合合通用文档的说明:
支持标准的金融报告、国家标准、论文、企业招投标文件、合同、文书、工程图纸等文档内容。
合合通用文档的说明:
支持标准的金融报告、国家标准、论文、企业招投标文件、合同、文书、工程图纸等文档内容。
我没有这些个特殊文档,我只是用来OCR电子书的
那你就用文本识别的接口,这个最准确。
这个接口没有额度了,目前测不了
方便的话,把主楼的三个样本给谷歌的 AI 识别下,我对比下结果。
test.txt (6.4 KB)
更新了对比结果。三个样本对比下来还是不如合合,和有道差不多。生僻字识别明显更好了,但拼音识别出问题了。
确切说,是不如合合的通用文字识别,比合合的“通用”文档解析要强太多了。
p.s.
我也是最近意识到,合合的通用文档解析里的行识别模式比通用文字识别里的行识别模式差太多了。
我之前一直以为是同一个东西。
也凑凑热闹吧.
1,因为日常也常用ocr,但场景是将扫描的图像型pdf书籍搞一下ocr,为了2个目的,搞成双层pdf后,可以在注释时用文字高亮或下划线等注释工具.第二个目的,可以检索内容.之所以ocr后存为双层pdf,因为文字识别多少有些差错,只要绝大多数文字识别得准就可以.
2,我的这类ocr,就有三个特点,第一,pdf,第二,原文有版面,ocr后要确保版本不变.第三,识别率足够用就可以.不追求百分百准确.
所以,lz搞的图片格式,不是我的使用场景.页就不转pdf了,直接用afr15搞,支持图片,我看了效果,足够用了.
直接发3个截图,
afr15的校对是极其方便的,至今未见到比它更便利的工具.(只见过一个网站,可以上传中文古籍识别,提供了校对,是为了征集志愿者ocr汉语古籍,那个界面可能是唯一比afr更方便的)
上面的三个截图,方便复制出文本来吗?我对比下结果,晚上更新上去。
扫描全能王不就是合合旗下的品牌么。怎么不测扫描全能王?
样本一就是测的扫描全能王。合合除了贵,没有缺点。
怎么用啊,pdf不上传到储存桶不行吗?
现在 google 的 Gemini 2.0 flash 文本OCR能力很强,价格也比较便宜,还有个好处是外文识别、翻译能够一次解决。推荐在 https://aistudio.google.com/ 试用。
