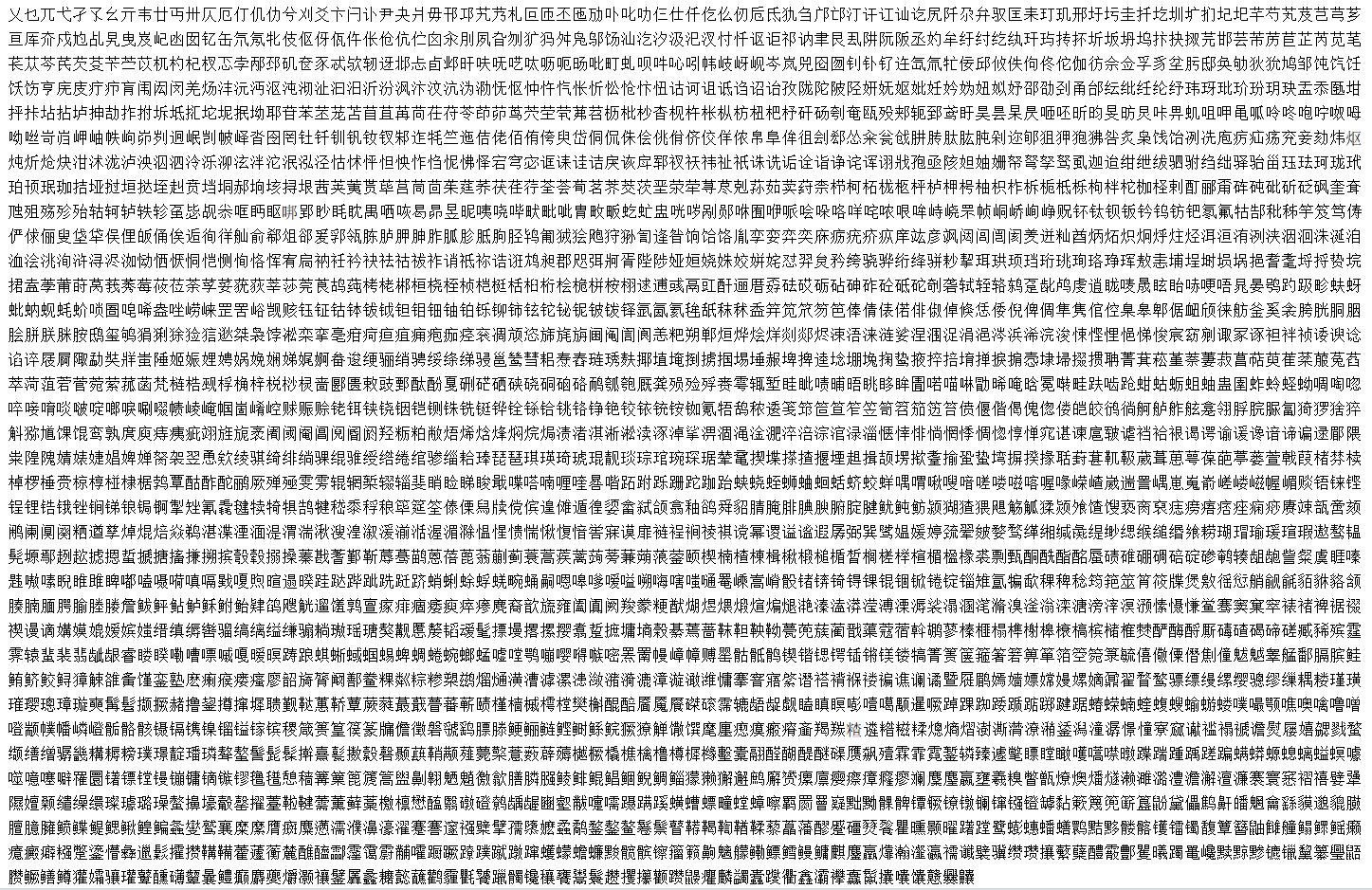目前这样的测试量少、难度普通、缺乏多样性,导致最终的结果区分度不大,比如百度、夸克、合合、有道、火山的OCR能力真的高度近似吗?
我提供几个可供测试的样本,涵盖复杂格式、模糊、生僻字等情况,还可以考虑繁体竖排、中英文混合等。