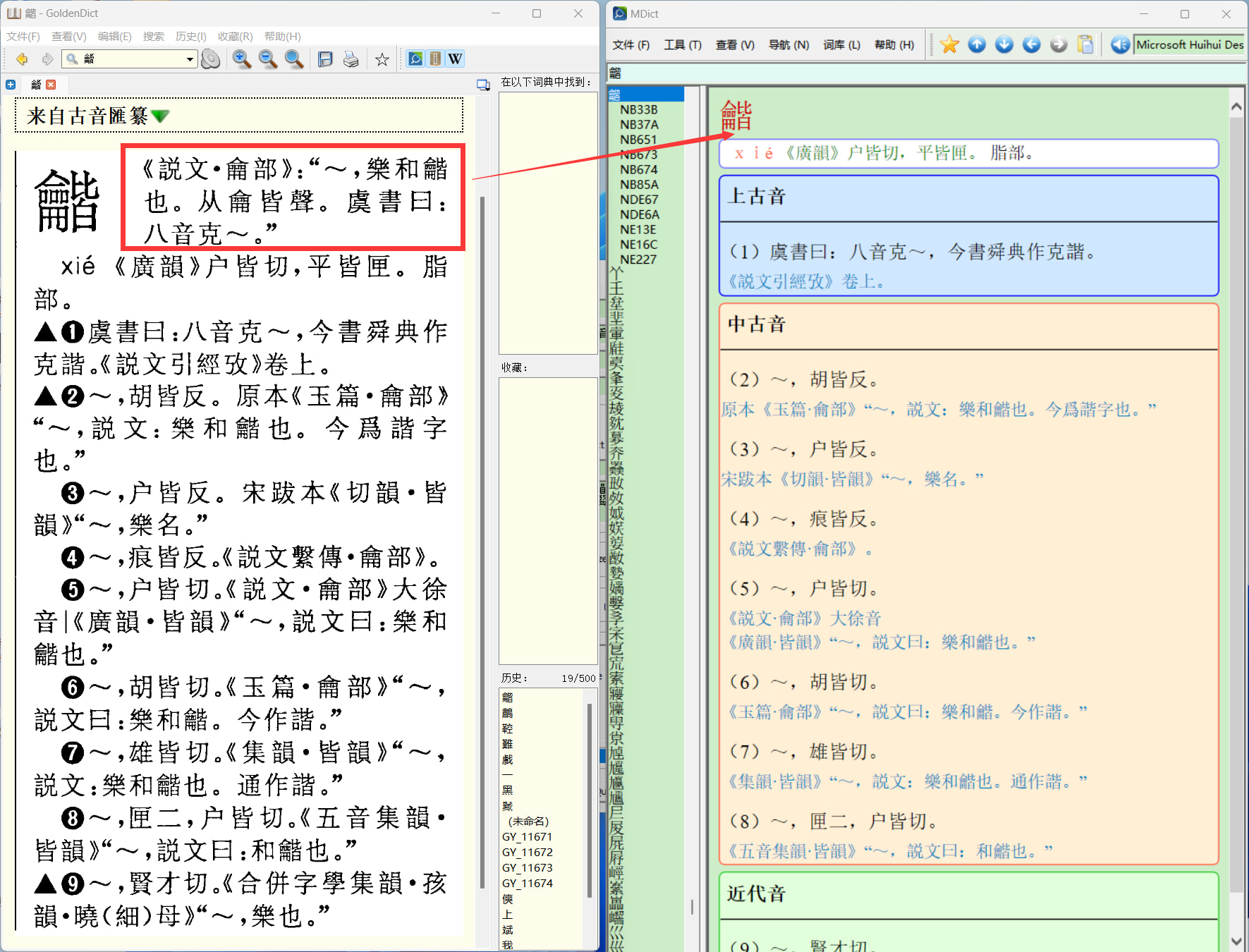
校對時參考圖片版:
《古音汇纂》是一部上起先秦、下迄清末的历代字音资料的大汇编,立项至今已整整10年,目前已建成含100