谷歌不翻用不了吧,我好多年账号不能登录,密码都改不了。为什么要与先进技术自绝,即便怨声载道也在所不惜。伟人说科技是生产力,还没说到底,要我说,制度才是第一生产力。反普世观的东西就是反人类。从Python到GitHub,都是一个模式。只有民间为了生存而拼命。
粗略测试,发现百度最近开源的 ERNIE-4.5-VL-28B-A3B OCR能力比较强,不少生僻字可以识别了,模型也较小,可以本地部署。
此模型可以在 https://aistudio.baidu.com/modelsdetail/30648?modelId=30648 试用。
下面贴几个样例:
1)
2)
3)
图中文本转录如下:
倭王武の上表文
倭・任那・加罗・秦韩・慕韩七国诸军事安东大将军罗・任那・加罗・秦韩・慕韩七国诸军事安东大将军倭国王と称す。顺帝の昇明二年①使遣して上表する。昔して曰く、封国②は偏遗して藩を外に作る。昔より祖祢③躬甲胄揔斡、山川を跋涉して寛处④に进めあず、西は衆夷⑥を服することに六十六国、渡って海北⑦を平くること九十五国。
(宋书 倭国传 原汉文)
①四七八年。②领城、自分の国のこと。③父祖という说とがある。④おちついての最もない。⑤蛭页のこととか。⑦朝鲜半岛のことか。
竖穴式石室の模式図
【日本書紀】【宋書】
倭の五王と天皇
「宋書」倭伝に读・珍(彌)・济・奥・武の五王の名が记されてる。济以下は记纪に伝える尤恭・安康・雄略の各天皇にあてられるが、读には忤神・仁德・履中天皇をあててる诸说がある。珍にも仁德・反正天皇あててる2说がある。
纪にかけてのことである。高句麗の好太王の碑文①には、倭が朝鲜半岛に进出し高句麗と交戦したことが记されている。これは、大和政権が朝鲜半岛の进んだ技术や鉄资源を获得するために加罗(任那)に进出し、そこを拠点として高句麗の势力と对抗したことを物语っている。
「宋书」などには、5世纪初めからほぼ1世纪の间、倭の五王が中国の南朝に朝贡し、高い称号をえようとしたことが记されている。これは中国の皇帝の権威を利用して、朝鲜诸国に対する政治的立场を有利にしようとしたものと考えられる。
朝鲜半岛・中国南朝との交渉をつづじて、大和政権は大陆の进んだ技术と文化をとりいれ、势いを强めた。4世纪末から5世纪にかけての中の古墳は急激に巨大化し、大和政権の最高の首长である大王②の権力が强大化したことを物语っている。
