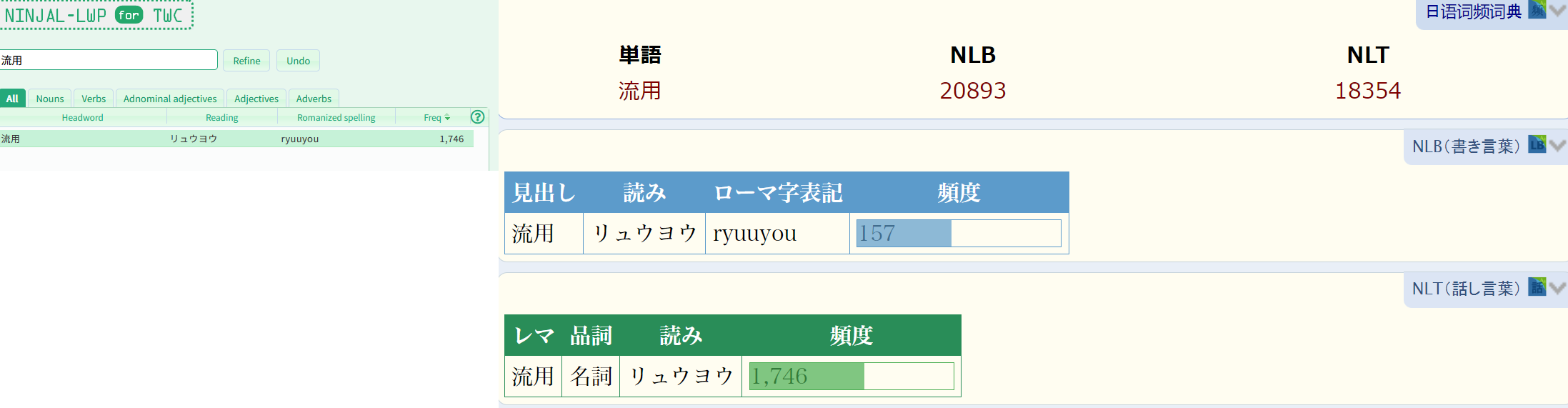
原数据只有频度。柱状图表示频度排名,越常用则这个条越长,仅供参考。
日语词频.zip (6.3 MB)
请使用goldendict打开,其他软件未测试。
因为主要是本人自用,未来没有更新的计划。如果需要具体排名请参考 #15,或者自己重新制作,不复杂。
原数据只有频度。柱状图表示频度排名,越常用则这个条越长,仅供参考。
请使用goldendict打开,其他软件未测试。
因为主要是本人自用,未来没有更新的计划。如果需要具体排名请参考 #15,或者自己重新制作,不复杂。
自用,如果想要柱状图整体短一些可以下载这个,其他没有区别。
日语词频.zip (6.3 MB)
Thanks! I’ve the following dictionary and it seems completely different from yours.
It feels somehow more accurate than the old one, since the query results match with the website’s:
Hi. I guess your dictionary is downloaded from 日语词频词典NLT mdx - #34,来自 andywang
which shows the ranking of the word.
While my new dictionary shows both the frequency and the ranking(in graph).
Hi RANP0. Thanks for your great work. Personally, I prefer the ranking method, while most of the English word frequency dictionaries use the same way, like COCA.
Frequency and ranking? Aren’t the same? I’m confused. What’s the difference?
Frequency is the raw data. Ranking is the ranking of Frequency
For example, the ranking of 流用 is 18736/98185, which means top 19%. So the graph in #1 shows about 81%.
懒得弄了,当时没保留这个数据。。
而且我感觉这个表也不是很准确,我就看个大概就好
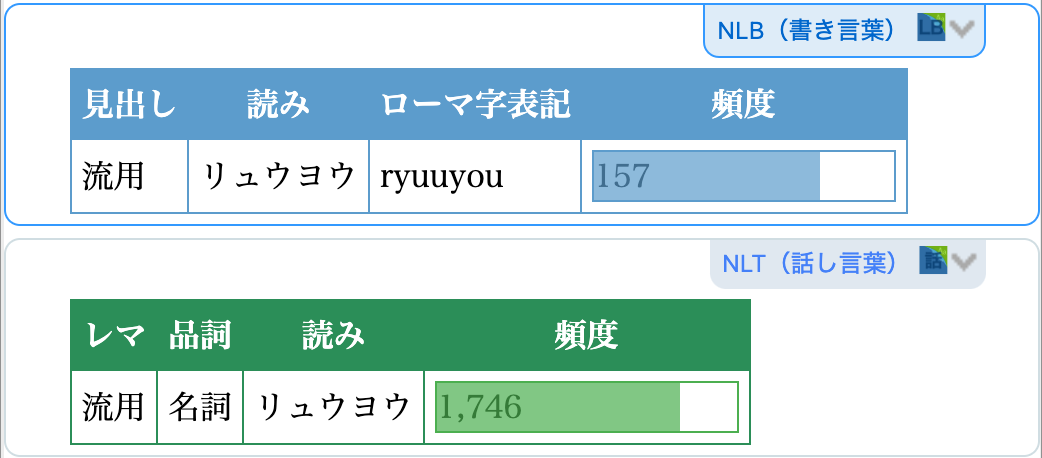
![]()
NLB(書き言葉).jpg
![]()
NLT(話し言葉).jpg
哈加两个小图标助兴~感谢RANP0大!