余万条古音资料的电子数据库,并试编了样稿,计划于2010年完成初稿,约1300万字,由商务印书馆出版。
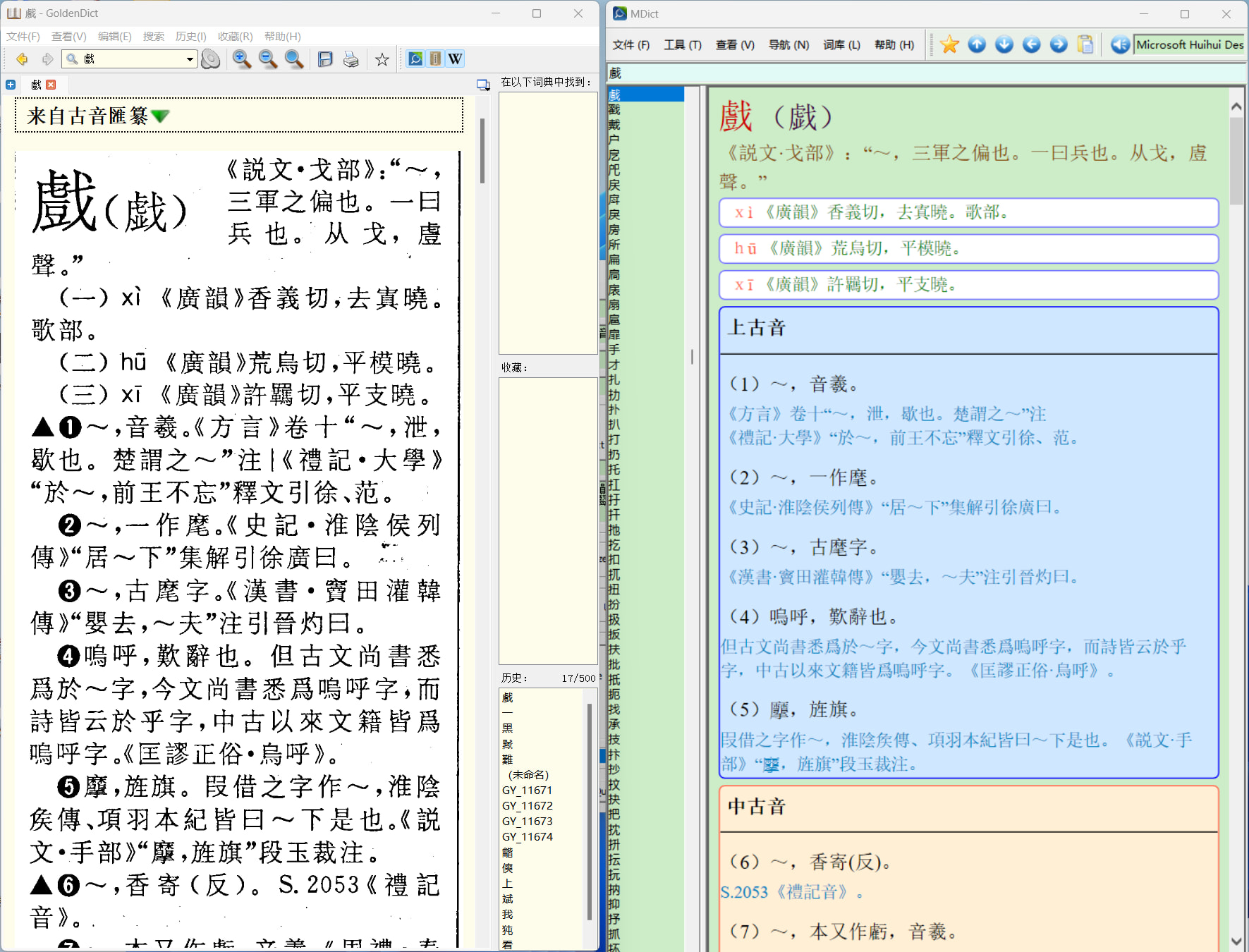