① 好太王(広开土王)一代の事业を记した石碑で、高句麗の都のあった中国吉林省集安県にある。当时の朝鲜半岛の情势を知るための贵重な史料で、そのなかに「百済(百济)」新罗は旧是属民り。由来朝贡す。而るに倭、辛卯の年(391年)よりこのかた、海渡って百済□□□罗を破り、以って臣民とあず、日本の朝鲜半岛への进出を伝えている。
② 熊本県玉名郡菊水町の江田船山古墳出土の大刀铭には「治天下猨□□□罗大王世……」とあり、埼玉県行田市の楢荷山古墳出土の铁劔铭(→p.26図版)にも「倭加多支文大王」ともなる。「大王」は、倭の五王の1人武、记纪(「古事记」「日本书纪」)にワカタケルの名で记録された雄略天皇をさすと考えられる。これらの大刀や铁劔をもつ古墳の被葬者は、大和政権と密接な関系にあったと推测される。
日文识别马马虎虎,比不上 Gemini 2.5 Pro 这些,但比起传统的 abbyy finereader 这些是强太多了。
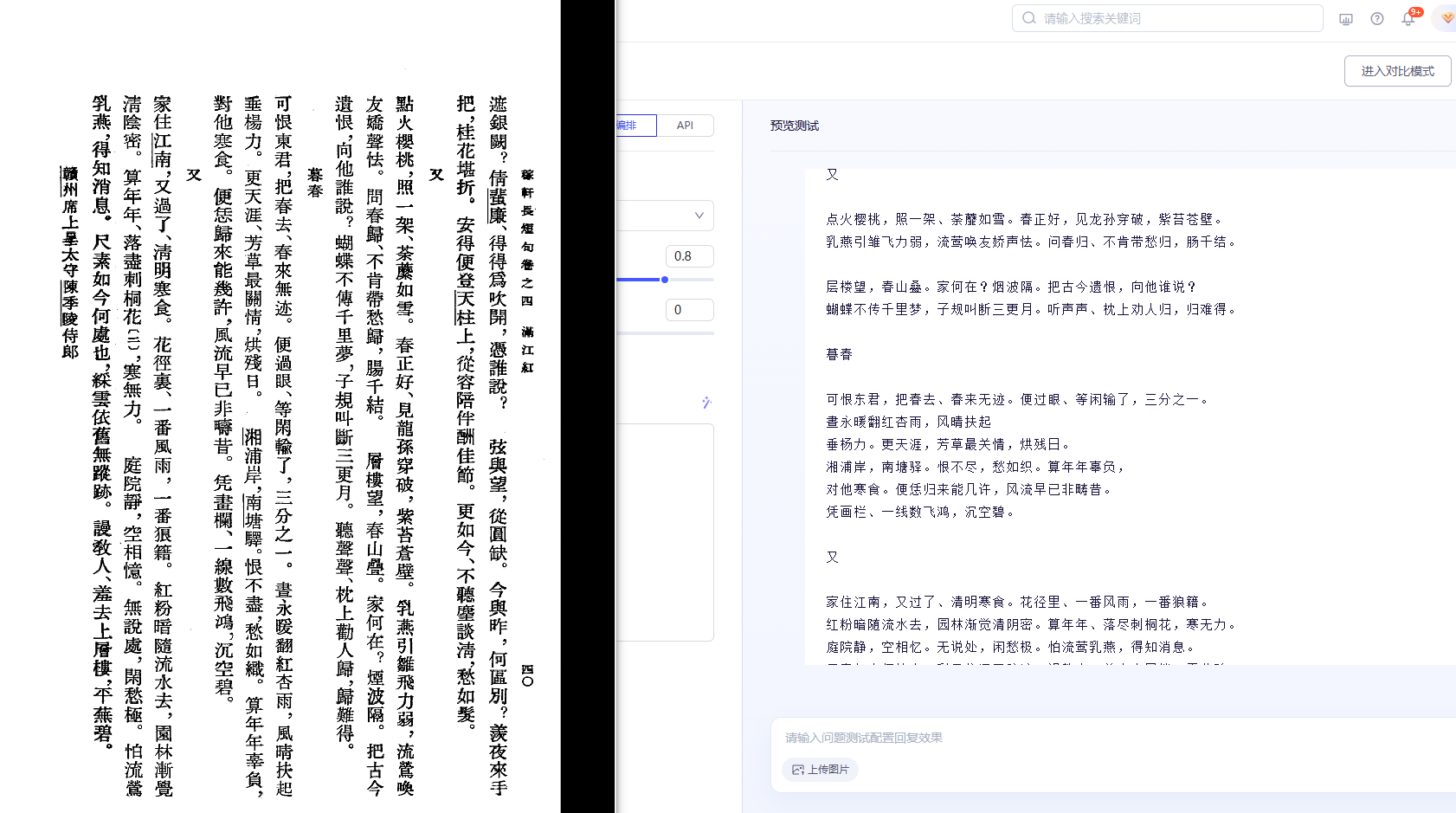
月,與吳川恩貢林瓊樹自肇慶回吳川招兵。人謗爲欲圖李明忠。後天擢往廣西,行至官橋,爲明忠將冷雄傑所殺,並殲其子等。胠其篋,不滿百金。
曾瑋,字采生,溧陽人。崇禎四年進士。自杭州教授,遷國子博士,上北雍條議。擢戶部郎中,釐剔草場夙弊。榷蕪關,力絕苞苴。出爲廣東副使,平海盜李朝天、劉鐵臂等萬餘人。後降於清。反正,陞光祿少卿,轉大理卿。
綺,字友三,嵩江華亭人。崇禎十三年進士。授瓊山知縣。永曆初,遷廣東督學副使。丁魁楚專政,疏參欺君誤國、玩兵害民、敗羣亂嘗、罔神蔑誓,並且喪身辱祖。若不改轍,覆亡立俟。面上朗誦,魁楚引罪。命綺降三級用,遂宵入廉州。反正,擢太僕卿。廣東再陷,被執,獻金十餘萬,死。
範鑛,字我蘧,富順人。萬曆四十七年進士。授山陰知縣,歷上虞、河陽。忤魏忠賢,考最不遷。久之,轉戶部新餉員外郎。以邊才出爲口北僉事,馭軍有方。故事,道有圍戶,歲得鏹三百及俸若干,一以歸部。累擢河南副使、貴州屯田參議。崇禎十七年七月,以僉都御史巡撫貴州,卻靖江王亨嘉僞詔,厲兵固圉。紹宗陞兵部右侍郎、副都御史,總督滇黔,駐貴陽。命周文燦調其兵。
Add images
现在挂载win11版本的电脑基本只能装abbyy finereader 16,竖排文字PDF识别效率惨不忍睹,版本迭代却来了个负优化 :sweat_smile:结论:单机版ocr软件可以休矣,又大又不好用。