I appreciate the explanation, although i don’t quite understand what did you mean by “So the graph in #1 shows about 81%”.
If the graph works as a " progress loading bar" thing… neither of them give the idea of “being at 81%”:
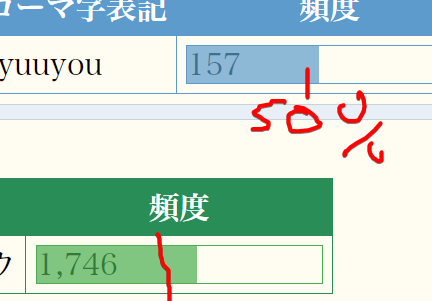
Yes, the graph works as a " progress loading bar".
It’s not being at 81% because in #2’s update I transformed this value.
If you prefer the original ranking, download files in #1.
恩这个东西感觉很不错,支持了
也看过之楼主之前发的那个帖,感觉楼主特别执着于“相对排名”,但是实际上相对排名跟收录词量有关导致参考意义不如绝对排名。
比如有两个数据来源相同的词频表,一个收录词量10K,另一个100K,那么前者其实相当于从后者截取前10K个,比如在前者中处于第1000位置的词,在后者中仍然会处于第1000位,但是按相对排名在前者中会是前10%,在后者中则会是前1%,对于学习者来说,绝对排名会更有用。
“相对排名”这个数据只在前者是从后者中均匀采样时才有相当的参考价值,但是这对于词频表或者更一般的普通的词典都是不成立的。
是的。我也搞不懂楼主为什么特别执着于相对排名和频度,之前回复过楼主,但是感觉并没有说服楼主。频度的数字,比如1000,对于绝大多数人来说就是没啥意义的,1000又能说明什么呢?但如果这代表的是绝对排名,那我就明白这是TOP1000词,这可能是N5,或者至少是N4要掌握的词。
感谢作者大大,我在原js文件上加了一点小功能,可以显示排名。
注意如果同时使用NLT和NLB的话,NLB排名是错的,但是差的不远。我是只使用NLT,抱歉不懂mdx不知道怎么改个bug。
不用绝对排名是因为日语词语很多,我猜测源文件应该没有完整统计。比如,随便搜了一下发现“フランス”都没有,因此我认为绝对词频不可靠。只能模糊统计一下相对位置。我采用柱状图因为能直观表示一个词的流行程度,一眼看出这个词值不值得学习。
当然如果还是想要的话,像#15那样复原也是可以的
关于楼上各位的讨论:
然而并没有这种情况…
很多权威词典也不会给出具体排名,如柯林斯词典使用星级,牛津剑桥使用CEFR评级
事实上源文件只有频度,没有排名,你去他的网站上搜也是只有频度。可能官方也觉得排名没啥用。
每个词点进去倒是还有很多信息,但是没提供下载。
不论是用星级还是用CEFR,都有一个约定的定义比如一星是什么词二星是什么词,你这里的定义是什么?柱状图在百分之多少时候算常用?恐怕除了你谁也不知道。
没有哪种情况?
我是说一本收词量小的词典跟收词量大的词典相比是收录词频高的那些词,而不是从后者随机挑选一些
用频度排名呗……
原数据只有频度。用这个频度作为排名,我认为不准确。所以我用直观的方式处理。
说到底这个数据不太行,你在乎一个排名的话,不建议用这个。
我想请教一个问题,有时候我想搜一个单词,比如「虚しい」就搜不到,但是搜「空しい」就可以能找到。既然它们读音是一样的,那么能否通过片假名的不完全匹配来搜索这个词典?
客观地讲,确实是排名更直观。。
而且用户也根本不关心什么绝对的准确性,NLT和NLB的收词量已经足够一般用户的使用,而没收的那些大概率是超低频的,实际上不影响排名。
而英语词表的各类标注中,最受欢迎的还是COCA这种绝对排名,一目了然