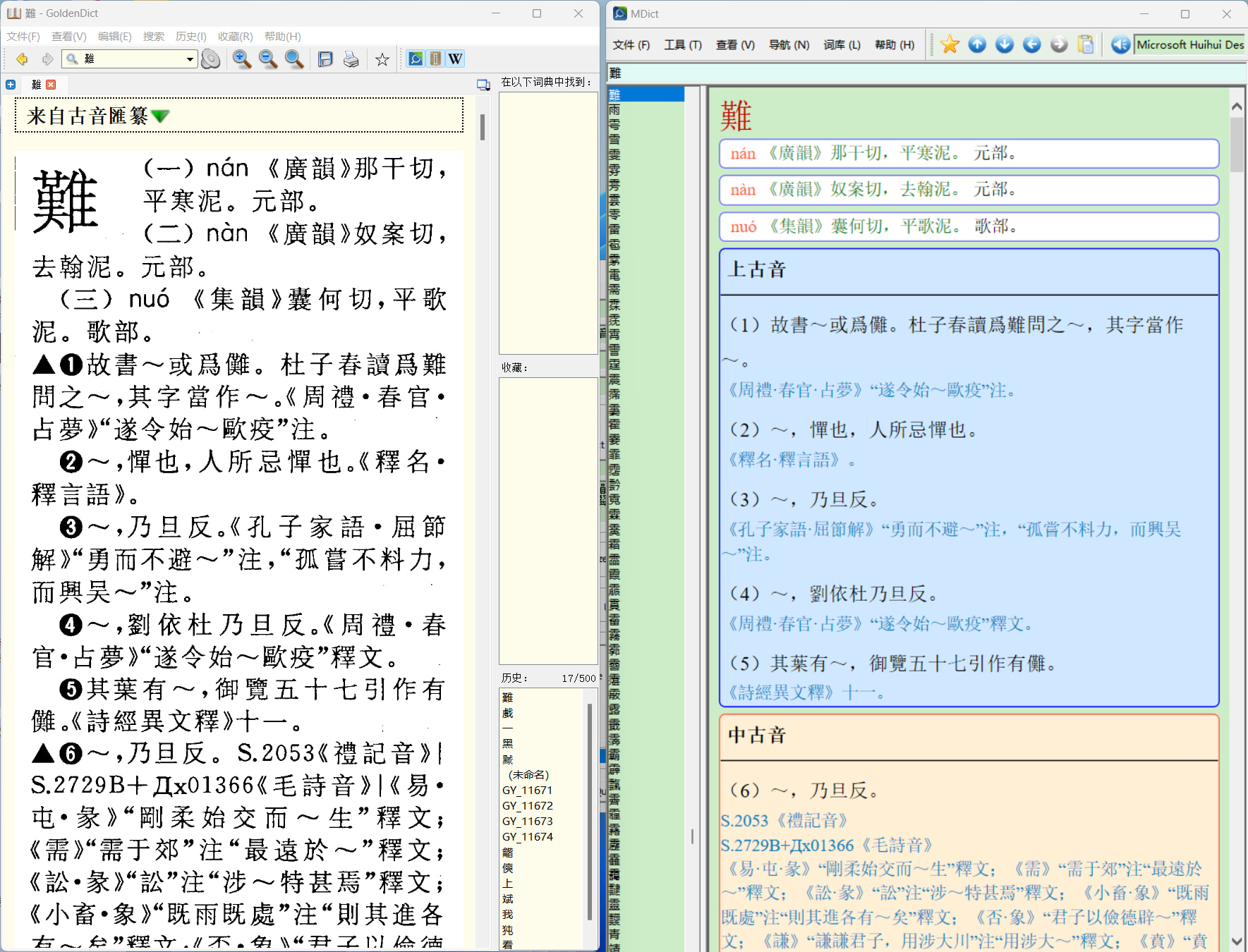
對比圖:
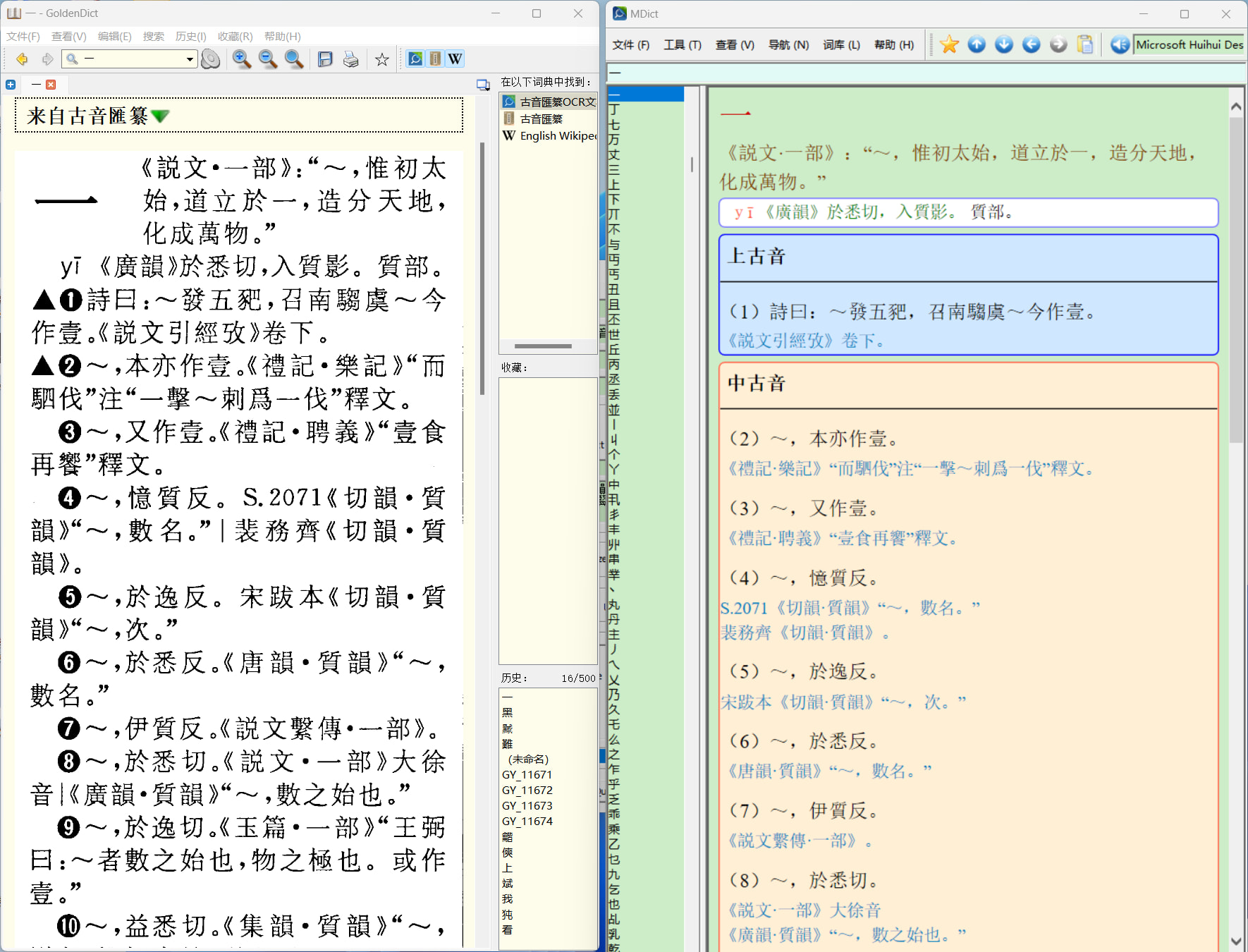
如下圖,說文 缺失:
基本能使用,如能校對完整那就更好了。
古音匯纂(文字版)MDX.zip (9.8 MB)
校對請下載:
古音汇纂-源文件TXT.7z (6.7 MB)
missing.txt (9.3 KB)
真的是殘缺的嗎?
