账号异常可能会被封掉的,未必能一直两秒一次。
即使不封,一直出数学题,也无法不停顿。
不知道有部首列单字的检索方法吗?
即使只能把所有单字弄出来,也有参考价值。
账号异常可能会被封掉的,未必能一直两秒一次。
即使不封,一直出数学题,也无法不停顿。
不知道有部首列单字的检索方法吗?
即使只能把所有单字弄出来,也有参考价值。
这次改订版质量有了很大突破,就是字体、版式错综复杂,爬取的时候也要费点功夫。粗粗对照了几条,相对于市面上同行的mdx版汉大词条准确度、完整度都更高。还有一点进步之处是它完全准照纸书的义项序号,当义项的意义如果有引申义、比喻义、借代义则错行另出。而不是像基于光盘版拷录的mdx版本一律重新标定义项序号,造成伦次混乱,让人难以把握义项间的子母、旁推的衍化关系
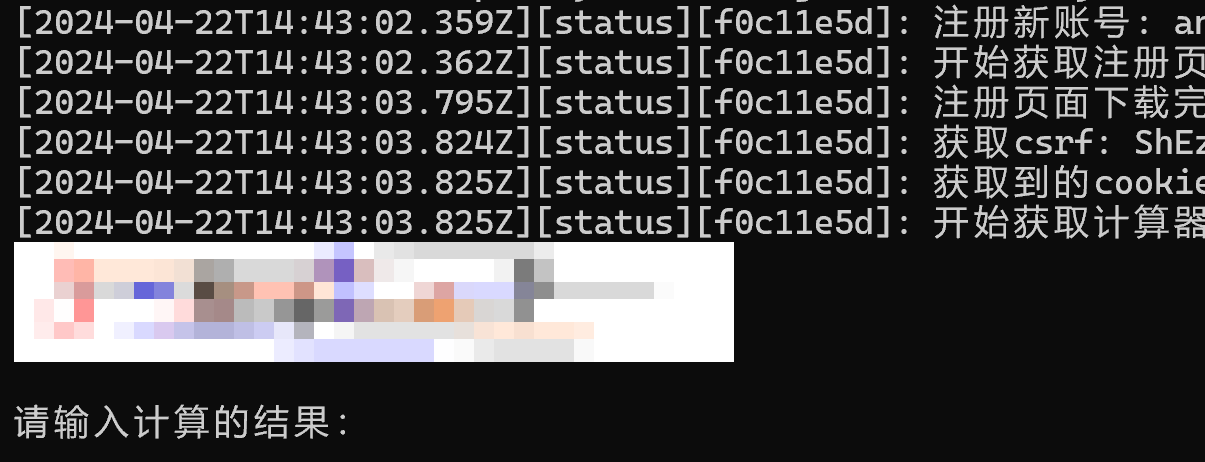
现在不让试用了,只能付费访问。更新了一点没什么用的功能,账号自动注册,邮箱自动验证,验证码自动抓取,本来想自己训练验证码识别的,填了 100 多条放弃了,至少需要 1000 条才能开始。
hanyucidian.org.zip (19.8 KB)
应该还能试用,服务器除检测访问间隔时间外,可能还检测单位时间访问总量以及IP地址。刚才我换了个地址又试了一小会儿。
这种题大概叫“爬虫终结者”?
我猜测是:埋伏在那里,看是否有人训练验证码了做识别?
这种题是无法训练的题,就是必杀题,一定要你停止就对了。
假如这种题还不停地答,就可以判断是用了自动回答的爬虫程式,接下来大概就锁账号了。
应该是 Windows 终端的问题,简单改进了下,现在会直接在本地目录生成:captcha.png 文件。使用图片浏览器打开,应该可以自行更新。
这里的提示文本没有修正,使用的时候需要输入完整的计算过程(3+3-9=-3)。
hanyucidian.org.zip (19.8 KB)
我刚刚试用第2次,果然要我注册。
换个浏览器,看是否是查cookie。不是,还是要我注册。
想到我刚下载了Oscar 浏览器,有内置的VPN(网上说,这种VPN在大陆无法用)。正好试用。
试了一下,好慢啊,不过真能用,没要求我注册。
验证了三条。
1.【不𦢌】不顺服。亦指不顺服者。
【不譓】不顺服。亦指不顺服者。
〖校记〗“𦢌”(U+2688C):胎儿夭折。“不𦢌”同“不殰”,其解释当同“不殰”,言“胎不坏死”。此处解为“不顺服。亦指不顺服者”,与下条“不譓”(同“不憓”)之解释相同,必手民之误。
在第一册,改了。
2.DCD120739缺词:髲𩭝 (U+9AF2 U+29B5D)
这个新版没缺,词条完整。
3.「老悖」例句:‘種師道真是老悖無能!
“種師道”當作 “种師道”。
这个没改。也许校改者没发现,或者还没改到第16册?
也就查了三条就不能查了。
大概只能这样,偶尔查两三条。
通知整理过《汉语大词典》的高人共同研究。
是的换个 IP 又可以访问了。
我已经订阅了一年的,愿意抓取者可私信联系。
我没时间搞,愿意抓取的赶紧联系楼上的啊。
多谢!
楼上的大侠不搞,那就我来吧。
准备天天挂着慢慢搞,间隔时间再设为随机数,以免被封号。
我个人觉得,可能可以考虑这样的顺序:
1.先把所有词头弄出来。
2.把词头和旧的词头对比,列出新增字表、词表。
3.把新词表的词条先抓出来。
4.把所有单字的资料抓出来。
5.剩下的词,先弄已经整理完出版的新册。
6.最后才弄已知还未整理完的册。
按照这样的优先级别进行,万一项目中断,至少最重要的部分有一部分能做完。
有样板的几个 HTML 页面+css + js 资源吗,解剖下麻雀,可以提前交流下后续的数据清理、样式梳理。
网站已经对文本做了提取,抓到的都是结构化的数据(JSON),不存在清洗问题。
Json能解开吗?有没有加密?
私用区字免不了,还有图像字,也许还有代表缺字的黑块。
这些东西假如多了,也很难清理。
明文的。你可以查几个字,用浏览器的开发者工具点开网络面板就可以看到所有和网站通信的记录。
今天正式开工,设定每次访问间隔为5到8,第一次访问二三十页被远程终止,后又设为sleep(random.uniform(10, 20)),但几乎访问一页就要登录一次甚至两次。
访问记录:
ok
/dictionary/index?dictionaryCode=hydcdcx&categories=第1册&page=0
ok
/dictionary/index?dictionaryCode=hydcdcx&categories=第1册,一部&page=0
ok
/dictionary/index?dictionaryCode=hydcdcx&categories=第1册,一部&page=1
ok
/dictionary/index?dictionaryCode=hydcdcx&categories=第1册,一部,一&page=0
ok
ok
/dictionary/index?dictionaryCode=hydcdcx&categories=第1册,一部,一&page=1
ok
ok
/dictionary/index?dictionaryCode=hydcdcx&categories=第1册,一部,一&page=2
ok
ok
ok
ok
其中ok是登录标志。现在干脆一直尝试登录了。把代码发上来大神看一下如何修改吧。我写得很粗糙。
cdzhhydcd.py (4.2 KB)
你用浏览器正常访问会出现这种情况吗?
如果没有可以尝试无头浏览器,如果仍然出状况,那可能没救了。可能最近爬的人比较多,站方增加了访问限制,或者等段时间会恢复。
用的是无头浏览器,正常访问还行。因为登录时的数据有一个随机生成的字符串,只能考虑无头浏览器。