链接:https://pan.baidu.com/s/1so9AwJIQQBnfVXkl9GsXrA
提取码:kxly
好像存在没公开分享的切图,图片版本。
大概2000余条,前面有汉语检索词表,有高手有空时能做成图片版词典方便一下大众就更好了。
链接:https://pan.baidu.com/s/1so9AwJIQQBnfVXkl9GsXrA
提取码:kxly
好像存在没公开分享的切图,图片版本。
大概2000余条,前面有汉语检索词表,有高手有空时能做成图片版词典方便一下大众就更好了。
这个PDF质量很不错![]()
很不错!就是有几张曲度歪斜很严重,切片不行,高亮定位版可以有。
@W2K 做噢,我打辅助,负责ocr词头以及最后整合数据。
还有谁想学切词,准备好软件一起来吧。
![]()
![]()
![]()
![]()
![]()
我我我我我我
你还用学嘛?
你可以给@ W2K帮忙,或者整合数据交给你?词头索引我差不多已经弄好了。
切词的正则替换没找到呀,整页的是Excel‘’
什么?没看懂
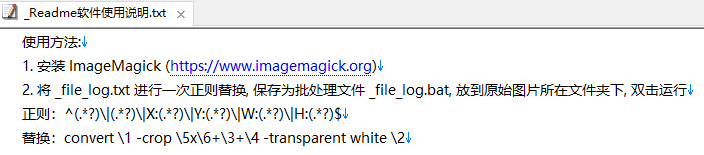
chigre切词部分替换的正则表达式没找到,实在不行就自己写一个了,
你说这个?
^(.*?)\t(.*?)\t(.*?)\t(.*?)\t(.*?)\t(.*?)$
magick \1 -crop \5x\6+\3+\4 -transparent white \2
不是,这个是抠图的,我直接软件切,出来的那个wword有没有现成的正则替换为mdx那样子呢
有的(1)(2)排序是对的,你正则厉害,可以想一个。
我都是将页码结合(1)(2)(0-1)等生成序列作为排序依据,按该列数据升序排序完再删掉。
最后把除(1)外的所有归到(1)后。
这个词典看起来挺好。没人做成MDX呢