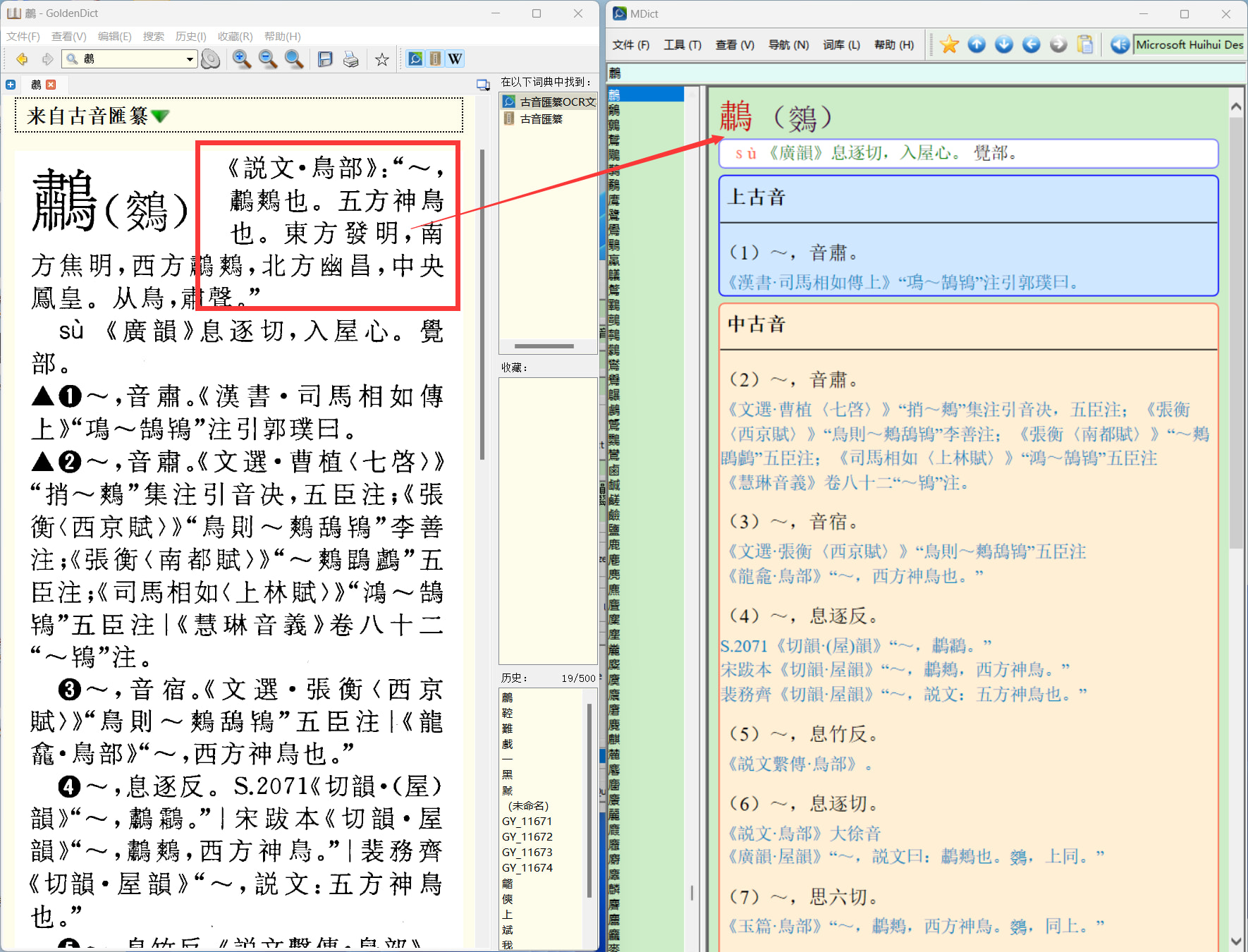
隨意找了十幾個缺失的字頭查了查,都是某字的異體,即原書字頭旁用括號圈起來的字。
前幾天我正在修理。雚、𩓞、𩹾等字條也缺說文內容,不知這類究竟多少。
字條總數實為11,675,原數據誤併了幾條。麻煩的是有幾千亂碼/PUA,起碼500多是獨特的。尤其是本書引《切韻》和“原本《玉篇》”,有不少字形全宋體缺,而且有時《匯纂》列的字形失真。
亂碼/PUA,處理了幾百,但發現又有其他模式的,結果獨特的還有一千多 
乘興做到哪裡就哪裡,不可能完成。
看到个哥们处理私有字,摘录下私有字所在的句子,然后直接问 ChatGPT,这中间的私有字符应该是什么字,最后转成 HTML 标签标记起来。
<pua val="私有字符">正常字符</pua>
像ctext.org之類的網頁OCR出來的錯字,這種不可靠的數據chatGPT當作底本,它分不出是非,離不開 AI hallucination 的問題。
books 的 xml 的数据 与 knowledge_ser_plat_pc 的数据,对比了辞源这个词典,用的一个编码。
如果这本《古音汇纂》也是一个字体的话,可以根据 knowledge_ser_plat_pc 的字体,分析字体的xml数据(字体转xml的库是 fonttools)中的笔画起点特征、趋势走向进行还原。原文找不到了,只找到个类似的文章。